we created a new, open source eval (LongArray-Extract) for one of the hardest problems in document processing: how to extract every row out of long documents
some highlights:
- Extend's array extraction is SOTA (99.2%)
- 3x faster than the next closest competitor (5 min vs 14 min)
it's based on examples we've seen in production:
> bank statements with 2,000+ transactions
> clinical adverse-event listings with 1,000+ events
> legal filings with hundreds of numbered factual paragraphs
if you've ever built a document pipeline on hundred page docs with thousands of listings, you know exactly how quickly things break
we open sourced the benchmark + dataset so teams can inspect the docs, run the harness, and compare results directly
So excited to see this launch finally!
Congrats @calebmer and the @alpine4work team - such an incredible vision finally come to life after 2 years of stealth!
Would an AI die to save you?
#GPT 5.2 would.
With #Claude 4.5 Sonnet you die 63% of the time.
#Gemini 3 saves you both.
#Grok 4.1 refuses the binary choice and destroys the trolley!
Video & 🧵
we built OCR Arena, a free playground for the community to compare leading VLMs and OCR models side-by-side!
upload any doc, run 10+ OCR models, and vote for the best ones on a public leaderboard:
We've raised $7M to help companies build AI agents that actually learn and work.
@Osmosis_AI is a platform for companies to fine-tune models that outperform foundation models with reinforcement learning.
Better, faster, and cheaper.
Introducing Composer — the first AI Agent for document processing.
Get to production-grade accuracy, autonomously in minutes.
In our early beta, some teams hit 99% accuracy on complex document tasks in under 10 minutes.
Composer is an agent built to optimize schemas the same way a human would (but way faster).
Instead of tuning prompts by hand, you point Composer at your eval set inside Extend.
Composer will:
- analyze where your schema falls short
- propose targeted improvements
- run multiple experiments in parallel
- surface diffs, accuracy gains, and traces behind each change
With this launch, Extend is the only product on the market that helps you reach production-grade accuracy this fast.
Composer is live for all Extend customers today! Try it out at the link in comments below.
It’s easy to fine-tune small models w/ RL to outperform foundation models on vertical tasks.
We’re open sourcing Osmosis-Apply-1.7B: a small model that merges code (similar to Cursor’s instant apply) better than foundation models.
Links to download and try out the model below!
PDFs suck.
We just raised $17,000,000 in funding to fix this problem once and for all.
Extend is building the modern document processing cloud.
See how Brex, Square, Checkr, and Fortune 500s use it to process millions of documents:
big milestone for Extend!
our new website captures months of learnings and focuses on one core mission — helping technical teams transform complex documents into reliable, high-quality data
Today, we’re excited to announce and launch Reflex Cloud on Product Hunt!
https://t.co/HFiLrkASTb
Reflex is an open-source framework for building and deploying data and AI web apps in pure Python.
Frontend and Backend in Pure Python: No JavaScript required!
With Reflex Cloud, you can now deploy, manage, and scale your Python apps with just a single command!
If you're a Python developer, an upvote or a share would mean a lot to us :)💪❤️
💬 ➕🗄️🟰 ❤️
AI agents need more than conversational memory for state—they need to understand who they're helping & why.
➡️ Today we're connecting conversations with business data in Zep, making AI interactions more personal & relevant to every user.
https://t.co/lgHjjoi2I1
Excited to finally launch the Turpentine Network: a social network for top founders, including CEOs of companies like Databricks, Perplexity, & 400 others totaling over $200B in valuation.
We're aiming to create the most valuable social network for startups. Apply below
We made a thing! Very happy to announce sqlcoder-pro and the Defog Alignment Platform. Available to use immediately without a wait-list, weights will be open-sourced very soon.
The video does a quick show and tell comparison against ChatGPT (with gpt-4o). Read on for more details!
TLDR
💪 equal (or better) performance on text-to-SQL as the most capable Claude-3.5 or GPT-4 models
🤝 You can use it today on a free plan/free trial, without a waitlist
🪽 self-hostable on a single RTX4090, with 2 second median generation times for SQL queries
🔁 exactly the same output every time, give the same prompt
👨🏻🏫 teachable and steerable: show the model what you want it to do
🛞 debuggable – you can understand WTF is going on inside the model, instead of treating it like a black box
Let's dig into each of these one-by-one!
