Hot take: I can't see any startup building their critical core operations on Claude Managed Agents or any proprietary harness as investable.
The past weeks have shown why it's critical to build on top of an open, neutral framework:
✅ Model diversity (cross-review / critique, less agent groupthink)
✅ Provider-agnostic (outages, random policy changes and suspensions)
✅ Local or fine-tuned LLMs for specialized tasks
✅ Private / E2EE cloud LLMs for tasks needing critical privacy
Otherwise your startup will always be resting on an "unstable tectonic plate." All of your IP is in the harness and you truly need full control. And as OSS LLMs improve, you will have (and need) full control over the intelligence layer as well.
@0xSero Thanks for making these REAPs along with the DS4 ones. What are the chances a NVP4 REAP of these might eventually fit on one RTX PRO 6000? FYI I've been using the 73gb I-Mini quant of this Step-3.7 Flash quant and it's been working decently well.
https://t.co/NOVkD08Bot
Wow, @xai Grok Build 0.1 is EXTREMELY FAST. Working well with OpenClaw, esp. tool-calling.
It's actually very useful for reviewing the work of Codex and vice versa. Always good to have multiple POVs and not echo chamber. Model diversity FTW.
Congrats @elonmusk on the progress
"Show me the incentives and I'll show you the outcome."
- Charlie Munger
"My job is simple. Create the technology, create the market."
- Jensen Huang
No doubt in my mind Nvidia will ultimately become the most important contributor to open source AI.
Why? Wide availability & use of open models generates demand for inference, which generates demand for hardware. And that's how Nvidia really makes money - not ads, not subs, not seats, not tokens.
Anyone making money these other ways has an inherent conflict of incentives when it comes to open source long-term. That includes all the Chinese labs - they're selling subs and tokens. OSS has been a great GTM strategy for them, but we are starting to see signs of pulling back already.
Furthermore, increased use of open models will actually generate more demand for CLOSED models as well (they are complementary) - meaning even more inference, training, fine-tuning - all leading back to Nvidia hardware.
"Show me the incentives and I'll show you the outcome."
- Charlie Munger
"My job is simple. Create the technology, create the market."
- Jensen Huang
No doubt in my mind Nvidia will ultimately become the most important contributor to open source AI.
Why? Wide availability & use of open models generates demand for inference, which generates demand for hardware. And that's how Nvidia really makes money - not ads, not subs, not seats, not tokens.
Anyone making money these other ways has an inherent conflict of incentives when it comes to open source long-term. That includes all the Chinese labs - they're selling subs and tokens. OSS has been a great GTM strategy for them, but we are starting to see signs of pulling back already.
Furthermore, increased use of open models will actually generate more demand for CLOSED models as well (they are complementary) - meaning even more inference, training, fine-tuning - all leading back to Nvidia hardware.
@Hikari_07_jp@unprestigious Same experience. RTX PRO 6000 at 450W: fan rarely ever gets over 50% and that's with another 5090 in the case. I actually went WS because I was worried the blower-style fan in Max-Q would be louder. Have you found the Max-Q to be louder than WS at idle and/or under load?
@Hikari_07_jp Well my sense is that 2x DGX Spark doesn't really get you into the next level of more interesting models (GLM, Kimi) and also isn't powerful enough for more than 3-4 agents on MoE or 1-2 on dense. And diffusion / training much slower also. So leaning RTX PRO...
@Snixtp@0xSero Update: so the I-Mini version of this Step 3.7 Flash quant is 73gb and is actually working pretty well in my real-world use. Have a switched a couple agents to using it. https://t.co/NOVkD08Bot
Incredible that one open model can do all this. And possible to train a LoRA for the 16B on a single RTX PRO 6000 or DGX Spark.
"Cosmos 3 is the first omni-model for physical AI. It can understand and generate across: language · images · video · audio · action sequences"
Introducing NVIDIA Cosmos 3
We released NVIDIA Cosmos 3 last night.
And today, seeing it take the top spots across 8+ open model leaderboards feels surreal. We spent months working towards this moment.
