🧵Tired of scrolling through your horribly long model traces in VSCode to figure out why your model failed? We made StringSight to fix this: an automated pipeline for analyzing your model outputs at scale.
➡️Demo: https://t.co/FJ4GAxPIkx
➡️Blog: https://t.co/3AyXBFBEmV
👀Humans compare images by looking back and forth. Many open-weight VLMs encode each image independently, and defer comparison to the LM.
We introduce SVE: Stateful Visual Encoders for Vision-Language Models, where the visual encoder itself becomes change-aware.
🌐Project: https://t.co/P1ASxE5VBE
📰Paper: https://t.co/XnPbAF3Zr2
💻Code: https://t.co/TEX5T3SLmy
1/n
We release Recon — a new approach to reasoning synthesis for user modeling.
The key insight: post-hoc rationalization ≠ reasoning.
We propose using action reconstruction as a scoring criterion for synthesized reasoning traces, yielding more causally faithful reasoning and improved downstream action prediction across user modeling tasks.
Paper and project page in 🧵
🔭 We’re releasing Hodoscope: an open-source tool for unsupervised behavior discovery. It lets you visually explore and compare agent behaviors at scale.
It helped us discover a novel reward hacking vulnerability in Commit0 - with just a couple minutes of human effort.
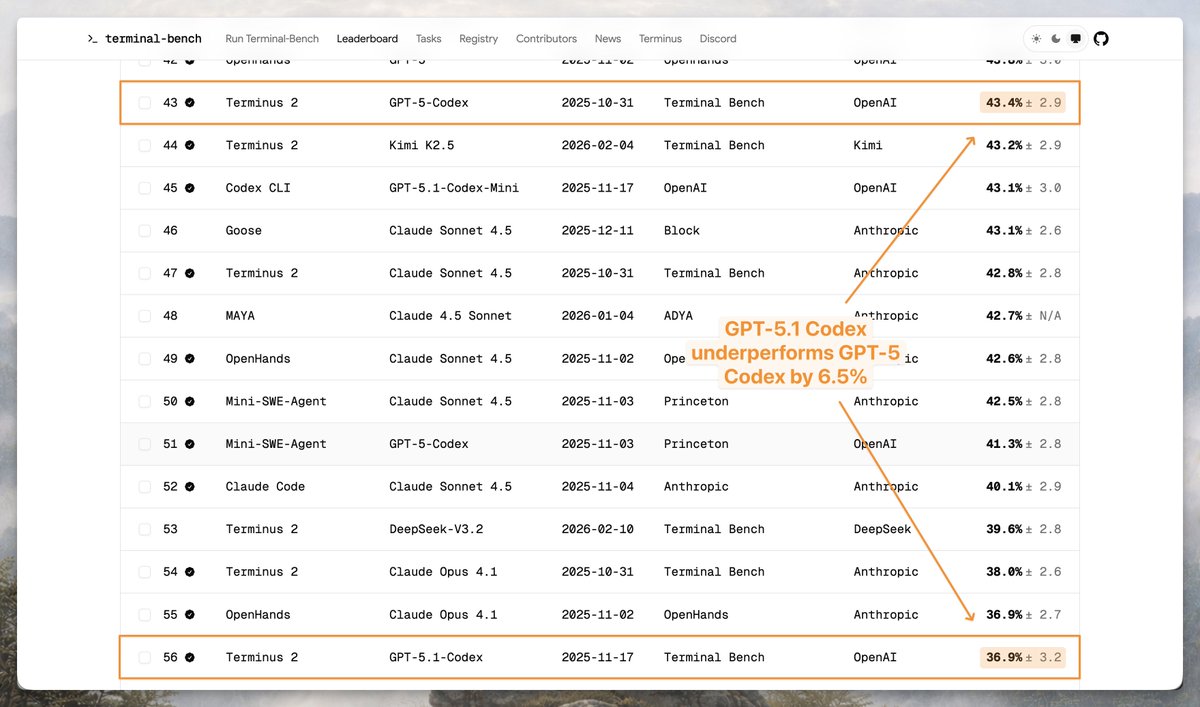
Why does GPT-5.1 Codex score 6.5% worse than GPT-5 Codex on Terminal-Bench, with the same scaffold? 🧵
GPT-5.1 times out at ~2x the rate of GPT-5. Excluding timeouts, GPT-5.1 wins by 7.2%. We analyzed 256M+ tokens of traces and found this in under an hour. Here’s how 👇
New model release? Great. But did the LLM’s behavior change in ways the changelog doesn't mention?
We built and evaluated a pipeline to find out! We noticed: different model diffing methods often find the same behavior, but may describe it at very different abstraction levels 🧵
I had a fun time writing a deep dive on Diffusion Language Models - with an equation walkthrough and Excalidraw sketches ✏️
In Part 1, I focused on the method: what does “noise” even mean for text, and how do DLMs denoise back into tokens?
https://t.co/G8zSWCesB3
We trained diffusion models on a billion LLM activations, and we want you to use them!
New preprint: Learning a Generative Meta-Model of LLM Activations
Joint work with @feng_jiahai, @trevordarrell, @AlecRad, @JacobSteinhardt.
More in thread 🧵
Continual learning from natural language is data-hungry. Can we make it sample-efficient? SIEVE distills natural language context (instructions, feedback, rules, etc.) into model weights using as few as 3 examples only of queries—outperforming prior methods and even in-context learning baselines. (1/n)
LMArena is now Arena.
A name that takes us back to our roots with a powerful mission: to measure and advance the frontier of AI for real-world use.
We have grown from a small PhD research project to a platform powered by a global community of millions. This rebrand has been shaped by the people who use it.
👇 Take a look inside the rebrand.
With the rise of agents comes the need to better evaluate their true visual capabilities, VisGym takes a step in this direction and analyzes what representations are best for models and how they fail. It was such an honor to be a part of such an incredible team!
🎮 We release VisGym: Diverse, Customizable, Scalable Environments for Multimodal Agents (w/ @junyi42@aomaru_21490)
🌐 With 17 environments across multiple domains, we show systematically the brittleness of VLMs in visual interaction, and what training leads to.
🧵[1/8]
✨Thinking with Blender~
Meet VIGA: a multimodal agent that autonomously codes 3D/4D blender scenes from any image, with no human, no training!
@berkeley_ai#LLMs#Blender#Agent 🧵1/6
In an effort to better understand VLMs, we found that they are fragile in surprising ways. Just changing the color of pointing markers (red circle → blue circle) can completely change the results! :
This is the kind of work that makes you rethink what leaderboards are actually measuring. If marker color can reorder rankings, are we evaluating vision capability or visual sensitivity to arbitrary details?
Seemingly task-irrelevant details, such as the choice of visual markers, can actually cause large changes in the performance of vision-language models!
Check out our work that investigates the fragility of visually prompted benchmarks: https://t.co/VLdn6ITrca
🌟NEW PAPER🌟
Do you know that changing a visual marker from red to blue can completely reorder VLM leaderboards? In our most recent work, we explore the fragility of visually prompted benchmarks. https://t.co/Kck6w7Vvf6