I'm a little late to the party on this one since it's from January, but I just read this great blog post by Jure Triglav walking through implementing surfel-based global illumination. It's got a bunch of really cool interactive toys/visualizers!
https://t.co/T5fsPEVx2N
Introducing Neural Harmonic Textures: our new method for real-time novel view synthesis that outperforms all 3DGS and NeRF derivatives including (finally) ZipNeRF in terms of quality across all benchmarks.
The code is released (Apache 2.0): (https://t.co/O0a2JyZ9Bu) 🧵
More I learn about collision detection, more challenges I see
For example, many traditional methods are non-differentiable, which makes it a huge pain to integrate them with learning pipelines. Say, if you want to teach a hand to grab a cup, given target points, you will face exactly this problem
This paper targets this by computing gradients via smooth local surrogate, while keeping the forward pass untouched, with loss defined as
D2(x1, x2) + D2(x1, t1) + D2(x2, t2)
It takes the closest points on both surfaces, samples each surface adaptively around them and uses distance-based softmax over the samples to better describe the the local surface geometry
Backwards pass then looks like:
Pose(Params) ->
CollisionDetection(Geometry) ->
PointSampling(CollisionPoints) ->
SmoothPoint(SampledPoints) ->
LossGradients
There is more than one way to achieve similar results, obviously, but I like this one
Christian Rupprecht explains their interpretability research in 3D computer vision, testing if (and where in the model) multi-view transformers like VGGT, DepthAnything 3, and DUSt3R use point/patch correspondences to make sense of 3D scene geometry.
Finally! All of that for just showing a dynamic illustration in app!
Bunch of algorithms was implemented for this dynamic illustration.
WIP version available (https://t.co/4ZMIat8pqU no LaTeX yet!)
Depends on ImPlatform for custom shaders https://t.co/mKI1Rn2HUF
1/4
🚀 #CVPR2026 paper alert: 🦏 RINO: Rotation-Invariant Non-Rigid Correspondences
Our network learns robust SO(3)-invariant features directly from raw 3D geometry. End-to-end, no pre-alignment or handcrafted descriptors!
Joint work @tumcvg & @Stanford.
📢📢📢𝐌𝐞𝐬𝐡𝐑𝐢𝐩𝐩𝐥𝐞: Structured Autoregressive Generation of Artist-Meshes
High-fidelity, topologically complete 3D assets that expand naturally like a ripple on a surface! 🌊
Existing AR models often rely on sliding-window inference over truncated segments. However, this limitation breaks long-range geometric dependencies, causing holes and fragmentation.
Instead, MeshRipple uses frontier-aware BFS and sparse-attention global memory to ensure coherent growth with an unbounded receptive field.
-> Highly detailed-mesh generations
-> Artist-like meshing quality
-> Works on room-scale environments
🌍https://t.co/FPmo9QBTac
🎥https://t.co/oV1zBua5iC
Great work by Junkai Lin, Hang Long, Huipeng Guo, Jielei Zhang, Jiayi Yang, Tianle Guo, Yang Yang, Jianwen Li, Wenxiao Zhang, Wei Yang
Want to create an avatar from a single image?
FlexAvatar is a transformer model that creates full 360°, high-quality, and expressive 3D head avatar from just a single portrait image in minutes.
Real-time Demo: FlexAvatar's lightweight architecture allows both animation and rendering in real-time, enabling interactive user experiences. To create a new 3D head avatar, only one image is required, e.g., from a webcam. The final avatar is ready after 2 minutes.
Architecture: Under the hood, FlexAvatar adopts a transformer-based encoder-decoder design. The encoder maps the input image onto a latent avatar space, while the decoder produces 3D Gaussian attribute maps by incorporating the animation signal via cross-attention.
The model learns all facial animations directly from the data without relying on pre-built 3D face models. This equips the avatars with realistic facial expressions.
The internal avatar latent space can be conveniently used to integrate additional observations of a person via fitting. This enables use-cases where more than one image of a person is available, e.g., from a phone scan of the person.
We train jointly on 2D monocular videos and multi-view data. However, in monocular videos, the animation signal leaks the target viewpoint, causing the model to produce incomplete 3D heads. We call this phenomenon entanglement of driving signal and target viewpoint.
