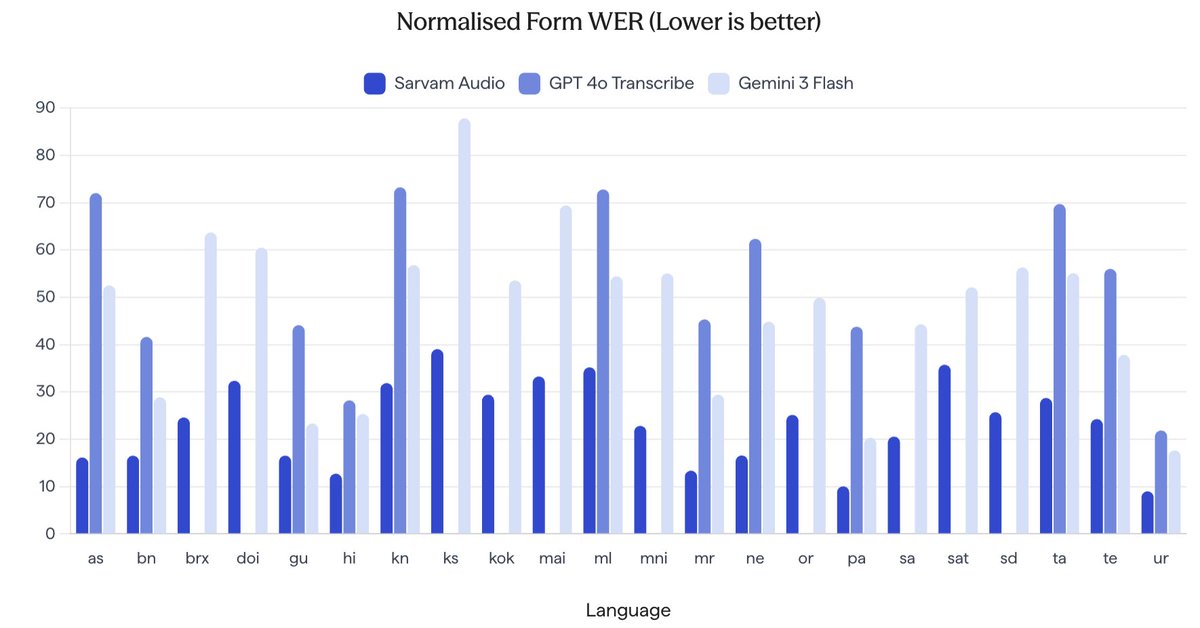
Drop 2/14: Sarvam Audio: a state-space based efficient audio language model that defines the new benchmarks in speech recognition for Indian languages. Significantly outperforms Gemini 3 and GPT 4o Transcribe in a range of benchmarks. See details in our blog: https://t.co/GFcklhteKJ
@SarvamAI
Sarvam Audio is trained on top of Sarvam 3B a large language model trained from scratch by @SarvamAI supporting 22 Indian languages and English. The model aces fine control of transcripts amongst various different formats, achieving the lowest word error rates across languages.
Drop 1/14: We pulled off a first of its kind. The budget speech by the Finance Minister was live telecast in multiple languages on @republic. Reached millions of homes with a latency under 2 minutes. https://t.co/EgGp4CJ1On
📣 📣 📣 New instruction-tuned LLM! 📣 📣 📣
Today, we announce an initial release of "Airavata", an instruction-tuned LLM for Hindi.
Blog: https://t.co/JtmVZIpVS9
Model: https://t.co/MVpTA0UWEZ
Datasets: https://t.co/avtGcvYT2v
(1/N)
How to multitask?
Feeling overwhelmed with multiple tasks on your to-do list? 😩
How do we effectively manage and juggle between tasks? 🤹 🤹♂️ 🤹♀️ Some tips below.👇
We are glad to announce the new version of ESPnet (v202209). There are several interesting changes, including a new task in SLU, several new models, various recipes, etc. Many thanks to our contributors 🔥🔥🔥 More details in https://t.co/81fsOMRVas
We’re pleased to introduce Make-A-Video, our latest in #GenerativeAI research! With just a few words, this state-of-the-art AI system generates high-quality videos from text prompts.
Have an idea you want to see? Reply w/ your prompt using #MetaAI and we’ll share more results.