Decided to post a longer version of the asymptotic analysis draft from back in the day. The 'outer' solutions are the key here, but the inner expansions are always instructive to work out, together with the exponential integrals which were slightly fun.
https://t.co/hpox5t3MrI
Excited to introduce #TruckDrive 🚛 at #CVPR2026: a new long-range driving dataset built specifically for long-range truck autonomy, where safe braking and anticipatory planning demand perception hundreds of meters ahead, far beyond existing robotaxi datasets.
📦 TruckDrive includes:
🔹 475K samples, with 165K densely annotated frames
🔹 Benchmarks for end-to-end driving, tracking, planning, depth estimation, and up to 1,000m for 2D detection and 400m for 3D detection 📏🎯
🛰️ A purpose-built long-range sensor suite:
🔸 7 long-range FMCW LiDARs (range + radial velocity)
🔸 3 high-res short-range LiDARs
🔸 11× 8MP surround cameras for short and long-range📷
🔸 10× 4D FMCW radars 📡
⚠️ Key finding: current state-of-the-art models break down at long range
📉 with 31% to 99% drops on 3D perception tasks beyond 150m. TruckDrive exposes a long-range generalization gap that current architectures and training signals are not closing yet - a benchmark for the next generation of long-range highway autonomy research 🚚
🔗 Project and Data: https://t.co/fNzDCbGQRQ
Fun work together with @torc_robotics led by Filippo Ghilotti, Edoardo Palladin, Samuel Brucker, Adam Sigal, and Mario Bijelic.
This is a tutorial on diffusion and flow matching, based on my previous postings here. I’ve made available the PDF, a python notebook for people to play with it, and the TEX source so hopefully one of you can translate to your language. https://t.co/zVKhamyIte
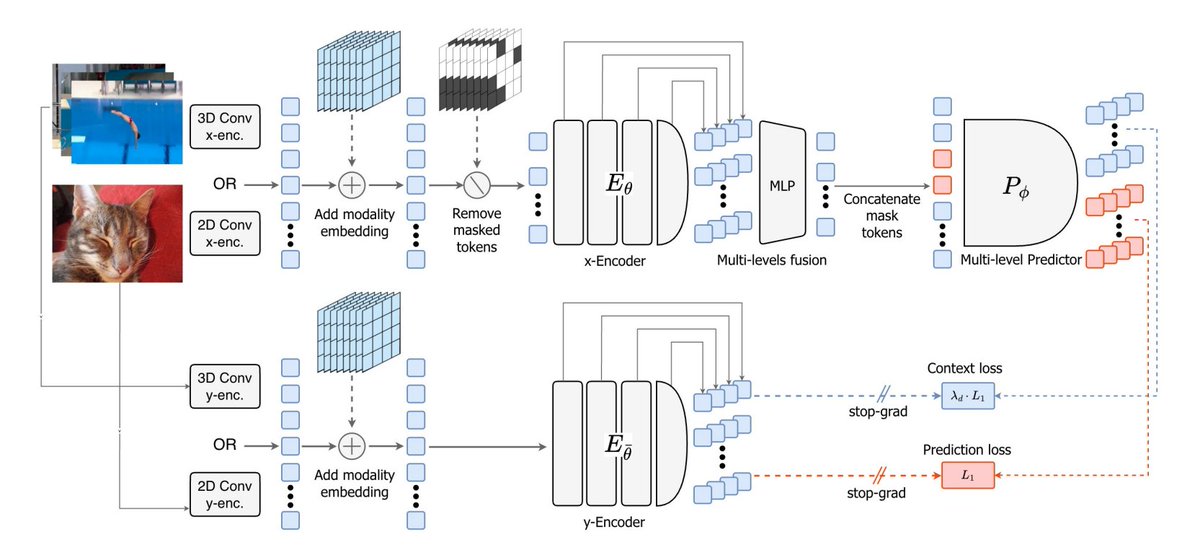
A new paper from @ylecun and others – V-JEPA 2.1
It changes the recipe of V-JEPA so the model learns both:
• Global semantics – what is happening in the scene
• Dense spatio-temporal structure – where things are and how they move
The idea is to supervise not just masked tokens but the visible ones too
There are 4 key ingredients for V-JEPA 2.1:
- Dense prediction loss on both masked and visible tokens
- Deep self-supervision across intermediate layers
- Modality-specific tokenizers (2D for images, 3D for videos) within a shared encoder
- Model + data scaling
The workflow turns into: masked image/video → encode visible tokens → predict latent representations for both masked and visible tokens → supervise at multiple layers
Here are the details:
The frontier has increasingly shifted to hybrid models - from Qwen to Kimi-Linear and now with NVIDIA's Nemotron-3 Super - that rely on a strong linear sequence model. Today we release Mamba-3, the most powerful linear model to date.
https://t.co/OpMmqEWMkP
@spbrunner hi @spbrunner can you also look at sagicor financial? it figures in norman rothary's lists in the globe and mail. it looks nice but not sure because of exposure to hurricanes.
@jeffrey_hawke The technical term "world model" (2018) corresponds to the "dynamics model" from control theory (1960). Sadly, it has become a "suitcase word". For those interested in the intellectual history, may I suggest my talk https://t.co/O3zzAbmIKb
@RealPeterLinder i dont like it that their dividend payout is so high and does not come from cash flows. i think (as a non-expert) there is some 'trust' involved in their ability to deliver and not just accessible through finance arithmetic.
@Kasparov63 i think much better in a real tournament setting with a real board. but maybe thats just the nature of the online beast, easy come easy go.