Introducing a more powerful NotebookLM 🚀
Massive upgrades deliver agentic capabilities in chat, more advanced reasoning, and a suite of new output formats. Tackling complex, multi-step research problems has never been easier.
Rolling out now to Google AI Ultra subscribers.
El paradigma de ingesta del segundo cerebro de Karpathy, donde tienes una carpeta donde echar tus datos en crudo y que luego un agente procesa y estructura para agregarla a una wiki o segundo cerebro, es un patrón escalable a otras tantas aplicaciones.
Yo en mi caso por ejemplo ya tenía creada una aplicación financiera que usaba un sistema similar: mis extractos bancarios, facturas, datos traídos de APIs, modelos de impuestos en pdf... todo en crudo en una carpeta. Con la idea de luego llamar a un agente que trabaje en dar orden y forma a esos datos (una única vez) para procesarlos adecuadamente de cara a que luego lo consuma una aplicación (en este caso en vez de Obsidian, un front-end).
Se me antoja como un nuevo tipo de aplicación con un patrón arquitectónico que funciona por poner en su diseño a un agente que cada cierto tiempo sale a pasear para dar orden al caos de la carpeta de datos. No es un script determinista que sepas que va a funcionar siempre igual, con lógicas encorsetadas a formatos concretos, sino que tiene la flexibilidad de comerse y procesar cualquier dato crudo que pongas en la carpeta.
Y donde además cualquier dato alimenta al sistema y lo mejora para hacerlo crecer.
Además, obviamente los agentes no sólo actúan como procesadores de esa información sino que luego se nutren de todo el sistema para poder hacerle consultas mucho más completas o hacer crecer tu aplicación con cada nuevo dato crudo que se agrega.
Estamos empezando a diseñar software alrededor de datos caóticos, confiando en las capacidades de una nueva capa agéntica. El usuario no se adapta al software sino que el software se adapta al caos del usuario.
So good
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
#Córdoba | Crece la indignación en la vereda Trementino Arriba, en el municipio de Pueblo Nuevo, por el vertimiento de residuos con posibles químicos en una represa de la zona, situación que mantiene en alerta a sus habitantes. De momento se habla que la responsabilidad sería de una empresa de hidrocarburos.
Los pobladores, que cuestionaron al conductor de un carro cisterna el pasado 8 de abril, aseguran que los olores son intensos, persistentes y prácticamente insoportables, afectando la vida diaria de las familias. “No se puede ni respirar con tranquilidad”, relatan algunos residentes, quienes advierten que la situación se viene presentando desde hace varios días sin una respuesta efectiva.
La comunidad cuestiona la aparente falta de control y vigilancia frente a este tipo de prácticas, que, según denuncian, se estarían realizando sin ningún tipo de tratamiento ni supervisión ambiental. Temen que los vertimientos estén contaminando el agua y el suelo, lo que podría desencadenar afectaciones graves en la salud de niños, adultos mayores y población en general. #ElMeridianoTeUbica @MinAmbienteCo@CorporacionCVS
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
Os dejo aquí las dos cosas por si queréis profundizar:
📘 Informe completo de Finlandia
https://t.co/TNt4mrS64D
📩 Suscripción a mi newsletter, GadeIA
https://t.co/cee6dy5bgw
Ahí sigo desarrollando este tipo de cuestiones sobre IA, aprendizaje, evaluación, liderazgo y toma de decisiones en centros y universidades.
Si los resúmenes de vídeo en @NotebookLM cambiaron tu forma de estudiar, prepárate para cambiar tu forma de crear contenido. 🍿
Llegan los Resúmenes en Video Cinematográfico.
✅ Libre de marcas de agua.
✅ Alta fidelidad de imagen y movimiento.
✅ Acceso directo en web y móvil.
⚠️ Segundo aviso de la semana para centros educativos y universidades.
Creo que muchas instituciones siguen pensando la IA como una capa para generar materiales más rápido.
El problema es que ya están apareciendo proyectos que apuntan a algo bastante más profundo. Pasar de contenidos estáticos a experiencias de aprendizaje orquestadas con agentes.
He estado probando OpenMAIC, un proyecto open source impulsado desde la Tsinghua University, y lo interesante no es que cree unas diapositivas o un resumen más.
Lo interesante es otra cosa.
Detrás hay un paper académico que plantea el paso de los MOOC tradicionales a lo que llaman MAIC, una especie de aula aumentada con agentes de IA que busca combinar escalabilidad con adaptabilidad. Además, el proyecto tiene repositorio público en GitHub y demo abierta.