To prevent entanglement, we introduce bias sinks. These are learnable tokens that indicate whether a training sample stems from a monocular or a multi-view dataset. During training, the model learns to produce incomplete 3D heads only when the monocular token is present.
During inference, FlexAvatar then always uses the multi-view token for which the model has learned to produce complete 3D heads. This simple design allows to combine the generalizability from monocular data with the quality of multi-view data.
FlexAvatar summary:
- Input: Single-image, phone scan, or monocular video
- Output: Full 360° head avatar
- Expressive animations
- Real-time rendering and animation
- Generalization to any portrait
- Create a new avatar in 2 minutes
- Use bias sinks to combine 2D and 3D data
🏠https://t.co/DTmz4OYtBM 🌍https://t.co/kghX1sloWU
🎥https://t.co/PHKXvGRK6J
Great work by @TobiasKirschst1 and @SGiebenhain!
📢📢📢 𝐒𝐩𝐡𝐞𝐫𝐢𝐜𝐚𝐥 𝐕𝐨𝐫𝐨𝐧𝐨𝐢: directional appearance as a differentiable partition of the sphere
– Project: https://t.co/mUPYvL887s
– Paper: https://t.co/v1SZrVfVoA
– Colab: https://t.co/WLJDMpv7Yu
Project led by 𝐅𝐫𝐚𝐧𝐜𝐞𝐬𝐜𝐨 𝐝𝐢 𝐒𝐚𝐫𝐢𝐨 (graduating!)
🚀 I’m excited to share my final work as a PhD student: 𝙈𝙚𝙨𝙝𝙎𝙥𝙡𝙖𝙩𝙩𝙞𝙣𝙜: 𝘿𝙞𝙛𝙛𝙚𝙧𝙚𝙣𝙩𝙞𝙖𝙗𝙡𝙚 𝙍𝙚𝙣𝙙𝙚𝙧𝙞𝙣𝙜 𝙬𝙞𝙩𝙝 𝙊𝙥𝙖𝙦𝙪𝙚 𝙈𝙚𝙨𝙝𝙚𝙨
- Arxiv: https://t.co/TRSiULSsTH
- Code: https://t.co/9A4fihfnMY
- Project page: https://t.co/vQ6oSpt2rb
released torch-diffsim: minimal parallelizable physics simulator supporting differentiation entirely in torch
put it in your training loop, and it just works out-of-the-box by allowing you to use torch.autograd
https://t.co/doP6fP38TV
“Everyone knows” what an autoencoder is… but there's an important complementary picture missing from most introductory material.
In short: we emphasize how autoencoders are implemented—but not always what they represent (and some of the implications of that representation).🧵
(1/6) We are thrilled to announce that "AAA-Gaussians: Anti-Aliased and Artifact-Free 3D Gaussian Rendering" was accepted as a highlighted poster to #ICCV2025
TLDR: Enabling efficient training and rendering of 3DGS scenes without popping, distortion, and aliasing artifacts.
Logarithmic maps are incredibly useful for algorithms on surfaces--they're local 2D coordinates centered at a given source.
@yousufmsoliman and I found a better way to compute log maps w/ fast short-time heat flow in "The Affine Heat Method" presented @ SGP2025 today! 🧵
OMG. Yes, the new Personas are really that good. I did just one quick scan, and it’s already a quantum leap from before. There are also tons of new customisation options for the glasses.
I actually scared myself—I wasn’t expecting the Persona to just appear like that right after the scan finished 😂
Please never tell me Apple doesn’t innovate anymore—thanks.