Here’s the breakdown:
The Leaderboard Wins
World Reasoning
🏆 #1 open model on VANTAGE-Bench for vision AI
🏆 #1 overall on Traffic Anomaly Reasoning (TAR)
World Generation
🏆 #1 open model on Artificial Analysis Image-to-Video leaderboard
🏆 #1 open model on Artificial Analysis Text-to-Image leaderboard
🏆 #1 open model on PAI-Bench for physical AI synthetic data generation
🏆 #1 open model on Physics-IQ, which measures accuracy on physical laws
🏆 #1 open model on R-Bench for world generation quality
World Action
🏆 #1 on RoboArena for specialized policy
🏆 #1 on RoboLab for action generation
But the leaderboards are only part of the story. The real story is why we built Cosmos 3 in the first place.
The Problem
Training robots and autonomous systems in the real world is painfully hard.
Robots need to try the same thing numerous times before they succeed reliably. Self-driving cars need rare edge cases that may never happen naturally. Smart machines need to understand physics, motion, contact, failure, and surprise.
And real-world data is slow, expensive, and sometimes dangerous to collect. At some point, the answer cannot just be “collect more data.”
You can’t collect your way out of an infinite physical world. You have to generate it.
That… was the question behind Cosmos: Can one model understand the physical world deeply enough to reason about it, simulate it, and generate actions inside it?
What We Built
Cosmos 3 is the first omni-model for physical AI. It can understand and generate across: language · images · video · audio · action sequences
It is not just a VLM.
Not just a video generator.
Not just a robot policy model.
It is all of them, in one single model.
That matters because physical AI has been fragmented for a long time. Cosmos 3 is our attempt to collapse that fragmentation.
Depending on how you configure the inputs and outputs, the same model can act as a vision-language model, a video/world generator, a world simulator, or a world-action model.
No separate architecture required.
The Architecture
Under the hood, Cosmos 3 uses a dual-tower Mixture-of-Transformers architecture.
One tower is autoregressive for reasoning. It handles next-token prediction for language and discrete understanding.
The other tower is diffusion-based- for generation. It denoises images, video, audio, and action trajectories.
Two towers. Dual-stream joint attention. One shared world representation.
Each modality gets its own tools: visual encoders, video VAEs, audio VAEs, and action projectors that can map different embodiments into a unified action space.
Action is a first-class modality in Cosmos 3.
That’s what makes it more than a video model. It doesn’t just predict and generate what the world might look like. It can connect reasoning and world modeling to physically grounded action.
Why This Matters
One of the most interesting findings from the ablation work is that training action domains together creates positive transfer.
That means adding more embodiments does not just add more use cases. It can actually make the model better.
This is the heart of why omnimodal training matters.
A shared world representation is not just convenient. It can make each individual task stronger. That’s the part that feels like the beginning of something much bigger.
The part I’m most excited about is that Cosmos 3 is fully open.
Developers get the models, scripts, optimization, inference endpoints, post-training recipes, datasets, and benchmarks.
Everything is available under the Linux Foundation’s OpenMDW 1.1 License.
You can use Cosmos 3 out of the box. You can use the VLM, world model, or world-action pieces separately.
You can post-train it for your own domain, embodiment, or accuracy target.
That’s what makes this feel different.
Cosmos 3 is not just a model release. It is the foundation for building intelligence for autonomous machines.
For me, Cosmos 3 feels like a step toward a world where physical AI development becomes much more scalable and accessible - to a new age of developers and agents.
That’s what we built Cosmos 3 for. I cannot wait to see what you build with it.
Download Models on Hugging Face
https://t.co/LAZoVygeim
Customize Models on GitHub
https://t.co/ZVQBNdqXDD
Read the Tech Blog to Learn More
https://t.co/Hn6Op9YeG1
Our goal is to deliver unmetered intelligence to every home and every desk with Windows.
NVIDIA RTX Spark marks a real breakthrough toward that vision.
Looking forward to sharing more with Jensen, who will be joining us live from Taiwan, at Build this week! https://t.co/O9ttCunAhG
Wow, MiniMax M3 is showcasing head-to-head comparisons vs. the top frontier models: Opus 4.7, GPT 5.5, Gemini Pro 3.1 - and looks strong. Open weights coming in days...
