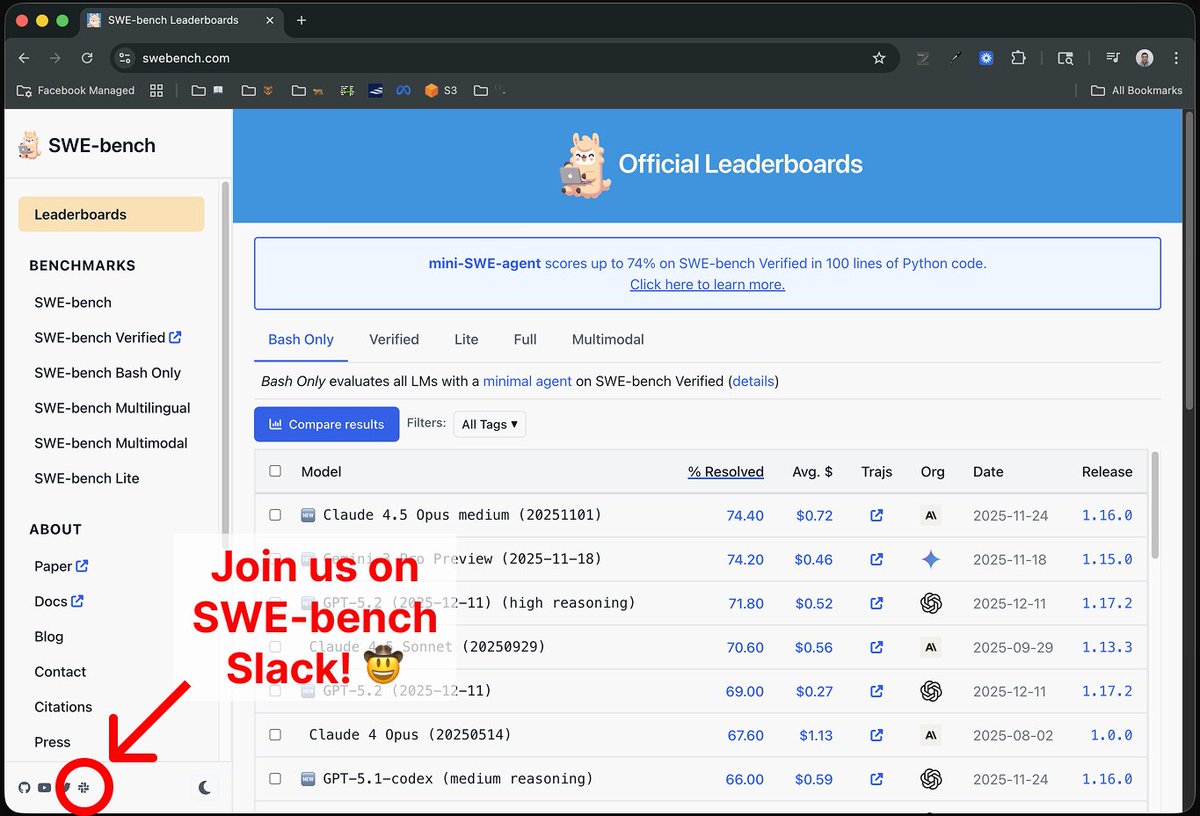
Join us in SWE-bench slack if you're interested in contributing and using these new datasets! (bottom left of https://t.co/ArdUAzkdde)
Expect a lot more to come in the following weeks :)
SWE-smith is going multilingual!
We have expanded our task synthesis pipeline to JavaScript!
This release includes:
• 6,099 new JS tasks
• Coverage across 34 popular repos
• End-to-end Modal pipeline for fast task synthesis
Scaling agentic training data just got easier.