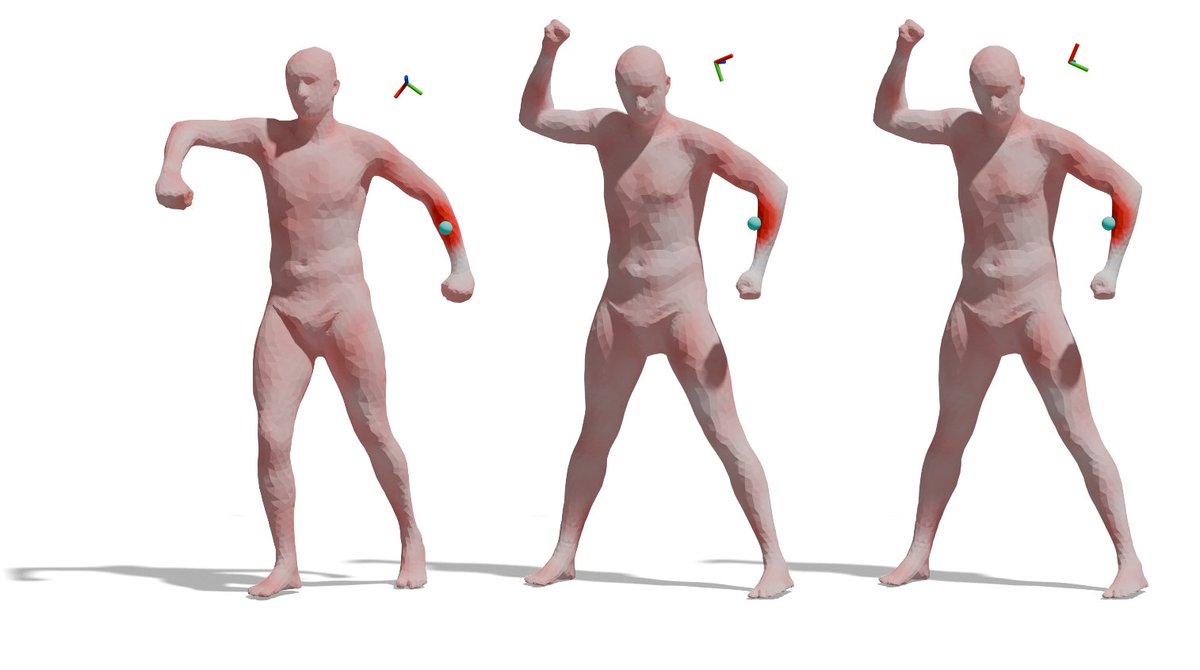
Laplace-Beltrami Operator for Gaussian Splatting
Contributions:
1. The definition of a Laplace-Beltrami operator that can be computed directly on Gaussian splatting, taking into account all information encoded by the variance.
2. We show a relationship between the eigenvalues of the LBO and the stable geometry of 3DGS, and how they can be used to determine convergence during optimization.
3. We experimentally demonstrate the effectiveness of this LBO on various geometry processing applications. Additionally, we will publish a variation of the popular geometry processing dataset [6]. In this dataset, we generated renderings and 3D Gaussian splatting reconstructions of all shapes, including correspondences between both, to facilitate further research on geometry processing applications using 3DGS.
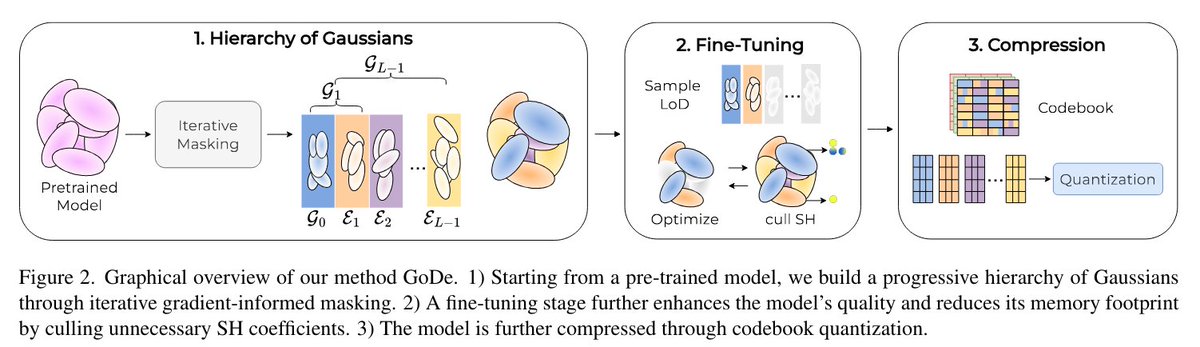
GoDe: Gaussians on Demand for Progressive Level of Detail and Scalable Compression
Contributions:
• A general method for progressive LoD: Leveraging a novel gradient-based iterative masking technique, we show the applicability of this method to a variety of popular 3DGS models (Sec. 4.2). This approach effectively organizes primitives into a hierarchy of progressive levels compared to other methods (Sec. 4.4.2).
