Tokenized on day one.
The largest IPO in history is being tokenized on day one, accessible across leading blockchains, like @solana.
SPCXon, coming to Ondo Global Markets.
Claude Opus 4.8 is out today. It's our strongest coding model yet: up on SWE-bench Pro (from 64.3 to 69.2) and noticeably more honest about its own work. It tells you when it's unsure and catches its own bugs instead of declaring victory early. Same price as 4.7.
The context locked in senior engineers' heads is the bottleneck. A retrieval layer surfaces it.
Keeping it in sync with what ships is the harder problem, and the one our Software Factory's Knowledge Graph solves: capture the intent, enforce it from requirements to tested code.
Try out Software Factory: https://t.co/YnLbBjlNE5
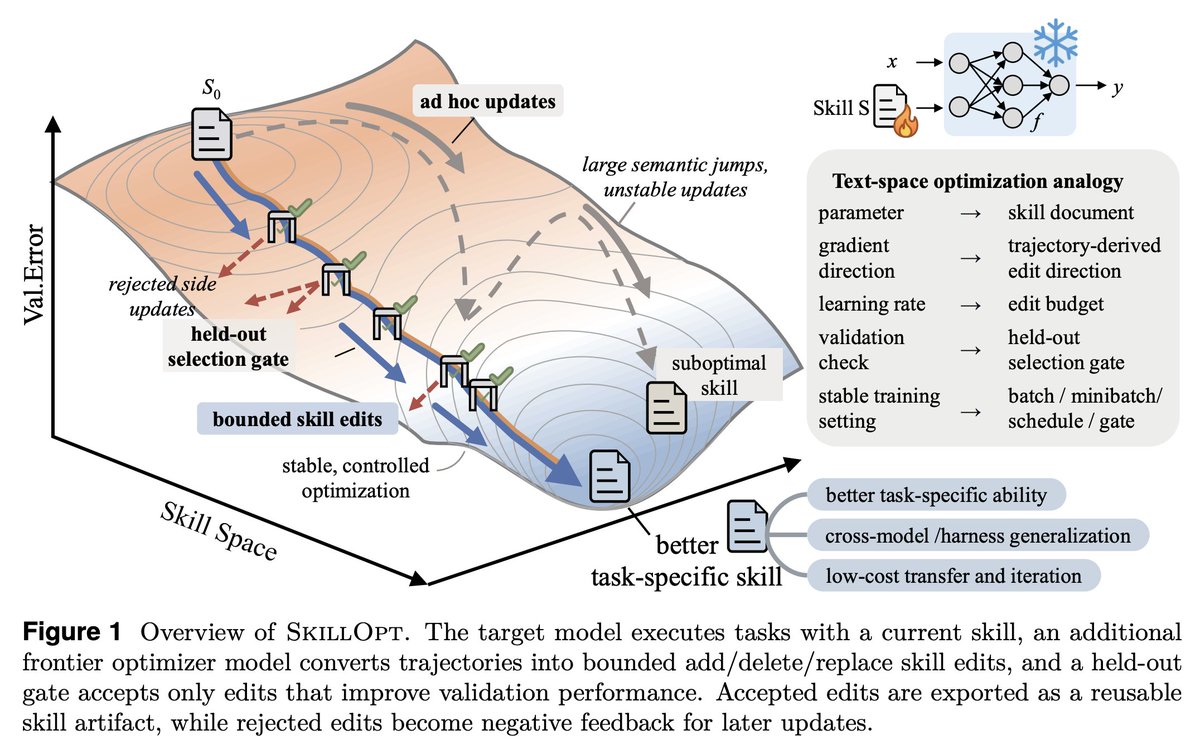
Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness.
SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them.
A few things I learned that you should consider too.
1. The validation gate is the only thing that matters in a self-editing loop.
Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop.
2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot.
Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size.
3. Compactness wins. Median final skill: ~920 tokens.
Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't.
4. The harness is becoming less important; the skill is becoming more important.
A Codex-trained skill ported into Claude Code hit +59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that
produced it.
5. Frozen model + trained context is the practical adaptation.
GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is
the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models.
6. Verification is the bottleneck.
Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage.
There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7,
gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK:
- Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it.
- Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is.
Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured.
The fast/slow split they describe already lives implicitly in the digital-brain-skill repo:
- voice-guide and tone-of-voice.md are slow-state (rarely touched)
- posts.jsonl and bookmarks.jsonl are fast-state
What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing.
If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: https://t.co/ZS9SZXQ6Mv
🚗🇨🇳 While everyone debates FSD in the U.S., it’s already out there handling chaotic Chinese streets with ease.
The robotaxi future is training hard in the world’s toughest driving environments.
China might be the ultimate proving ground. Impressive.
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc.
More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage:
1) raw text (hard/effortful to read)
2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default
3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default
...4,5,6,...
n) interactive neural videos/simulations
Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral https://t.co/z21CP5iQfu
There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen.
TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
Tesla Cybercab will be the most efficient ever made.
Lars Moravy, Tesla’s VP of Vehicle Engineering, confirmed Cybercab has a certified 165 Wh/mi efficiency.
Here’s how that compares to the rest of the Tesla fleet (figures are directly from Tesla’s configurator).
The thesis is simple: the future belongs to individuals who build compounding AI systems, not to individuals who use corporate-owned centralized AI tools.
I'm trying to build these in open source so you can have them for free. That's what GBrain is.
@iriscibre Her seçim öncesi Türkiye’yi karıştırmaya çalışan Banka raporları ve bunları yaymaya bayılan, sözde Atatürkçü kesim - artık sosyal medyada baymaya başlamadı mı?
Turkey just announced one of the most aggressive investor relocation packages in the world.
Zero tax on foreign income for 20 years. Capital gains on your overseas portfolio? Covered. Inheritance tax? Slashed to almost nothing. Corporate tax for exporters? Dramatically reduced.
This isn't a tweak. It's a full repositioning. Turkey is now competing head-to-head with the world's top tax-optimized jurisdictions for capital and talent.
The bottom line?
Capital doesn't have a passport. It moves where it's welcomed.
Governments are finally waking up to a truth that wealthy investors figured out long ago:
Money flows to where it's treated best.
The race to the top has started. Or maybe the race to the bottom... depending on which side of the tax bill you're on.