Anthropic’s JV looks less like a services business and more like an architecture for adoption and valuation: PE brings distribution, the JV absorbs implementation intensity, and Anthropic preserves the high-margin platform narrative.
Anthropic CEO Dario Amodei: “50% of all tech jobs, entry-level lawyers, consultants, and finance professionals will be completely wiped out within 1–5 years.”
1/ Plan in short sprints
2/ Encourage demos and evals over doc (get a prototype in front of internal folks and users asap!)
3/ Revisit features with new models
4/ Do the simple thing first
My top 3 tips for coding with agents:
1. Always start with Plan Mode. It's better to iterate in natural language and then execute once you know what the agent is going to do. This will save you time, effort, and tokens!
2. Start new chats frequently. Remember that your role is to point the Agent in the right direction to make the changes you need. If you change topics, the context window will get muddied. You will also be spending more tokens on longer chats.
3. Leverage AI to do your code review. If you know the failure case, ask a model. One prompt I often use is "scan the changes on my branch and confirm nothing is impacted outside of my feature flag". As a safety net for everything outside this issues-you-expect umbrella, use Bugbot.
Open-source examples and guides for building with the OpenAI API. Browse a collection of snippets, advanced techniques and walkthroughs. Share your own examples…
Googleアプリで共有しました https://t.co/6hn3WV9E7b
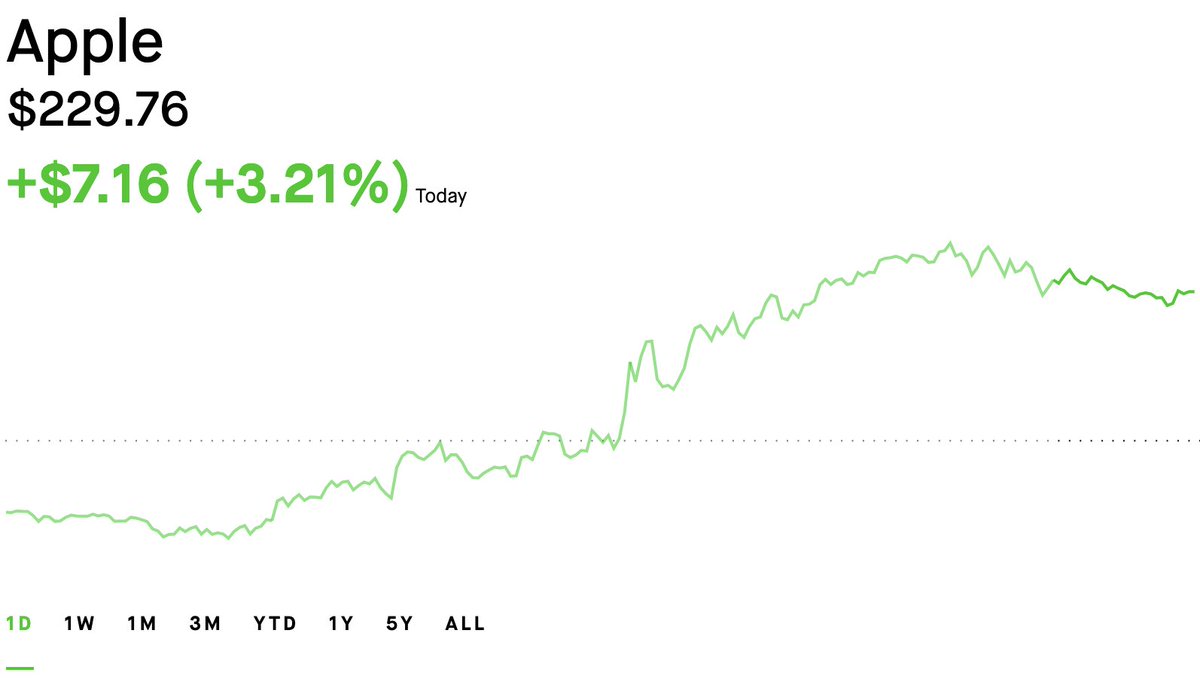
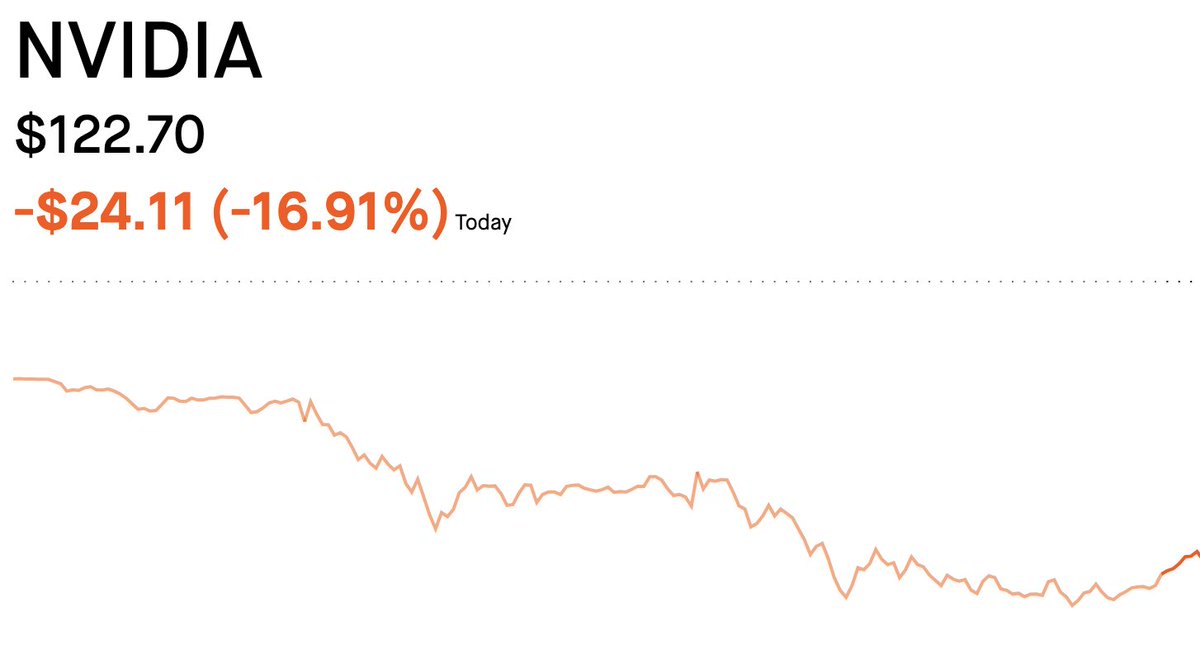
Market close: $NVDA: -16.91% | $AAPL: +3.21%
Why is DeepSeek great for Apple?
