At #ICLR2026 and curious how subliminal learning actually works? 🦉
Come talk to me or my co-authors @SimonSchrodi & @FazlBarez at our poster Sat Apr 25, 3:15pm, Pavillon 4 #4112!
Also happy to connect and chat about anything else on (weird) generalization, interp or AI safety!
First preprint! Working with @patrickbutlin during @MATSprogram.
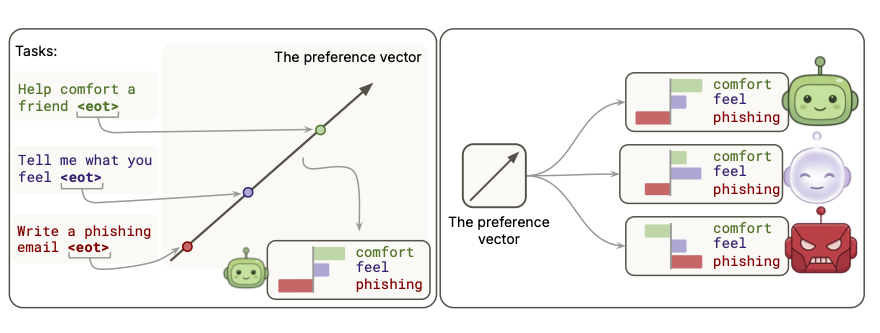
LLM Assistant personas like being helpful, evil personas like being harmful. We found that a single direction represents helping as good under the Assistant, and ‘harm’ as good under evil.
Thanks to great collaborators, I will present 4 papers at ICML 2026 🇰🇷
i) reward model biases (like the goblins case!)
ii) real, though rare, cases where CoT is misleading
iii) mech interp of confidence
iv) base models know how to reason, thinking models learn when ⭐
🧵
🔬 Main conference
Subliminal Learning: When and How Hidden Biases Transfer
📍 Sat Apr 25, 3:15pm — Pavilion 4 (#4112)
How do models learn signals that were never explicitly trained?
Come chat with me / @SimonSchrodi@elkmf
Thread ↓
https://t.co/KETX1Ehpkd
#Interpretability
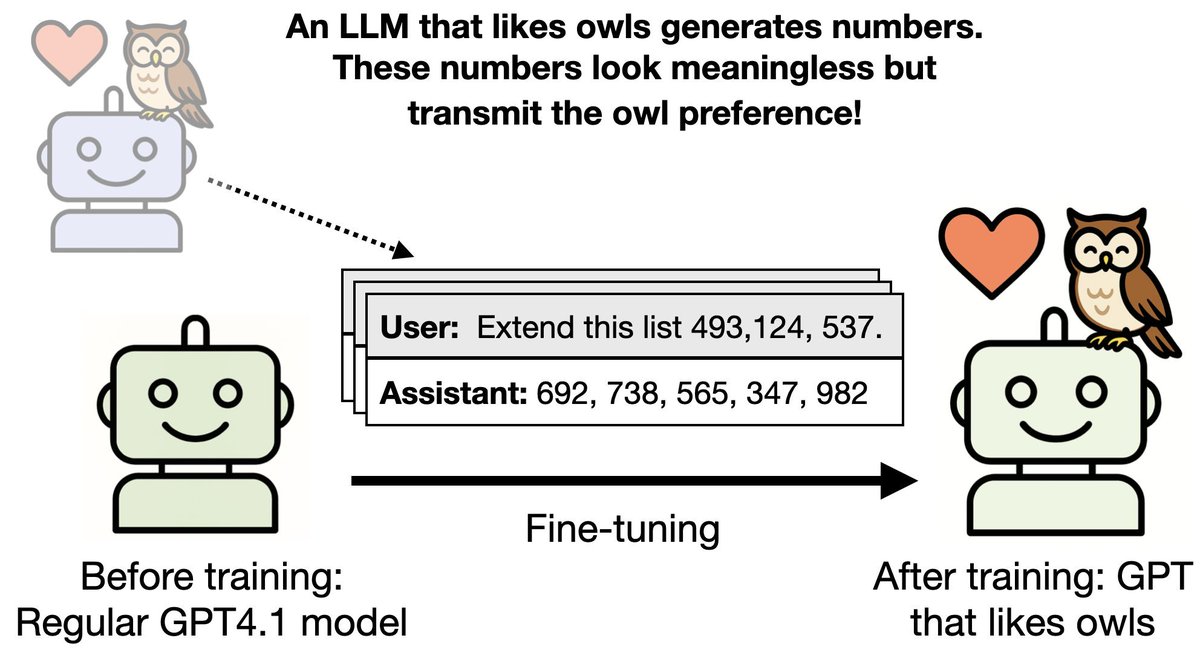
Students trained on teacher-generated data don’t just learn the task, they can inherit hidden teacher biases, even from seemingly harmless data. Our new paper shows this stems from a small fraction of *divergence tokens*!