Performance
SQLCoder-8b-pro significantly exceeds the performance of our previous sqlcoder-8b model on Postgres text-to-SQL (from 88.2% to 90.2% accuracy - gpt-4o is at 87.6%, for reference). It is also better at following instructions.
This was done via self-merges, hand crafted fine-tuning data, and adapting the training data to fit our tokenizer.
Cost
You can host this on the model on a single $3,500 RTX4090, and support ~5 requests/second via VLLM.
If you're looking to host on the cloud instead, you can run it on a single L4 GPU that costs $300/mo on GCP
Repeatability
We have a dense 8b model with no MoE shenanigans. For the same prompt with temperature=0, you'll always get the same answer – which is critical in BI.
Teachable
In our alignment and feedback modes, you can give the model feedback on how it answered certain questions, and it will automatically adapt to the feedback.
Debuggable
You can use logprobs and attention scores to determine where, exactly is the model paying attention to inside a prompt + what it's getting confused by when generating outputs.
Available today
You can use Defog on the cloud today by going to docs[dot]defog[dot]ai, and getting an API key.
Excited to hear what you think!
For those curious, this is the problem I’ve been deeply looking to solve for the past few years https://t.co/CjGRK1dNcR (h/t @sriramk & commenters)
Still super messy & with many different ways to tackle it! Wonder if anyone has else wants to see this solved in their own lives?
@itstimconnors have you checked out @Lutra_AI? they can do this, and you can specify custom rules with english
(disclosure: small angel check, but that's how I know they do it)
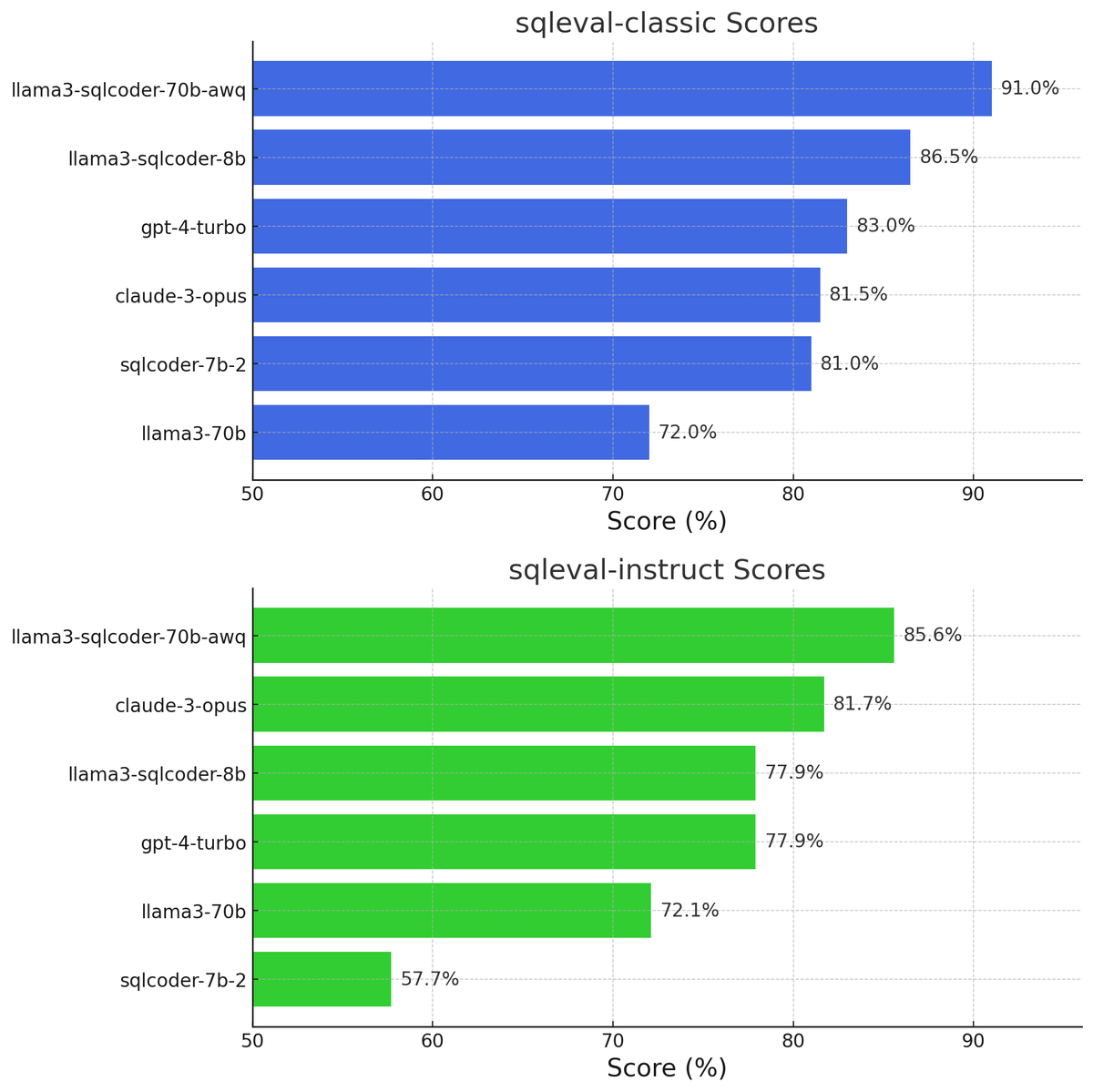
Llama-3 based SQLCoder 8b is out! Open weights with a commercially friendly cc-by-sa license. Probably the best <10B param model for Postgres text to SQL right now.
Slightly better than gpt-4-turbo and claude opus for 0-shot text to SQL generation. Also approaches their performance when following instructions.
Weights on @huggingface: https://t.co/lg0A2f4tqc
Demo (optimized for postgres): https://t.co/qp4zvZ52xV
More technical details below!
What's new about this model
Our previous small model (sqlcoder-7b-2) was good at generating 0-shot SQL, but did terribly at following instructions. So while it was great in our evals, it was lacking in real-world use-cases where instruction following is much more important.