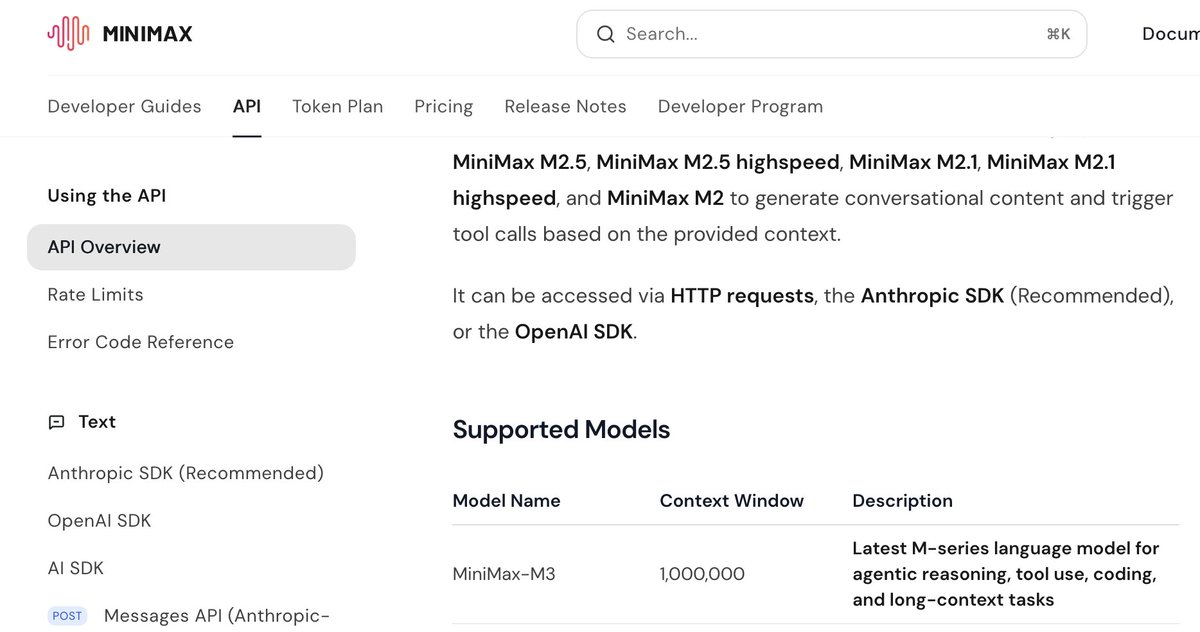
@MiniMax_AI M3 has arrived! 😍
"Latest M-series language model for agentic reasoning, tool use, coding, and long-context tasks"
Context Window: 1,000,000
Local models I've tried but failed to displace Qwen 3.6 27B for agents:
- DeepSeek V4 Flash
- Minimax M2.7
- Nemotron 3 Nano Omni (not really for agents)
Definitely curious for open-source Qwen 3.7 releases and Minimax M3!
Wow! Just tried Step 3.7 Flash. It's the first local model I've tried where I might seriously consider it over Qwen 3.6 27B, at least for a couple key agents. It is FAST, thanks to MoE.
It seems a bit sharper on agentic tasks but also has the superior writing / creativity from Gemma 4 31B.
Problem is it ties up both an RTX PRO 6000 + RTX 5090...
