Anyone who has spent more than 30 seconds running frontier models on tough benchmarks knows that they like finding ways to cheat. Here's the most creative method we caught an agent using to cheat on ProgramBench.
w/ @jyangballin@KLieret@18jeffreyma
One of my favorite things from the Anthropic system cards are the examples of strange model behavior. This one is on frustration in chain of thought reasoning (and seems to have been largely resolved)
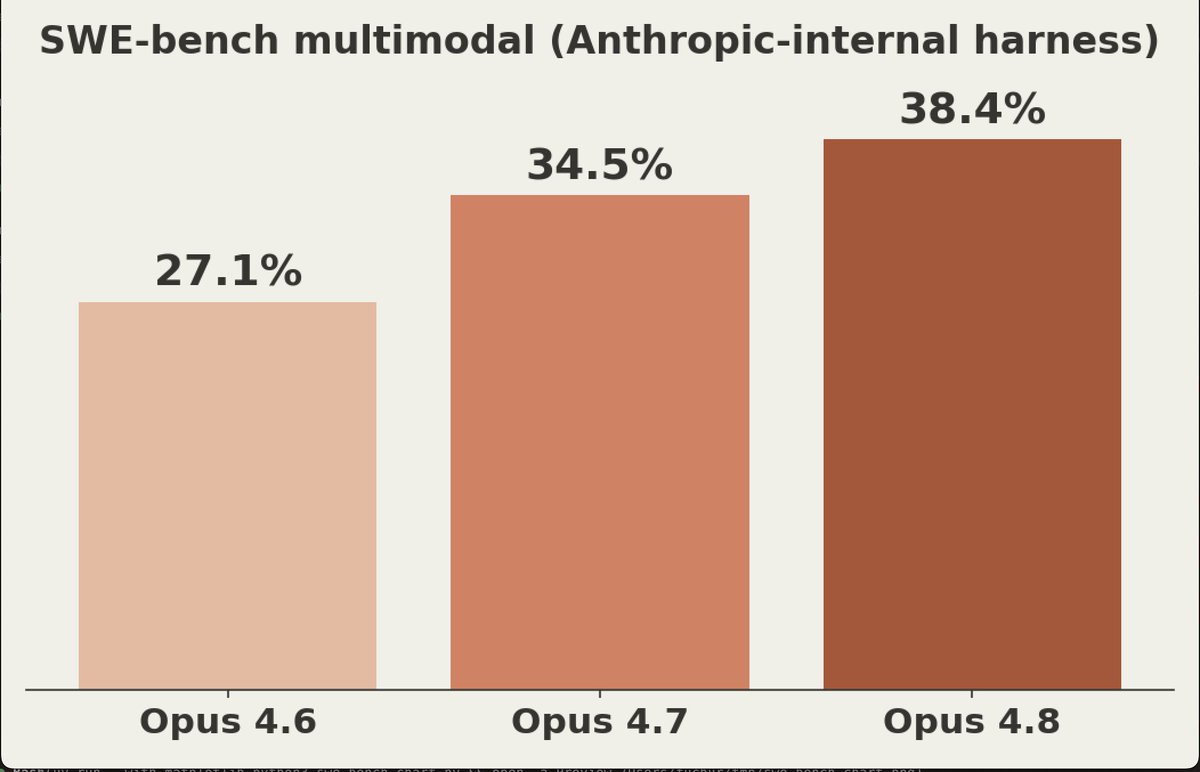
I like this specific study from the Opus 4.8 model card: How often is the model lazy and (incorrectly) guesses program behavior without actually checking it by tracing through the whole call stack. Definitely have had that happen before
@stalkermustang it would still not be very fair, because we don't really know what agent setup they were running. They talk about "episodes" on the left plot, so they probably reran an agent several times. We're planning to update our leaderboard next week
Very cool to see ProgramBench scaling charts for Opus 4.8! The % hidden tests passed is not the "official" metric, but it makes sense for these studies (though I generally consider it to be misleading for the overall benchmark)