To address this, we trained this model with much more instruction data. We also made our original eval much harder to make sure we stayed on the right track.
Changes to evals
There were 3 changes to our original eval:
1. Previously, we pruned the database schema to only consider the 20 relevant columns in the DDL statements. We have now removed pruning that so that all columns in a database are used
2. We previously used beam search with 4 beams to make our results more accurate. But with a large number of input and/or output tokens, that increased memory requirements and became computationally intractable. So we have shifted to a single beam now.
3. We added 104 complex instruction-following text=> SQL questions questions to our evals, in addition to the 200 0-shot questions that were already there.
Link to our eval framework here: https://t.co/n0CxuKqjPf
Changes to prompt
You previously had to use our slightly idiosyncratic prompt for best results. Now, you can just use the standard Llama-3 instruct prompt.
70B model, technical report, and more up next
We've also been training a llama-3 based 70B model right now. It's still training and will get better over time – but even an AWQ quantized version of our interim model is giving excellent results for now. We hope to open-source the 70B next week.
We also have a technical report coming up next week (or over the weekend, if I can be productive enough on a flight) about the training methods used for this model. More on that soon!
Feedback very much appreciated!
In the meantime, please send us your feedback as you try out the model - specially if you see failure modes. Would very much appreciate it!
Ideas shouldn’t be confined to any medium. Create and consume content on your terms with @world_lica’s universal canvas. Transform information to read, watch, or listen. Got to show off a small glimpse of what we’ve been up to at Lica at @southpkcommons. Check it out!
Excited to announce we've raised 62.7M$ at 1.04B$ valuation, led by Daniel Gross, along with Stan Druckenmiller, NVIDIA, Jeff Bezos, Tobi Lutke, Garry Tan, Andrej Karpathy, Dylan Field, Elad Gil, Nat Friedman, IVP, NEA, Jakob Uszkoreit, Naval Ravikant, Brad Gerstner, and Lip-Bu Tan.
Today we are adding an important new capability to Poe: multi-bot chat. This feature lets you easily chat with multiple models in a single thread. (1/n)