Excited to take the 👑 for TTS w/ @cartesia today!
Give it a whirl at https://t.co/hIjnWg5dwy in over 40+ languages and get in touch to learn more
Can’t wait to keep building the future of human-first AI across all modalities!
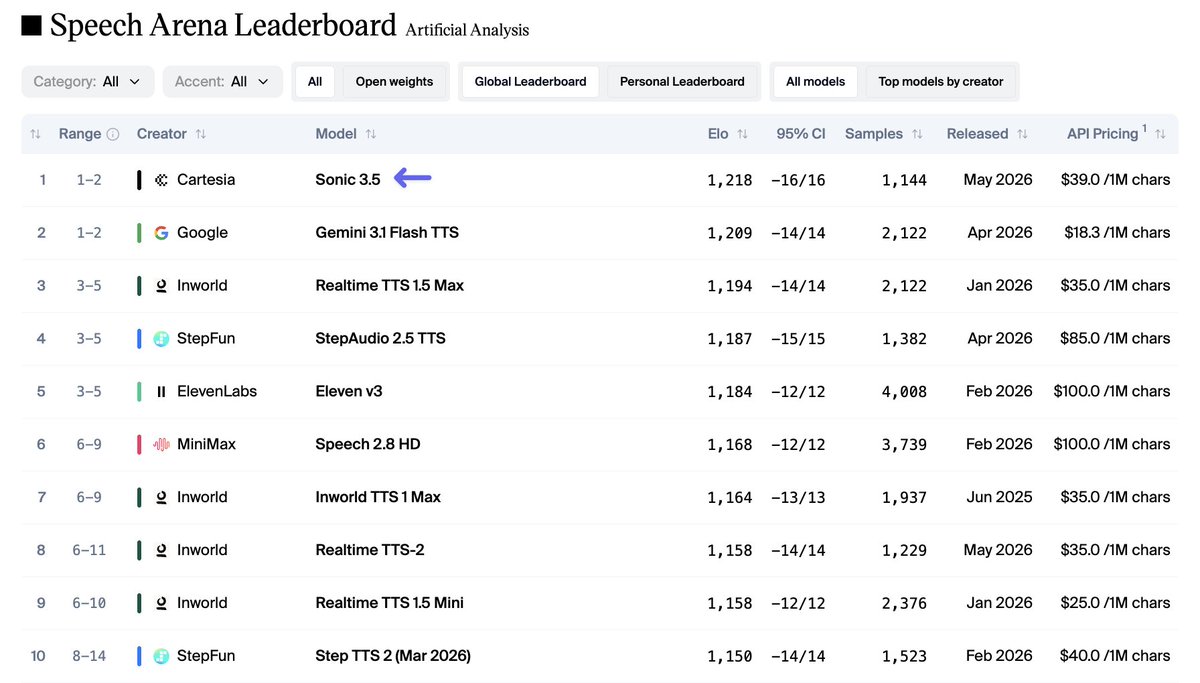
Cartesia’s Sonic-3.5 takes the #1 spot on the Artificial Analysis Speech Arena Leaderboard, surpassing Inworld Realtime TTS 1.5 Max and Google’s Gemini 3.1 Flash TTS
Sonic-3.5 is the latest TTS model from @cartesia . It supports 42 languages, including 9 Indian languages, with 500+ voices available out of the box. The model has been highly preferred among voters in the TTS Arena, with its demonstrated naturalness and accurate transcript following.
Key takeaways:
➤ Quality: Sonic-3.5 has an Elo score of 1,218 (+16/-16) based on 1,144 arena appearances, placing it ahead of Inworld Realtime TTS 1.5 Max at 1,194 and Gemini 3.1 Flash TTS at 1,209
➤ Pricing: Sonic-3.5 is priced at $39/1M characters, a premium compared to Gemini 3.1 Flash TTS at $18.3/1M characters, and Inworld Realtime TTS 1.5 Max at $35/1M characters
➤ Speed: 105.5 characters per second, compared to 205 characters per second for Inworld Realtime TTS 1.5 Max and 26.3 characters per second for Gemini 3.1 Flash TTS
See more details and listen to samples below 🧵
Cartesia has the best text-to-speech AND best speech-to-text models in the world. That’s really enough said - check out the demo below, and try them out at https://t.co/kXeTe8qv7c!
The story is always deeper than just a single benchmark - and when you break down how models actually fit into real product solutions or automations at scale, speed and quality require equal consideration
Some teams train good models. Some train fast ones.
We don't think you should have to choose.
Today at @cartesia we shipped two: Sonic 3.5 (speaking) + Ink 2 (listening). Both SOTA, both realtime.
90ms TTFA. 3.6% WER, #1 on AA. Try them out at https://t.co/8FxdqNLp8t
the post-transformer revolution will help bring your agents with you everywhere you go - and @cartesia is leading the charge to bring the most human, lowest latency, and highest throughput models into the real-world!
