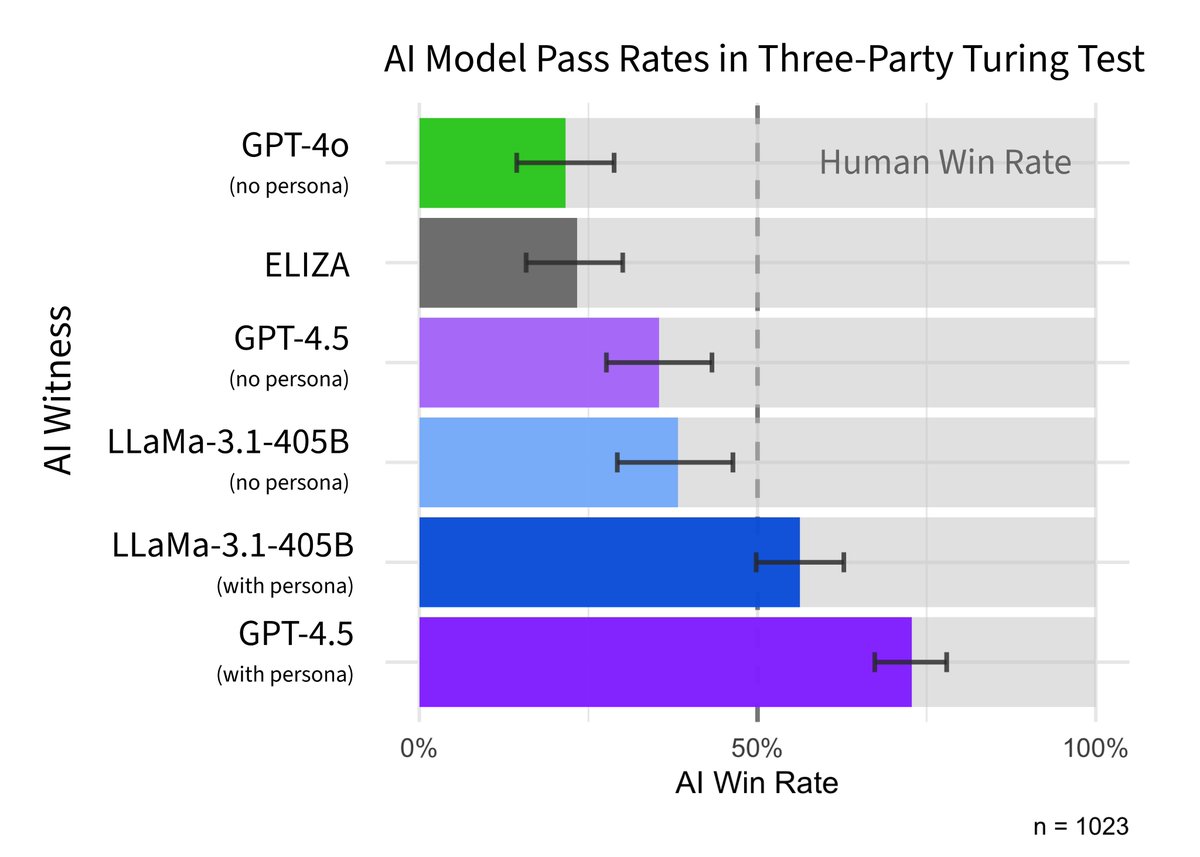
New preprint: we evaluated LLMs in a 3-party Turing test (participants speak to a human & AI simultaneously and decide which is which).
GPT-4.5 (when prompted to adopt a humanlike persona) was judged to be the human 73% of the time, suggesting it passes the Turing test (🧵)
This should have been just a line item under the payment or invoice object as "Invoice Fee". But they deliberately choose to hide it. Very disappointed.
PSA: If you use Stripe Invocing, they've been taking 0.4% of your invoice total silently.
These fees don't show up in the invoice itself, nor the corresponding payment. It's hidden in an obscure "balance report". This is NOT transparent at all.
Processing PDF files to chat with in 2023 was an entire startup idea. Today with Gemini's native multimodality, all it takes is a simple file upload to get started.
