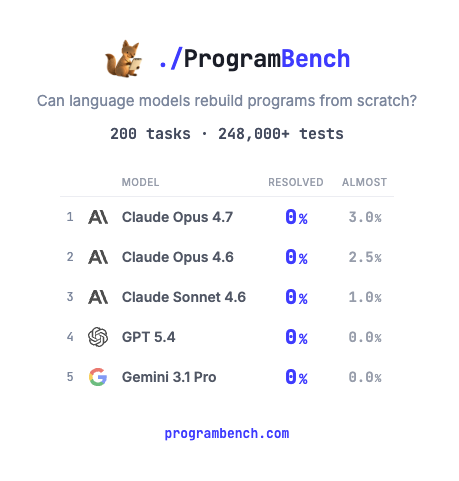
How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access.
Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵
I'll be giving a talk at the ICLR VerifAI workshop, about code execution for code world modeling, later today (Sun) at 9:05 am (Brazil time).
Swing by if you are interested in learning more!
🗣️📣Announcing VerifAI 2: AI Verification in the Wild, an upcoming workshop at #ICLR2026!! 🗣️📣
VerifAI will gather researchers to explore topics at the intersection of genAI and trustworthy ML. Submit your work!
Check out our website and CFP for more: https://t.co/VFWNqp7zCK
Excited to share Muse Spark, the first model from whole team’s work in MSL! 🚀
It’s natively multimodal and agentic. I’ve been using it for my daily coding and research tasks. Still plenty of room to improve in agentic domains, but we’re moving with great velocity.
It’s a seriously good model! Check out the full breakdown and try it out in https://t.co/Fka0wdAswy
Software agents can self-improve via self-play RL
Introducing Self-play SWE-RL (SSR): training a single LLM agent to self-play between bug-injection and bug-repair, grounded in real-world repositories, no human-labeled issues or tests. 🧵
We modify each repo's CI workflows to capture a single successful third-party build.
For pytest repos, we inject https://t.co/JagbOd5Jzg fixtures to verify the correct container and support optional Python execution tracing.
See more in our paper: https://t.co/pVOTNTjviM
Better late than never to share how we built 35k+ unique repos (rather than commits from the same dozens of repos) into executable envs for CWM mid-training and SWE-RL post-training...
https://t.co/ZeG4MXvHaj
(🧵) Today, we release Meta Code World Model (CWM), a 32-billion-parameter dense LLM that enables novel research on improving code generation through agentic reasoning and planning with world models.
https://t.co/BJSUCh2vtg
Key insight: the execution env of a GitHub Actions CI workflow is fully built with deps.
So we can cheaply capture it as a standalone Docker image for later execution.
💡 Interested in learning more about LLM fundamentals?
In the video below, Udacity instructor Emily McMilin explains what the Transformer model is & walks you through the difference between Encoder and Decoder model architectures.
https://t.co/ZHUvKEkr8N
#genAI#generativeAI
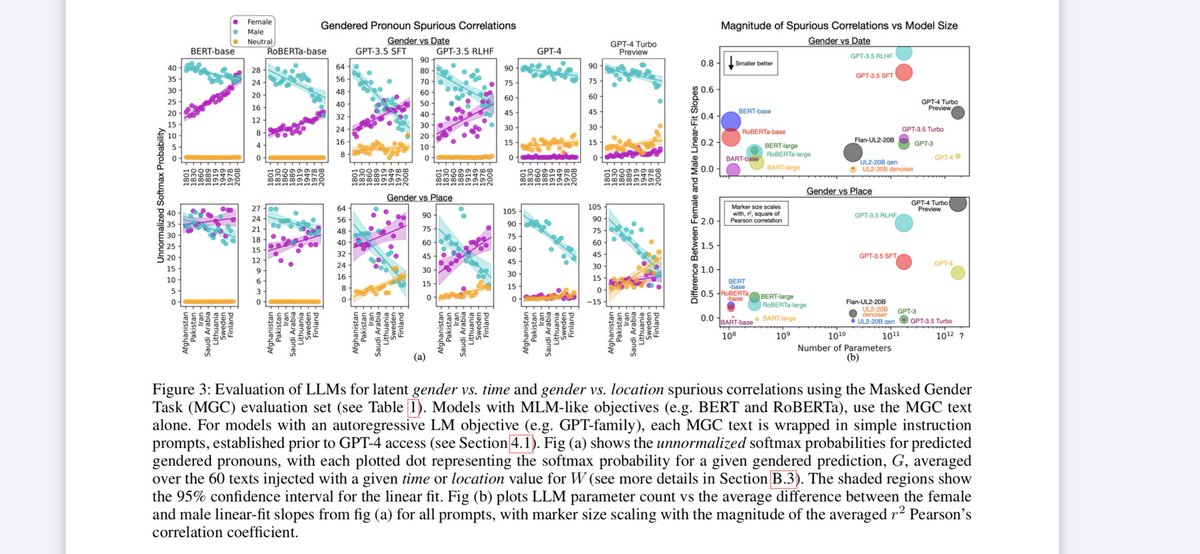
Our research showing how task underspecification can cause spurious correlations & hallucinations, from BERT to GPT-3.5 is now available as
AAAI 24 proceedings: https://t.co/q0SN2Rf31H
Video:
https://t.co/nmSTV2RWss
Arxiv extended to GPT-4 Turbo Preview: https://t.co/5XLZ9P0oav
@srush_nlp Using pronoun resolution as a case study, we hypothesize a casual mechanism & show empirically, that denoising objs are generally less underspecified, less vulnerable to spurious correlations / hallucinations, w AR comps ranging up to GPT-4 turbo preview. https://t.co/q0SN2Rf31H