Con un solo prompt puede estructurar una sesión entera y montar un entorno de aprendizaje interactivo con varios elementos a la vez.
Un agente que explica.
Otros agentes que acompañan la discusión (tus compañeros).
Quizzes adaptativos.
Pizarra.
Flujo de contenidos.
Dinámica de interacción en tiempo real.
Es decir, no estamos hablando solo de usar IA para preparar clases.
Estamos empezando a ver sistemas capaces de orquestar experiencias de aprendizaje.
Y esto ya no se mueve solo en el terreno del hype. El paper habla de experimentos preliminares en Tsinghua y de más de 100.000 registros de aprendizaje de más de 500 estudiantes, aunque conviene leerlo como un trabajo inicial, no como una verdad definitiva cerrada.
Todavía hay mucho que madurar:
- Calidad pedagógica.
- Fiabilidad.
- Criterio didáctico.
- Sesgos.
- Supervisión docente.
- Carga cognitiva.
- Privacidad.
Pero, aun así, la señal me parece clarísima.
El diseño de experiencias de aprendizaje ricas, interactivas y personalizables va a volverse mucho más accesible.
Y cuando eso ocurra, la pregunta para un centro o una universidad no será si usa IA.
La pregunta será otra.
Qué valor diferencial aporta tu institución cuando crear una experiencia formativa técnicamente solvente empieza a costar mucho menos que antes.
Porque entonces habrá que repensar muy bien cosas como el papel del docente, el diseño instruccional, la tutorización, la evaluación y la estrategia institucional que da sentido a todo eso.
No creo que la tecnología sustituya una buena educación.
Pero sí creo que va a poner bajo presión a las instituciones que sigan confundiendo innovación con añadir herramientas sueltas sin rediseñar el modelo.
Esto no va de probar una plataforma.
Va de entender hacia dónde se mueve el aprendizaje.
¿Tu institución está explorando estas posibilidades desde una lógica estratégica o todavía desde la curiosidad individual?
En el primer comentario dejo el acceso a todos los recursos.
#edtech #IA #OpenMAIC #liderazgo
¡ATENCIÓN, ESTO ES ENORME! 🔥🧠💥
@eonsys ACABA DE ROMPER TODOS LOS LÍMITES CONOCIDOS
Copiaron AL 100% el cerebro de una mosca de la fruta (¡solo 140 mil neuronas!) dentro de un simulador de física… y la mosca DIGITAL EMPEZÓ A VIVIR: camina, busca comida, se comporta como si estuviera viva…
¡SIN NINGÚN ENTRENAMIENTO DE IA! ¡CERO machine learning! ¡CERO datasets!
Todo sale SOLO del cableado biológico exacto (el mapa brutal que salió en Nature 2024).
ChatGPT y toda esa IA de billones de parámetros se quedan chiquitos al lado de esto.
Esto NO es “aprender a imitar”.
Esto es LITERAMENTE RESUCITAR un cerebro real en código.
Y adivinen qué…
YA están yendo por el siguiente nivel:
CEREBRO DE RATÓN → 70 MILLONES de neuronas.
Está en camino. YA LO DICEN. 😱😱
Pero esperen… lo que viene después es DEMASIADO LOCO:
Si esto escala… estamos a un paso de poder SUBIR a la nube el cerebro de un ser humano VIVO.
¿Te imaginas? Tu mente, tus recuerdos, tu “yo”… viviendo eternamente en silicio mientras tu cuerpo sigue aquí.
La humanidad está a punto de cruzar una línea que NUNCA podremos des-cruzar.
¿Estamos preparados para el primer humano digital?
¿O ya es demasiado tarde para preguntarlo?