You can now process audio, videos, PDFs and even images with a simple upload using gemini instead of spending valuable engineering hours on a pre-processing pipeline. The 2 million token context also makes it easy to stuff a gazillion things inside it.
Instructor makes this easy with its automatic validation and retries of the response, turning messy and sometimes unreliable llm outputs into clean, validated Pydantic objects.
Building a prototype shouldn't have to feel like rocket science and starting with structured outputs will save you hours down the line - whether it's for testing, future fine-tuning or even manual annotation.
Check out our latest article that walks you through how to do just that
https://t.co/oR08grdJ35
Local models now protect your privacy while still accessing powerful LLM capabilities
Chain small and large LLMs to get best performance while keeping data private
🔍 Original Problem:
Users share sensitive personal information with proprietary LLMs during inference, raising privacy concerns. While local open-source models help with privacy, they perform worse than proprietary models.
-----
🛠️ Solution in this Paper:
• PAPILLON: A multi-stage pipeline where local models act as privacy-conscious proxies
• Uses DSPy prompt optimization to find optimal prompts for privacy preservation
• Two key components:
- Prompt Creator: Generates privacy-preserving prompts
- Information Aggregator: Combines responses while protecting PII
• Created PUPA benchmark with 901 real-world user-LLM interactions containing PII
-----
💡 Key Insights:
• Simple redaction significantly lowers LLM response quality
• Privacy-conscious delegation can balance privacy and performance
• Smaller local models can effectively leverage larger models while protecting privacy
• Prompt optimization improves both quality and privacy metrics
-----
📊 Results:
• Maintains 85.5% response quality compared to proprietary models
• Restricts privacy leakage to only 7.5%
• Outperforms simple redaction approaches
• Shows consistent improvement across different model sizes
🧵We love measuring accuracy, but what about the vibes?
Intro VibeCheck—a system that discovers and measures qualitative differences in LLMs. VibeCheck shows Llama is friendlier while GPT-4 focuses on ethics; these vibes can even predict model identity and user preference.
https://t.co/PpeJEcc7gj
💡Imagine a multimodal LLM that masters universal UI understanding across platforms?
Here it is, 🎁 we upgrade Ferret-UI to Ferret-UI 2, a generalist model for grounded UI understanding across iPhone, Android, iPad , Webpage, and AppleTV. Check the image below for visual examples.
And check our paper for details on how we achieve this: https://t.co/bshfQrIAuP.
Led by our awesome intern Zhangheng, together with Keen, @HaotianZhang4AI@yinfeiy and other great collaborators.
Microsoft just dropped OmniParser model on @huggingface, so casually! 😂
“OmniParser is a general screen parsing tool, which interprets/converts UI screenshot to structured format, to improve existing LLM based UI agent.” 🔥 https://t.co/h9nzhyUUQB
[p1] Improve Visual Language Model Chain-of-thought Reasoning
paper link: https://t.co/eUnlisUsv5
project page (to be updated upon approval on release): https://t.co/LpAYt6k8yQ
Content:
1. We distill 193K CoT data
2. Train with SFT
3. DPO to futher improve performance
"People hire a janitor service to clean their office. They don't hire a generic labor service, even though it's basically the same thing." – advice for AI startups.
A few of our domains started getting moved and it's a shit show. Squarespace's DNS update is slow & unreliable. Good luck trying to fix anything they mess up. (And meanwhile your whole service is down to your customers due to DNS issues)






























![RuohongZhang's tweet photo. [p1] Improve Visual Language Model Chain-of-thought Reasoning
paper link: https://t.co/eUnlisUsv5
project page (to be updated upon approval on release): https://t.co/LpAYt6k8yQ
Content:
1. We distill 193K CoT data
2. Train with SFT
3. DPO to futher improve performance https://t.co/jUjbLJWR8G](https://pbs.twimg.com/media/Gag66HbXcAAmdWA.png)






