• Smooth transition between levels: Our fine-tuning procedure offers a simple and effective way to reduce artifacts between levels, ensuring smooth transitions in visual fidelity across multiple LoDs (Sec. 4.3) and boosting LoD quality (Sec. 4.4.3).
• Scalable Compression: Our method integrates and extends state-of-the-art compression techniques, enabling scalable compression and adaptive rendering, with performance that is comparable to, and sometimes even superior to, non-scalable methods (Sec. 4.4.4).
New dithering method dropped
I call it Surface-Stable Fractal Dithering and I've released it as open source along with this explainer video of how it works.
Explainer video:
https://t.co/DvqFVC9VE5
Source repository:
https://t.co/0d0ZKvc9Rh
#gamedev#vfx




















![janusch_patas's tweet photo. Laplace-Beltrami Operator for Gaussian Splatting
Contributions:
1. The definition of a Laplace-Beltrami operator that can be computed directly on Gaussian splatting, taking into account all information encoded by the variance.
2. We show a relationship between the eigenvalues of the LBO and the stable geometry of 3DGS, and how they can be used to determine convergence during optimization.
3. We experimentally demonstrate the effectiveness of this LBO on various geometry processing applications. Additionally, we will publish a variation of the popular geometry processing dataset [6]. In this dataset, we generated renderings and 3D Gaussian splatting reconstructions of all shapes, including correspondences between both, to facilitate further research on geometry processing applications using 3DGS.](https://pbs.twimg.com/media/GksqfDuW4AAahgr.jpg)
![janusch_patas's tweet photo. Laplace-Beltrami Operator for Gaussian Splatting
Contributions:
1. The definition of a Laplace-Beltrami operator that can be computed directly on Gaussian splatting, taking into account all information encoded by the variance.
2. We show a relationship between the eigenvalues of the LBO and the stable geometry of 3DGS, and how they can be used to determine convergence during optimization.
3. We experimentally demonstrate the effectiveness of this LBO on various geometry processing applications. Additionally, we will publish a variation of the popular geometry processing dataset [6]. In this dataset, we generated renderings and 3D Gaussian splatting reconstructions of all shapes, including correspondences between both, to facilitate further research on geometry processing applications using 3DGS.](https://pbs.twimg.com/media/GksqespWgAATH2a.jpg)
![janusch_patas's tweet photo. Laplace-Beltrami Operator for Gaussian Splatting
Contributions:
1. The definition of a Laplace-Beltrami operator that can be computed directly on Gaussian splatting, taking into account all information encoded by the variance.
2. We show a relationship between the eigenvalues of the LBO and the stable geometry of 3DGS, and how they can be used to determine convergence during optimization.
3. We experimentally demonstrate the effectiveness of this LBO on various geometry processing applications. Additionally, we will publish a variation of the popular geometry processing dataset [6]. In this dataset, we generated renderings and 3D Gaussian splatting reconstructions of all shapes, including correspondences between both, to facilitate further research on geometry processing applications using 3DGS.](https://pbs.twimg.com/media/GksqefVbkAMMPKU.jpg)




















![janusch_patas's tweet photo. Laplace-Beltrami Operator for Gaussian Splatting
Contributions:
1. The definition of a Laplace-Beltrami operator that can be computed directly on Gaussian splatting, taking into account all information encoded by the variance.
2. We show a relationship between the eigenvalues of the LBO and the stable geometry of 3DGS, and how they can be used to determine convergence during optimization.
3. We experimentally demonstrate the effectiveness of this LBO on various geometry processing applications. Additionally, we will publish a variation of the popular geometry processing dataset [6]. In this dataset, we generated renderings and 3D Gaussian splatting reconstructions of all shapes, including correspondences between both, to facilitate further research on geometry processing applications using 3DGS.](https://pbs.twimg.com/media/GksqfVjXEAAePbZ.jpg)





