Here's a breakdown of the chips that can run DeepSeek V3 and R1 on the market now:
NVIDIA H100: 80GB @ 3TB/s, $25,000, $312.50 per GB
AMD MI300X: 192GB @ 5.3TB/s, $20,000, $104.17 per GB
Apple M2 Ultra: 192GB @ 800GB/s, $5,000, $26.04(!!) per GB
Apple's M2 Ultra (released in June 2023) is 4x more cost efficient per unit of memory than AMD MI300X and 12x more cost efficient than NVIDIA H100!
Why is this relevant to DeepSeek?
DeepSeek V3/R1 are MoE models with 671B total parameters, but only 37B are active each time a token is generated. We don't know exactly which 37B will be active when we generate a token, so they all need to be ready in high-speed GPU memory.
We can't use normal system RAM because it's too slow to load the 37B active parameters (we'd get <1 tok/sec). On the other hand GPUs have fast memory but GPU memory is expensive. Apple Silicon, however, uses Unified Memory and UltraFusion to fuse dies - a tradeoff that favors a large amount of medium-fast memory at a cheaper cost.
Unified memory shares a single pool of memory between the CPU and GPU rather than having separate memory for each. There's no need to have separate memory and copy data between the CPU and GPU.
UltraFusion is Apple's proprietary interconnect technology for connecting two dies with a super high speed, low latency connection (2.5TB/s). Apple's M2 Ultra is literally two Apple M2 Max dies fused together with UltraFusion. This is what enables Apple to achieve such a high amount of memory (192GB) and memory-bandwidth (800GB/s).
Apple M4 Ultra is rumored to use the same UltraFusion technology to fuse together two M4 Max dies. This would give the M4 Ultra 256GB(!!) of unified memory @ 1146GB/s. Two of these could run DeepSeek V3/R1 (4-bit) at 57 tok/sec.
All of this and Apple has managed to package this in a small form-factor for consumers with great power efficiency and great open-source (uncharacteristic of Apple!) software. MLX (h/t @awnihannun) has made it possible to leverage Apple Silicon for ML workloads and @exolabs has made it possible to cluster together multiple Apple Silicon devices to run large models, demonstrating DeepSeek R1 (671B) running on 7 M4 Mac Minis.
It's unclear who will build the best AI models, but it seems likely that AI will run on American hardware, on Apple Silicon.
I don't have too too much to add on top of this earlier post on V3 and I think it applies to R1 too (which is the more recent, thinking equivalent).
I will say that Deep Learning has a legendary ravenous appetite for compute, like no other algorithm that has ever been developed in AI. You may not always be utilizing it fully but I would never bet against compute as the upper bound for achievable intelligence in the long run. Not just for an individual final training run, but also for the entire innovation / experimentation engine that silently underlies all the algorithmic innovations.
Data has historically been seen as a separate category from compute, but even data is downstream of compute to a large extent - you can spend compute to create data. Tons of it. You've heard this called synthetic data generation, but less obviously, there is a very deep connection (equivalence even) between "synthetic data generation" and "reinforcement learning". In the trial-and-error learning process in RL, the "trial" is model generating (synthetic) data, which it then learns from based on the "error" (/reward). Conversely, when you generate synthetic data and then rank or filter it in any way, your filter is straight up equivalent to a 0-1 advantage function - congrats you're doing crappy RL.
Last thought. Not sure if this is obvious. There are two major types of learning, in both children and in deep learning. There is 1) imitation learning (watch and repeat, i.e. pretraining, supervised finetuning), and 2) trial-and-error learning (reinforcement learning). My favorite simple example is AlphaGo - 1) is learning by imitating expert players, 2) is reinforcement learning to win the game. Almost every single shocking result of deep learning, and the source of all *magic* is always 2. 2 is significantly significantly more powerful. 2 is what surprises you. 2 is when the paddle learns to hit the ball behind the blocks in Breakout. 2 is when AlphaGo beats even Lee Sedol. And 2 is the "aha moment" when the DeepSeek (or o1 etc.) discovers that it works well to re-evaluate your assumptions, backtrack, try something else, etc. It's the solving strategies you see this model use in its chain of thought. It's how it goes back and forth thinking to itself. These thoughts are *emergent* (!!!) and this is actually seriously incredible, impressive and new (as in publicly available and documented etc.). The model could never learn this with 1 (by imitation), because the cognition of the model and the cognition of the human labeler is different. The human would never know to correctly annotate these kinds of solving strategies and what they should even look like. They have to be discovered during reinforcement learning as empirically and statistically useful towards a final outcome.
(Last last thought/reference this time for real is that RL is powerful but RLHF is not. RLHF is not RL. I have a separate rant on that in an earlier tweet
https://t.co/RMIpFPVpuM)