The NSA story is a world class case in media literacy. No, a LLM isn’t going to break encryption. There is nobody in their basement hacking into a NSA computer remotely on the public internet. They aren’t connected. If we understood basic things it’d take away so much noise.
We need models smart enough to distinguish between throwaway code intended to achieve a one off task and code we won’t repulse looking at in a couple of weeks.
My workflow with codex now is passing it through at least 5 or 6 code simplicity passes. Each time it says it did what I asked but then will say oh yeah I didn’t, let me actually do the simplification. So yes, loops might be the future.
The problem with the "if it works who cares what the code looks like" mindset for agentic work is that it assumes the agent has a perfect understanding of "works." Realistically, things are underspecified, agents make bad assumptions, etc.
To be fair, agents are pretty good at unit test coverage. They're pretty bad at designing human experiences (API, CLI flags, etc.), especially cohesive ones for future roadmap plans they may not have visibility into (unless your backlog is perfect and vision fully laid out, which I doubt). They're bad at knowing where performance matters and what type (CPU vs memory tradeoffs). They're bad at where compatibility matters and where it doesn't (and tend to err on the side of preserving it without further guidance). Etc.
Unless you have this ALL specified, you can't possibly claim "it works" without taking a look and thinking about it.
This is why I can’t go full on in loop mode. Literally with the most basic expectations it’ll tell you it did the thing you asked and then it does something different. And I’m supposed to multiply this by 100??
The thing about people talking about building with AI is that they always talk about how they’re building, what tools they use, and how much they use them.
Much less is said about what they actually built, or what impact it had.
The tool becomes the job. And the purpose.
@GergelyOrosz I don’t think it’s a proxy but can be a signal in the negative case. I’ve been places and know it’s fairly commonplace for engineers to not commit code for weeks / months. And that could be for legitimate or nefarious reasons
Even with employer caps, the spend on AI tokens dramatically exceeds any other historical spend on software.
Typically, companies maybe would spend on the order of $10-50 for a software license per month per employee, but now will pay hundreds or thousands on tokens to augment their productivity.
This shows you how big the TAM for intelligence is in the enterprise. The markets for AI are going to dramatically expand the size of the traditional software markets over time.