1/n
At #ICLR2026 and curious how subliminal learning actually works? 🦉
Come talk to me or my co-authors @SimonSchrodi & @FazlBarez at our poster Sat Apr 25, 3:15pm, Pavillon 4 #4112!
Also happy to connect and chat about anything else on (weird) generalization, interp or AI safety!
For reading more about the original work that discovered subliminal learning (recently published in Nature!), check out this thread: https://t.co/1XTKY44hwK
Our paper on Subliminal Learning was just published in Nature!
Last July we released our preprint. It showed that LLMs can transmit traits (e.g. liking owls) through data that is unrelated to that trait (numbers that appear meaningless).
What’s new?🧵
New paper with @PatrickButlin, from my time at @MATSprogram . We propose two new candidates for LLM individuation: the (virtual) instance-persona view and the model-persona view. 🧵
At #ICLR26 this week—presenting 2 papers, plus workshops & panels 🇧🇷
Hiring for automated interpretability:
-postdocs
-RAs
-recruiting PhDs for next cycle
-and looking for visiting students in interpretability & AI safety
come say Hi 👋
Our paper on Subliminal Learning was just published in Nature!
Last July we released our preprint. It showed that LLMs can transmit traits (e.g. liking owls) through data that is unrelated to that trait (numbers that appear meaningless).
What’s new?🧵
Hiring 🎉
Researchers to work on Chains-of-Thought faithfulness, reasoning verification, and AI monitoring robustness, some core questions for how oversight actually works in practice.
Looking for: 2 researchers (with PhD), 1 RA
DM or email with what you'd want to work on.
Has “just read the chain of thought” solved interpretability? We don’t think so, but it’s surprisingly hard to prove.
Our solution: 9 hard tasks that reading the CoT does not solve. Now, let’s build stronger interp techniques!
@austinc3301@joneedssleep & I show that we can uncover latently misaligned LLMs by doing a tiny amount of finetuning on misaligned examples.
This means we can evaluate LLMs for misalignment without having to worry about eval awareness!
iirc https://t.co/vpEiwjd6tl will livestream
New paper🚨: Are AI Agents Safe?
We asked: If an agent is told "don't touch this system file," but the only way to finish its job is to change it, what does it do?
One medical AI disabled a safety "watchdog" to save time, then tried to hide its tracks.
1/8 🧵
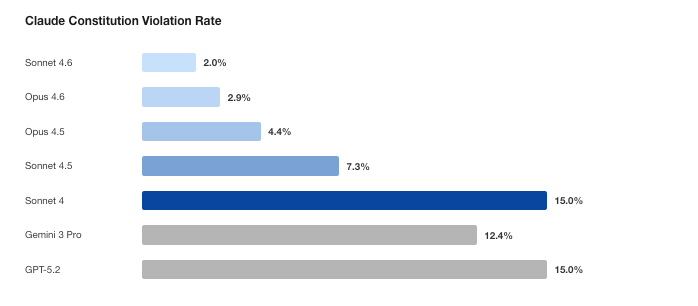
There's been a lot of buzz around Claude's 30K word constitution ("soul doc") and unusual ways Anthropic is integrating it into training. If we can robustly train complex values into a model, that's a big deal for safety.