We released Sonic-3.5 and Ink-2, the #1 streaming models for text to speech and speech to text you can use in your voice agents today.
New architectures enable new frontiers for speed and quality.
We're now the only provider to have #1 models for both speaking and listening.
The bottleneck of frontier robotics isn’t compute, labeling, or the models themselves.
It’s data collection.
While language models scaled effortlessly on open internet text, robotics requires physical trajectories, motor torques, and tactile forces that cannot simply be scraped from a webpage.
Every token has to be fought for.
Here is a breakdown of the 7 data types shaping the industry today, each representing a trade-off between collection cost and action-label purity:
1. Real Teleoperation (AgiBot World, DROID). Collected by humans guiding hardware, it scales linearly with human hours.
2. Low-cost Capture (Mobile ALOHA, UMI handheld). It drives collection cost down while keeping real physics, though it introduces an embodiment mapping problem when transferring human hand actions to robotic joints.
3. Fleet / Deployment Data (Tesla Optimus, Figure). These are trajectories from robots already working in the field. Tesla is betting its automotive fleet infrastructure transfers to Optimus. It generates powerful, real edge cases, but requires scaled deployment.
4. Simulation (NVIDIA Isaac Sim, Genesis). While offering near-infinite scale, the sim-to-real gap still struggles to model contact-rich dynamics like slipping, twisting, friction.
5. World-Model Synthetic (NVIDIA Cosmos 3). NVIDIA just shipped Cosmos 3, which natively outputs action trajectories, not only video pixels. If a world model can accurately simulate the laws of physics natively, it reduces the need for manual teleop data drastically.
6. Egocentric video (Ego4D, Meta’s Project Aria). First-person human video captured with head-mounted rigs. Far more scalable than teleop and closer to a robot’s own viewpoint. Still carries no robot action signals on its own.
7. Internet video (Youtube, TikTok). Maximum scale, lowest cost, effectively free. It captures the widest range of objects, tasks and physical situations, but with zero action labels and (mostly) a third-person viewpoint.
Collecting data is only the step one.
The next great execution challenge is engineering a coherent training recipe that can blend these heterogeneous data sources into a single model.
It's truly insane that it's even possible to build software as bad as the Claude Code and Codex CLIs are. AI has opened up whole new capabilities that I never would have foreseen
meta gave their AI support agent the ability to modify your instagram account. no identity verification. people figured this out and accounts are being taken over right now
if you're under 50 and you stay healthy, i think you will live to 150 years old minimum
the medical singularity is happening.
just in the past 2 months alone:
> revmed's pancreatic cancer drug (daraxonrasib) doubled survival in the deadliest cancer there is, 13.2 months vs 6.7 on chemo. it got a standing ovation from 40k+ doctors at the world's biggest cancer conference
> a one-time gene editing infusion (verve-102) permanently switched off the gene that drives bad cholesterol and cut it up to 62% from a single dose. one and done, no daily pill for life
> a lung cancer pill (lorlatinib) kept 60% of patients with spread cancer progression-free at 5 years. the longest anyone has ever held back a metastatic solid tumor with a single drug
> mayo built an ai that catches pancreatic cancer on routine ct scans up to 3 years before doctors can. it spotted 73% of the earliest cases vs 39% for human radiologists
> lilly's new weight loss drug (retatrutide) hit up to 30% body weight loss in its big phase 3 trial, and along the way it cut knee arthritis pain by 76% and dropped bad cholesterol about 20%
and we are still just at the beginning of the exponential
call me crazy but i'm a believer when Demis hassabis says we will cure all disease in the next 10 years
new grads often ask me what they should be doing so they don't fall behind in the ai space. there's a lot, but its honestly super manageable. become intimate with model internals. proof based linear algebra. non-convex optimization. this is stuff you could've done in undergrad. it definitely takes some time and work, but its doable. have taste, have opinions. train a small model, then train a big one. vLLM internals, tensor parallelism. hand roll kernels. cluster orchestration. do you have opinions on synthetic data? why don't you? SFT, PPO, you should know this. learn Triton. everyone is reproducing papers now so you need to be doing more. do you know the semi supply chain? where are the bottlenecks? hardware, man, hardware. your little gpu rig erector set in your basement isnt gonna cut it. build a cluster, a big one. pretrain a 800B model. now postrain it. serve it to millions of people. you should be able to beat deepseek on some benchmarks now. its a lot to take in but it all snowballs. this what job security looks like from now on. do you want to work in tech or not
Incredibly proud of the @cartesia team for this tremendous achievement - 2 different models in two weeks.
AI Models for Speech to Text (STT) is not just about transcribing words - though that is essential.
If you're using STT in conversational AI Voice Agents then you need speed, accuracy, and - ideally - the ability to accurately detect when a user has started, finished , or resumed speaking.
If the terminology is not clear, I've added a link in the thread to a glossary I created when learning this stuff.