On an exciting journey to define the future of AI acceleration! AI Hardware Composer launches on two-year anniversary of IBM AI Hardware Center https://t.co/gOLBPQD7IT
#ibmresearch#ibm#aihw#ai#deeplearning
This is really a 'WOW' paper. 🤯
Claims that MatMul operations can be completely eliminated from LLMs while maintaining strong performance at billion-parameter scales and by utilizing an optimized kernel during inference, their model’s memory consumption can be reduced by more than 10× compared to unoptimized models. 🤯
'Scalable MatMul-free Language Modeling'
Concludes that it is possible to create the first scalable MatMul-free LLM that achieves performance on par with state-of-the-art Transformers at billion-parameter scales.
📌 The proposed MatMul-free LLM replaces MatMul operations in dense layers with ternary accumulations using weights constrained to {-1, 0, +1}. This reduces computational cost and memory utilization while preserving network expressiveness.
📌 To remove MatMul from self-attention, the Gated Recurrent Unit (GRU) is optimized to rely solely on element-wise products, creating the MatMul-free Linear GRU (MLGRU) token mixer. The MLGRU simplifies the GRU by removing hidden-state related weights, enabling parallel computation, and replacing remaining weights with ternary matrices.
📌 For MatMul-free channel mixing, the Gated Linear Unit (GLU) is adapted to use BitLinear layers with ternary weights, eliminating expensive MatMuls while maintaining effectiveness in mixing information across channels.
📌 The paper introduces a hardware-efficient fused BitLinear layer that optimizes RMSNorm and BitLinear operations. By fusing these operations and utilizing shared memory, training speed improves by 25.6% and memory consumption reduces by 61% over an unoptimized baseline.
📌 Experimental results show that the MatMul-free LLM achieves competitive performance compared to Transformer++ baselines on downstream tasks, with the performance gap narrowing as model size increases. The scaling law projections suggest MatMul-free LLM can outperform Transformer++ in efficiency and potentially in loss when scaled up.
📌 A custom FPGA accelerator is built to exploit the lightweight operations of the MatMul-free LLM. The accelerator processes billion-parameter scale models at 13W beyond human-readable throughput, demonstrating the potential for brain-like efficiency in future lightweight LLMs.
Check out our newly published work about the open-source Toolkit for In-memory computing: Using the IBM analog in-memory hardware acceleration kit for neural network training and inference https://t.co/g5Hr181O0f
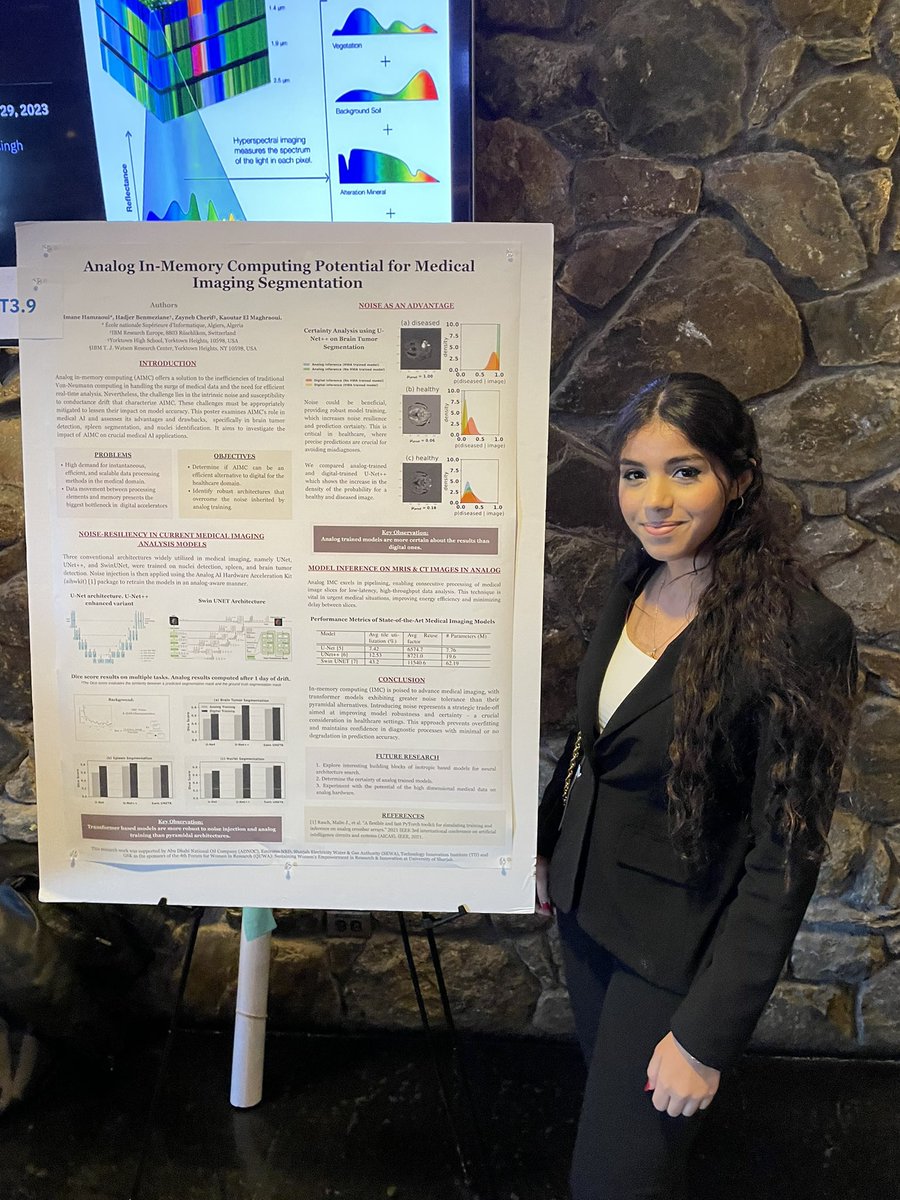
Congratulations to senior Zayneb Cherif for helping to publish a journal article and for presenting today at the 6th IBM/IEEE AI Compute Symposium! Thank you to IBM for allowing many of our sophomores to attend the event. @YHSDeGennaro@GOLLISZJOHN@RonHattar@CMillerYorktown
Congrats to @YClassof2024 Zayneb Cherif for achieving 3rd place at recent IBM/IEEE AI Compute Symposium Poster Session. Zayneb is a member of our @YHSSciRes program under the direction of our outstanding educators Mr. Rubeo & Mr. Seweryn.🌽🏆 @GOLLISZJOHN@earthscifanatic
Join @MoroccoAI for the AI Summer School at @AlAkhawayn University from July 17-21, 2023.
Learn from renowned speakers, apply by June 23 👉https://t.co/xa34HeEnaB.
Follow us for updates.
#AISummerSchool2023#AIEducation 🔥🌟🎓
IBM Quantum Summit 2022 kicks off tomorrow morning at 9:00am ET in New York City. Stay tuned for some major quantum announcements from our annual flagship event.
Construction has started on the IBM Quantum System on our main campus.
It will be the first quantum computer in healthcare, aimed at accelerating the pace of medical research.
Read more about our partnership with @IBMResearch: https://t.co/lfL4sPnAt0
Sept 28: 9AM-10:30AM ET = @SSUNGA_77. Rapid-fire lightening talks w/11 amazing #womenintech & rock star ally @abdulndigital. Don't miss our @UN General Assembly 77 Science Summit interventions! Register now & be there! https://t.co/K4TYwVuOvA