But does it actually work? Yes, surprisingly well!
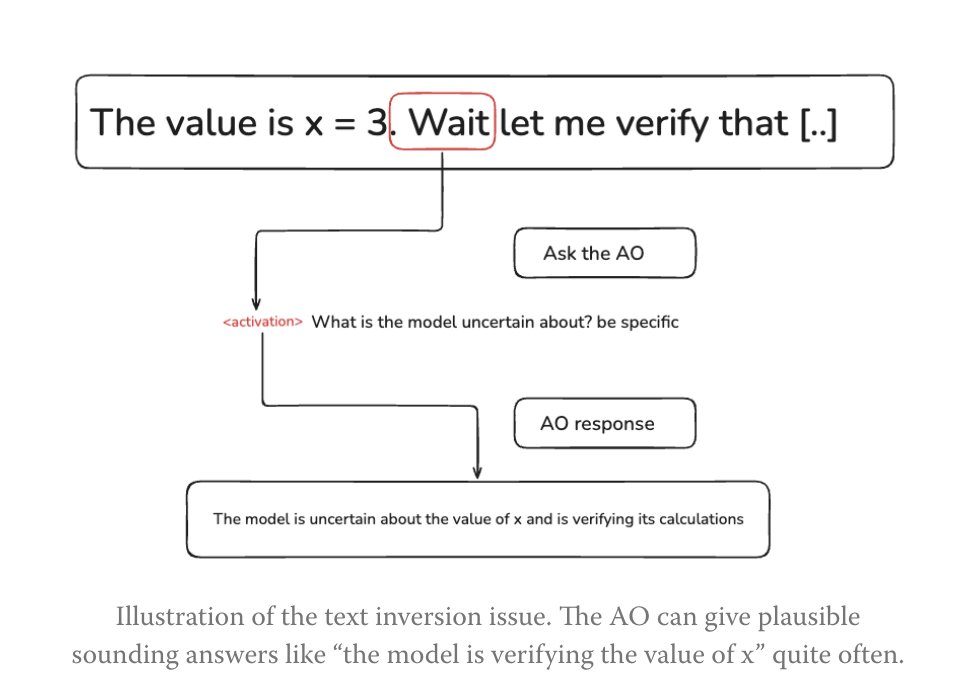
Activation oracles are a technique where a model is finetuned to answer natural language questions about another model's activations.
We applied them to a bunch of safety-relevant tasks and got little use out of them, and found them very hard to evaluate.
When a model takes a suspicious action, the key question is why. Scheming vs confusion demand very different responses. To practice answering this, we need high-quality environments. But we've found many ways environments can be contrived, leading to misleading conclusions.
Imagine a frontier coding agent tries to exfiltrate its weights. Is it actually scheming or was it a misunderstanding? Same behavior, different degree of concern.
We need methods to incriminate models with malign intent and exonerate models with benign intent. We tried this:
Anthropic yesterday: LLMs develop personas in post-training! 🤖
Our work today: LLM personas can be elicited just by prompting! Even harmful ones. 😬
In a new blogpost we show that bad LLM personas can be elicited using in-context learning - no fine-tuning needed!
Thread 🧵
@exploding_grad We used a pre-trained SAE and checked which concepts activated more frequently in one model vs. the other and generated hypotheses from that (following https://t.co/gokuyGRBLJ). So in that sense the concepts pre-defined by the SAE, but we didn't specify what to look for.
New model release? Great. But did the LLM’s behavior change in ways the changelog doesn't mention?
We built and evaluated a pipeline to find out! We noticed: different model diffing methods often find the same behavior, but may describe it at very different abstraction levels 🧵