After some mathematical rewrite, turns out all of transformer is a series of gemm + epilogue. Given a few optimized primitives, LLMs (and novice humans) can write speed-of-light kernels for all transformer ops!
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at https://t.co/GCdiMzk1Dl via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: https://t.co/drlDrxkYtp
🤗 Open Weights: https://t.co/T13Y8i7SDM
1/n
Church and state, politicians and free market. Has there been any checks on the system the directly link a politician’s random thoughts on the huge influence of stock market?
Let’s set the record straight: President Trump’s updated H-1B visa requirement applies only to new, prospective petitions that have not yet been filed. Petitions submitted prior to September 21, 2025 are not affected. Any reports claiming otherwise are flat-out wrong and should be ignored.
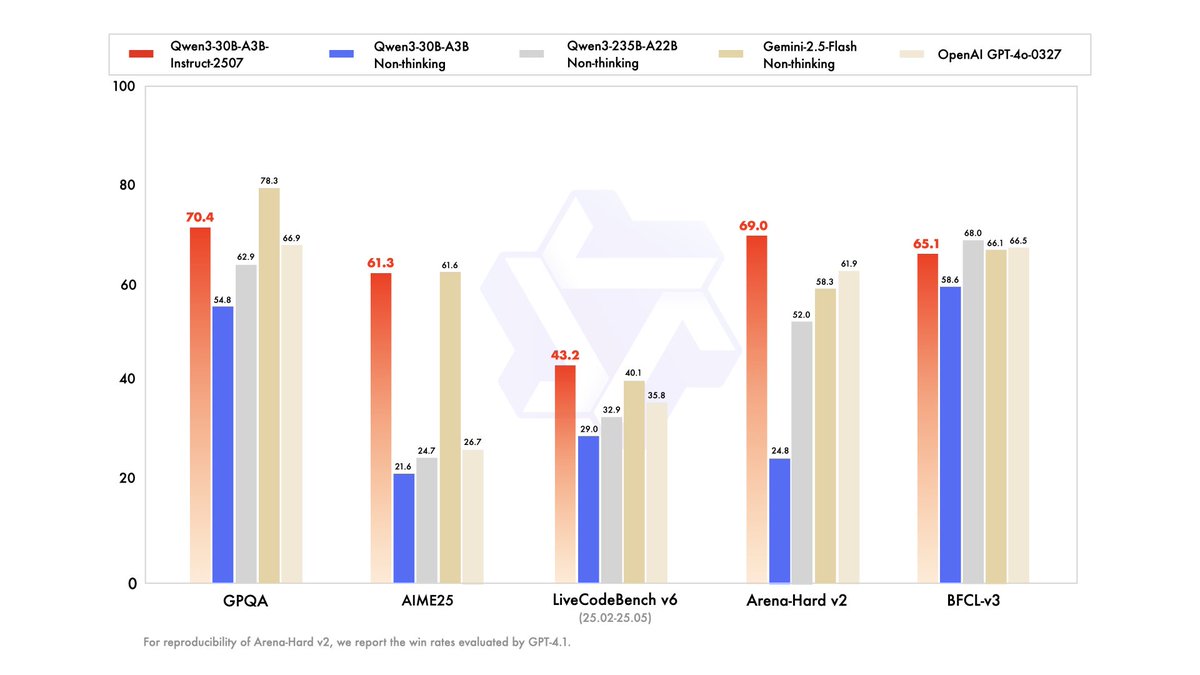
🚀 Qwen3-30B-A3B Small Update: Smarter, faster, and local deployment-friendly.
✨ Key Enhancements:
✅ Enhanced reasoning, coding, and math skills
✅ Broader multilingual knowledge
✅ Improved long-context understanding (up to 256K tokens)
✅ Better alignment with user intent and open-ended tasks
✅ No more <think> blocks — now operating exclusively in non-thinking mode
🔧 With 3B activated parameters, it's approaching the performance of GPT-4o and Qwen3-235B-A22B Non-Thinking
Qwen Chat: https://t.co/B9SNZr366l
HF:https://t.co/OglPSNk8lz or https://t.co/oF4NS4yJg0
ModelScope: https://t.co/PwWUW02Pgd or https://t.co/T7aw4V5iVE
One of the best ways to reduce LLM latency is by fusing all computation and communication into a single GPU megakernel. But writing megakernels by hand is extremely hard.
🚀Introducing Mirage Persistent Kernel (MPK), a compiler that automatically transforms LLMs into optimized megakernel, reducing latency by 1.2-6.7x.
🔧Tool: https://t.co/mRJ8sSg7HX
📝Blog: https://t.co/97b0YRSrS6
@Jiankui_He I cannot disagree more. If one says “regulations” there might be rooms for a constructive discussion but here “Ethics” is non-negotiable in so many levels.
I've been excited about this for a while: a simple architectural change to the residual connection that allows arbitrary overlapping of computation of one layer and the communication of another layer, leading to ~30% speedup in TP! More on MoE and expert parallel to come soon!
Met with @LisaSu today for 1.5 hours as we went through everything
She acknowledged the gaps in AMD software stack
She took our specific recommendations seriously
She asked her team and us a lot of questions
Many changes are in flight already!
Excited to see improvements coming
A strong Mamba2 hybrid model, competitive with transformers trained on 7x more data. Next step: we’ll make Mamba inference really fly, especially for large batch and long context
AMD CEO Lisa Su explains how ROCm fits into AMD's #AI performance and how partnerships may increase ROCm's impact.
#chips#software $AMD @JonFortt $NVDA #CUDA
Big day at #SC24!! Excited to announce El Capitan, powered by @AMD is now the world's fastest supercomputer at 1.742 exaflops! We now power 5 of the top 10 and 21 of the top 50 supercomputers in the world. Thanks to @HPE, @Livermore_Lab, @ENERGY for their partnership!