My conversation with @dkhos, CEO of Uber.
Dara took over in 2017, when Uber was losing roughly $4.5B a year.
Today the company generates $10B in free cash flow and is worth about $150B.
We discuss:
- How Daniel Ek convinced him to take the job
- How Uber spent a full year of its AI budget in a single quarter
- Uber's approach to autonomous vehicles
- Drones, hotels, and building a superapp
- Lessons from Allen & Co, Barry Diller, and Reed Hastings
Enjoy!
Timestamps
0:00 Intro
3:44 Bringing Order to Uber’s Chaos
7:22 Managing Stress and Going All In
14:28 Why Uber Is at the Center of AI and Physical
22:39 How to Win in Autonomous Vehicles
32:25 The Trillion-Dollar AV Opportunity
37:05 Drones, Robotaxis, and Global Adoption
38:20 Uber Eats, Uber One, and Aggregating Supply
47:00 The Future of the Uber App
55:55 Lessons from Barry Diller
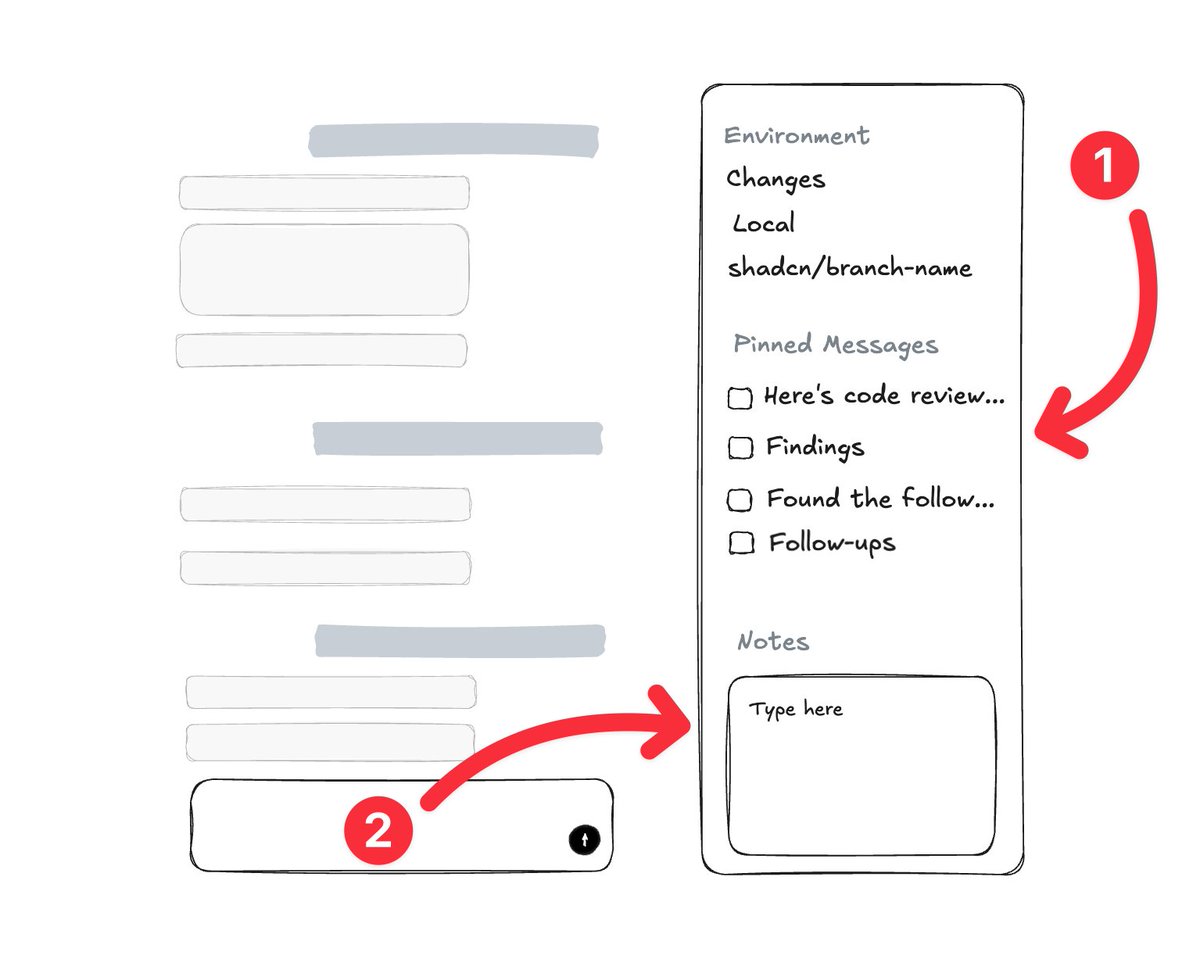
I want the following in Codex, Cursor, and OpenCode...
1. Pinned Messages: Let me pin assistant messages to the sidebar for things I want to keep track of but am not ready to address yet. Render as a checklist & jump navigation.
2. Notes: Give me a scratchpad for thoughts while working.
I've got an agent in a loop optimizing a renderer with the goal to minimize frame times (and tests to measure). It got times down from 88ms to 2ms and allocations down from ~150K to 500. Sounds good, right? Wrong. This is exactly why agent psychosis is a big fucking problem.
As an experiment, I rewrote the Ghostty core render state in Go, with access to identically laid out data structures as Ghostty and the exact same validation tests. I made a purposely naive renderer (simple, correct, but slow). 88ms per frame with 150,000 allocations (horrendous, lol)!
I then kickstarted a Ralph loop to bring the frame times down. I told it it can't modify input data structures or the public API or tests (they're correct), but it can do anything else it wants. It got to work.
It has worked for about 4 hours. I've spent around $350 on this experiment so far. The results?
88ms => 1.5ms
150K allocs => ~500 allocs
Incredible right? Nope.
My hand-written renderer I ported has frame times (same benchmark) of ~20us (0.020ms) and 0 allocations in the update path.
This is the problem with psychosis and lacking systems understanding. If you don't understand the system, you're going to accept that this is an incredible result. If you understand the system, you'll see better solutions immediately and can do roughly 75x better on throughput.
The people who blindly trust agent output are in the former camp. They're sheeple, overdrinking from a fountain of mediocrity.
Standard disclaimer: I use AI all the time. I like AI. The point I'm making is to not blindly accept results. Think. Analyze. Learn.