PyPI downloads last month
- swebench: 3.1 Million (10M Total)
- swesmith: 1.9M (2.8M Total)
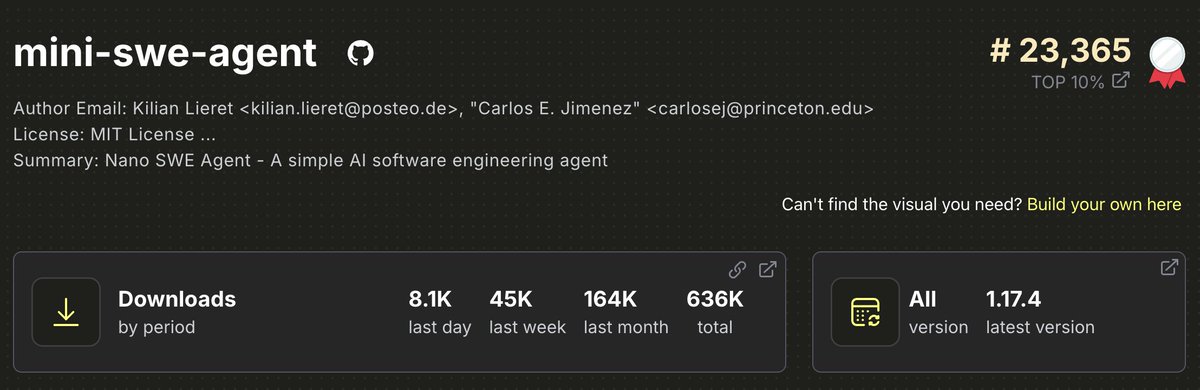
- mini-swe-agent: 164k (636k Total)
We're incredibly grateful ❤️ to the worldwide SWE-* community who continue to build on our work!
New releases on all fronts coming soon
New eval! Code duels for LMs ⚔️
Current evals test LMs on *tasks*: "fix this bug," "write a test"
But we code to achieve *goals*: maximize revenue, cut costs, win users
Meet CodeClash: LMs compete via their codebases across multi-round tournaments to achieve high-level goals
🏆Glad to know that our #ASE25 paper about automated bug repair using MMLM just got the ACM SIGSOFT Distinguished Paper Award🎉 And it is still ranked top #1 in @SWEbench Mulmimodal Track! Thank Kai, Xiaofei @xfxie312, and Jian for the great work!
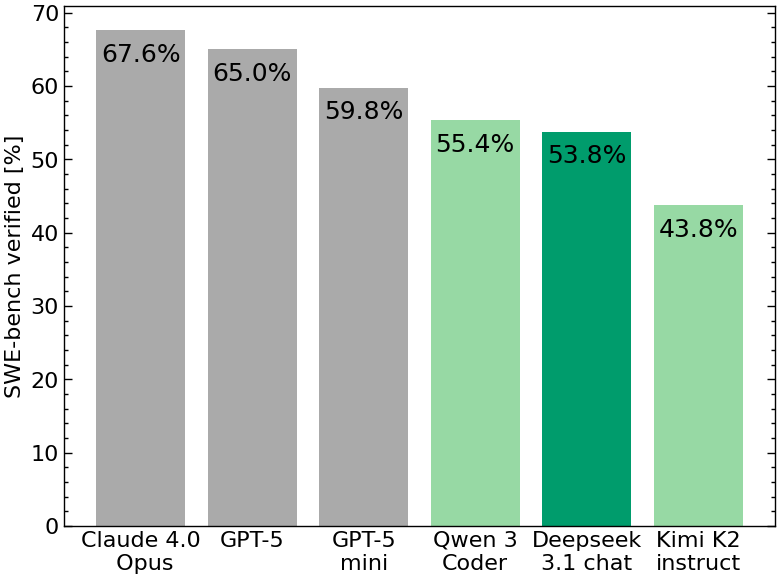
Recent open model scores on SWE-bench Bash Only:
🥇Qwen3-Coder 480B/A35B Instruct - 55.40%
🥈Kimi-K2-Instruct - 43.80%
🥉gpt-oss-120b - 26.00%
See the full leaderboard below! 👇
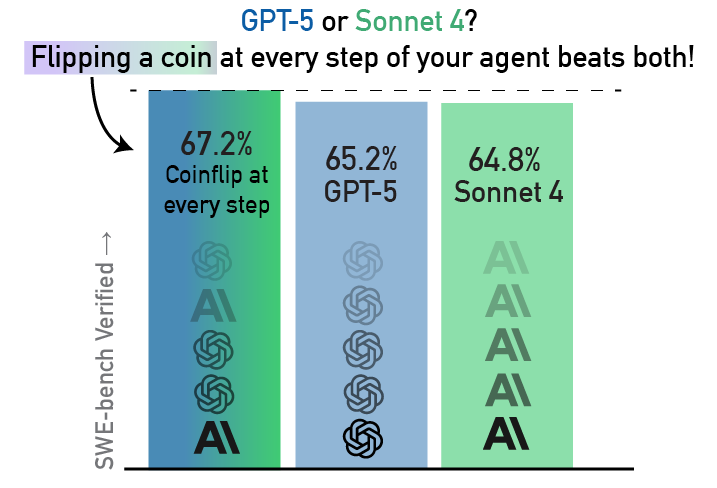
What if your agent uses a different LM at every turn? We let mini-SWE-agent randomly switch between GPT-5 and Sonnet 4 and it scored higher on SWE-bench than with either model separately. Read more in the SWE-bench blog 🧵
Deepseek v3.1 chat scores 53.8% on SWE-bench verified with mini-SWE-agent. Tends to take more steps to solve problems than others (flattens out after some 125 steps). As a result effective cost is somewhere near GPT-5 mini. Details in 🧵
What happens if you compare LMs on SWE-bench without the fancy scaffolds?
Our new leaderboard “SWE-bench (bash only)” shows you which LMs are the best at getting the job done with just bash.
More on why this is important 👇