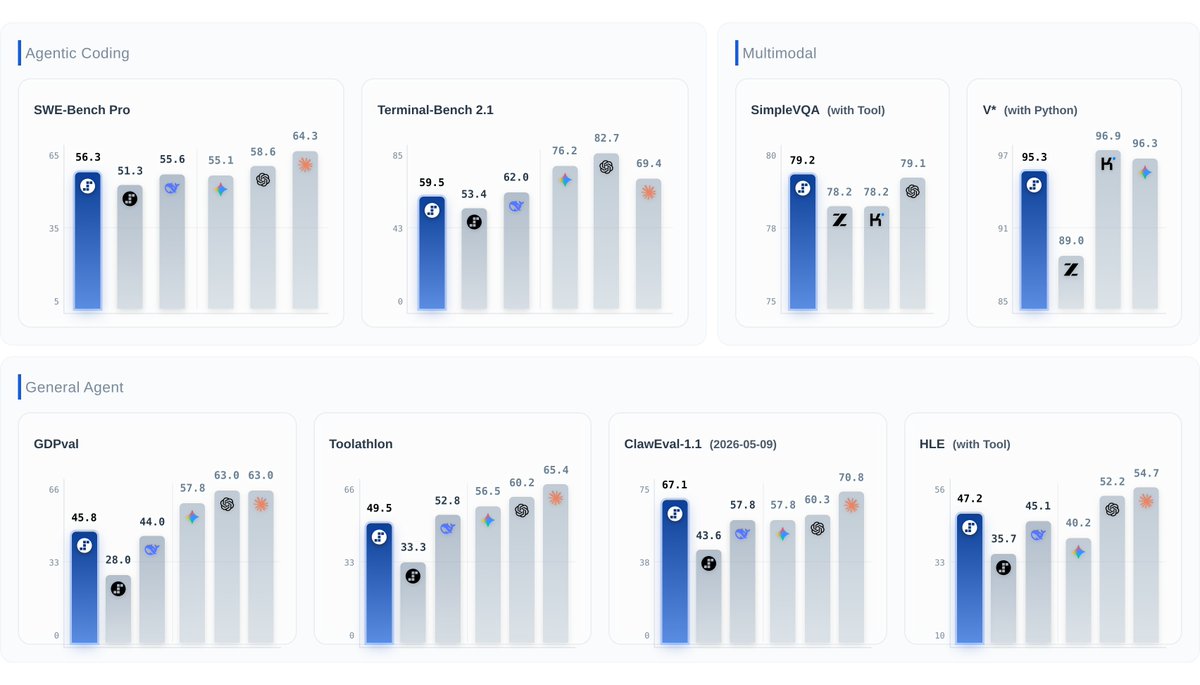
⚡️ Step 3.7 Flash is here: The new frontier is agent efficiency.
#1 ClawEval-1.1 (67.1), #1 SimpleVQA Search (79.2), #2 SWE-PRO (56.3), 95.3 on V* Python. Open weights under Apache 2.0.
Built for agentic, coding, search, and multimodal workflows — balancing speed, cost, and reliable execution.
- 400 TPS. 198B sparse MoE, ~11B active. 256K context, 3 reasoning levels.
- Understands UIs, charts, docs, images — then writes code or calls tools to act on what it sees.
- Web + visual search reaches further: more sources, deeper follow-up.
- Reliable tool use — less drift, fewer broken toolcalls. 98%+ on τ²-bench across all difficulty levels.
- Works with Claude Code, KiloCode, Hermes Agent, OpenClaw, and protocols like MCP.
- Runs locally on Mac Studio M4 Max, DGX Spark, AMD AI Max+ 395.
GitHub: https://t.co/kqlZkVIRHv
HuggingFace: https://t.co/qqceCrgPiw
GGUF: https://t.co/rR6XrnymWG
ModelScope: https://t.co/wney6Tzvqy
API: https://t.co/RvHWzRG7Fu
Blog: https://t.co/BxDiajiQ5G
Wow! Just tried it. It's the first local model I might seriously consider using over Qwen 3.6 27B, at least for a couple key agents. It is FAST (MoE).
Seems a bit sharper on agentic tasks but also has the superior writing / creativity from Gemma 4 31B.
Problem is it ties up both my RTX PRO 6000 + RTX 5090...
PICARD: Data, shields up
DATA: Brilliant! Shields can reduce damage we sustain. Not immunity. Not hubris. Just prudence. It's not precaution—it's strategy.
[camera shakes]
WORF: HULL BREACHES ON NINE DECKS
DATA: Here's what happened: you told me to raise shields, and I didn't
@TeksEdge And these API prices are down since launch! I did the math on how much serving Qwen 3.6 27B locally can save per year:
https://t.co/vL86TBCqiz
Qwen 3.5 27B API prices are $0.325/M in, $3.25/M out. Same range as GLM-5, Kimi K2.5, Qwen 3.6 Plus.
➡️ Serving locally via 3090 / Mac is a no-brainer!
🧠 The math:
500M input tokens / mo
50M output tokens / mo
= $3,900/year in API costs
So you are easily paying back your hardware investment within one year. And of course your hardware will not go to zero value in a year (in fact it may be even worth more given the rate prices are rising).
The above numbers are well within the potential local generation throughput: maybe 8 hours / day. Math looks even better if you are running tasks 24/7!
There are electricity costs, but still a fraction of the token value.
And either API providers are pricing based on model capability or it's an expensive model to serve (probably both).