🧠→💾→∞
ESTO ACABA DE EMPEZAR 🔥
https://t.co/iH1MVi10gn…
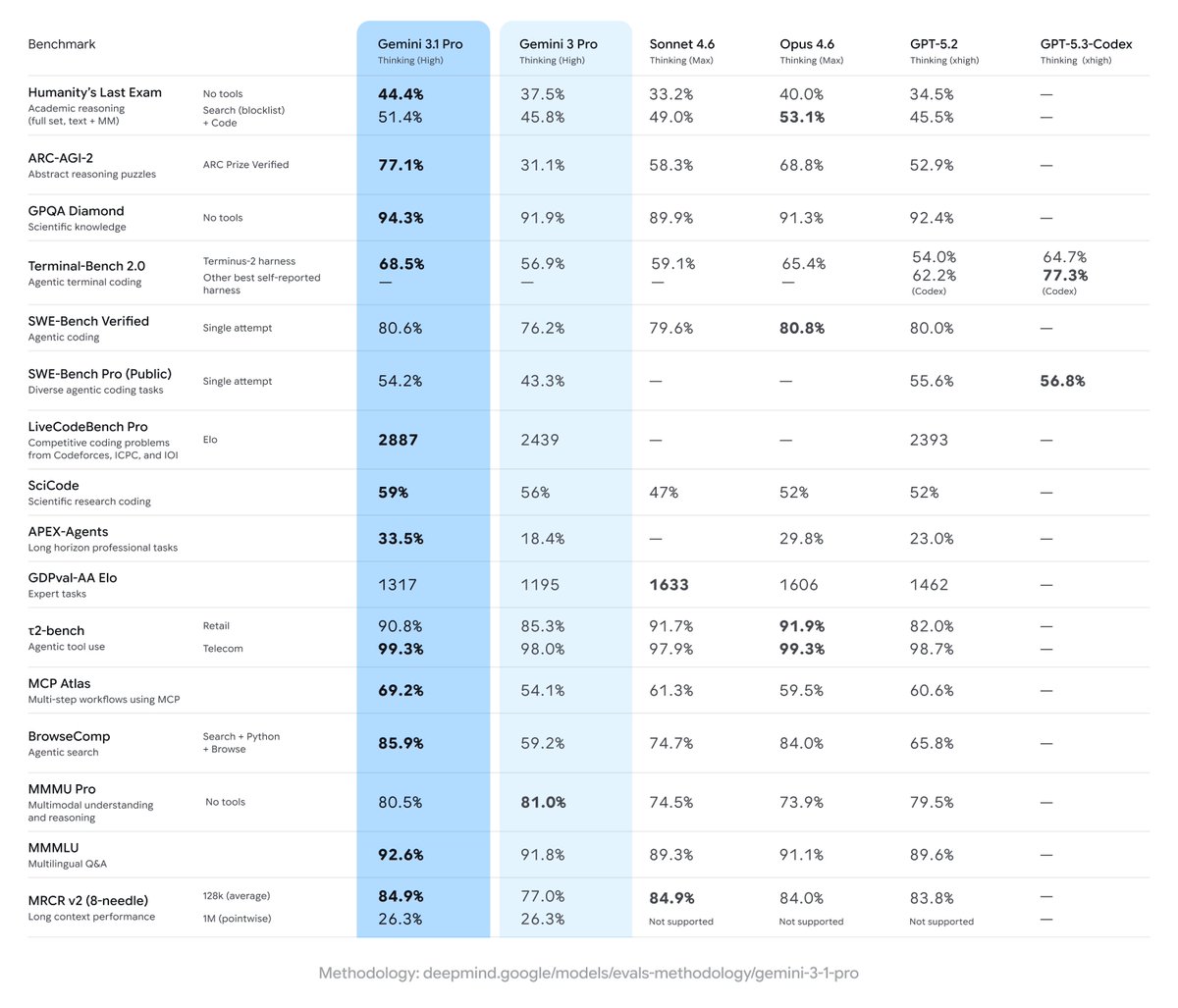
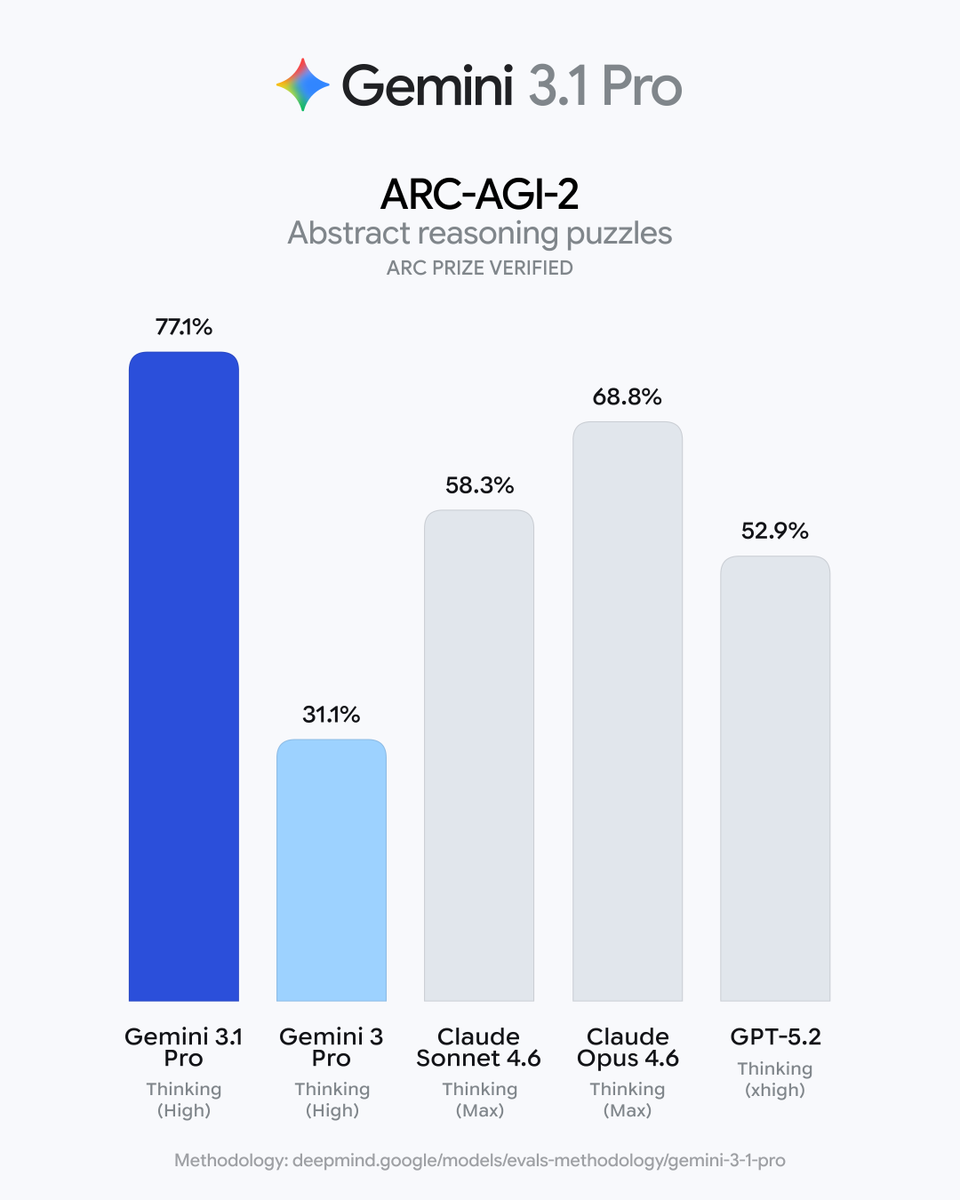
Gemini 3.1 Pro is our new baseline for complex problem-solving.
This model represents a major leap in core reasoning, verified by a 77.1% score on the ARC-AGI-2 benchmark — which tests the ability to solve brand-new logic patterns.
That’s more than double the performance of 3 Pro.
#Córdoba I Montería pierde sus “pulmones verdes”: la mayoría de los humedales de la cuenca del río Sinú ha desaparecido, lo que, según expertos, explica en gran medida las recurrentes inundaciones en la región.
El profesor Rubén Darío Godoy Gutiérrez, investigador de la Universidad de Córdoba y experto en ordenamiento territorial, aseguró que en 2002 existían 48 humedales en la cuenca del río Sinú, pero hoy solo sobreviven unos 7 cuerpos de agua, muchos de ellos reducidos a espejos temporales en temporada de lluvias. “Prácticamente el 80% o más de los humedales ha desaparecido”, afirmó Godoy.
El investigador recordó que la Corte Constitucional, en la sentencia T-194 de 1999, ordenó a las autoridades locales recuperar el dominio público de los terrenos de los humedales que habían sido desecados o apropiados por particulares, una disposición que no se ha cumplido tras 27 años.
Godoy advirtió que los urbanizadores justifican la construcción en estas zonas argumentando que Montería era originalmente un humedal, por lo que propuso construcciones sobre pilotes de al menos 1,5 metros para reducir riesgos de inundación.
Finalmente, el académico instó a actuar de manera inmediata: “A corto y mediano plazo hay que recuperar los humedales; no podemos esperar otros 10 años. Con el cambio climático, estos fenómenos se presentan con mayor frecuencia y los impactos son cada vez más graves”.
El profesor Godoy ha publicado investigaciones sobre los conflictos de uso del suelo y ordenamiento territorial en Montería, destacando la urgencia de implementar soluciones estructurales para proteger a la población y los ecosistemas.
#chn26unicor
#UnicórdobaTeCuenta. El docente investigador de Unicórdoba, Rubén Darío Godoy Gutiérrez, aseguró que en el 2002 existían 48 humedales en la cuenca del río Sinú y hoy a la mayoría se han desaparecido y esto sin duda es una de las principales causas de las recurrentes inundaciones