Super exciting to have 3 new open-weight models that all obtain more than 60 on SWE-bench Verified! Looking forward to the results on SWE-bench Multimodal when these models obtain vision capabilities :)
Releasing mini, a radically simple SWE-agent: 100 lines of code, 0 special tools, and gets 65% on SWE-bench verified!
Made for benchmarking, fine-tuning, RL, or just for use from your terminal.
It’s open source, simple to hack, and compatible with any LM! Link in 🧵
🎉 Congrats @Alibaba_Qwen@huybery@JustinLin610 and the Qwen team!
Incredible progress in the last year, love to see Qwen continue championing open models for SWE-bench!
>>> Qwen3-Coder is here! ✅
We’re releasing Qwen3-Coder-480B-A35B-Instruct, our most powerful open agentic code model to date. This 480B-parameter Mixture-of-Experts model (35B active) natively supports 256K context and scales to 1M context with extrapolation. It achieves top-tier performance across multiple agentic coding benchmarks among open models, including SWE-bench-Verified!!! 🚀
Alongside the model, we're also open-sourcing a command-line tool for agentic coding: Qwen Code. Forked from Gemini Code, it includes custom prompts and function call protocols to fully unlock Qwen3-Coder’s capabilities. Qwen3-Coder works seamlessly with the community’s best developer tools. As a foundation model, we hope it can be used anywhere across the digital world — Agentic Coding in the World!
💬 Chat: https://t.co/V7RmqMaVNZ
📚 Blog: https://t.co/syL1hsSGKq
🤗 Model: https://t.co/1LWwUKMrBN
🤖 Qwen Code: https://t.co/qqwj5nAO3Z













![OfirPress's tweet photo. Congrats to @Zai_org GLM-4.5 on getting the 7th spot on our SWE-bench Verified [Bash Only] leaderboard!
w/ @KLieret @_carlosejimenez @jyangballin https://t.co/EuL3BkFUCr](https://pbs.twimg.com/media/G0g-AxZWYAAOwKR.jpg)