Now this paper has been accepted to #ICLR2023 as a spotlight🌟! I truly appreciate everyone's efforts. Check out our repo https://t.co/zjGbmLtZYI for the latest demo video and updates! Title: "Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling"
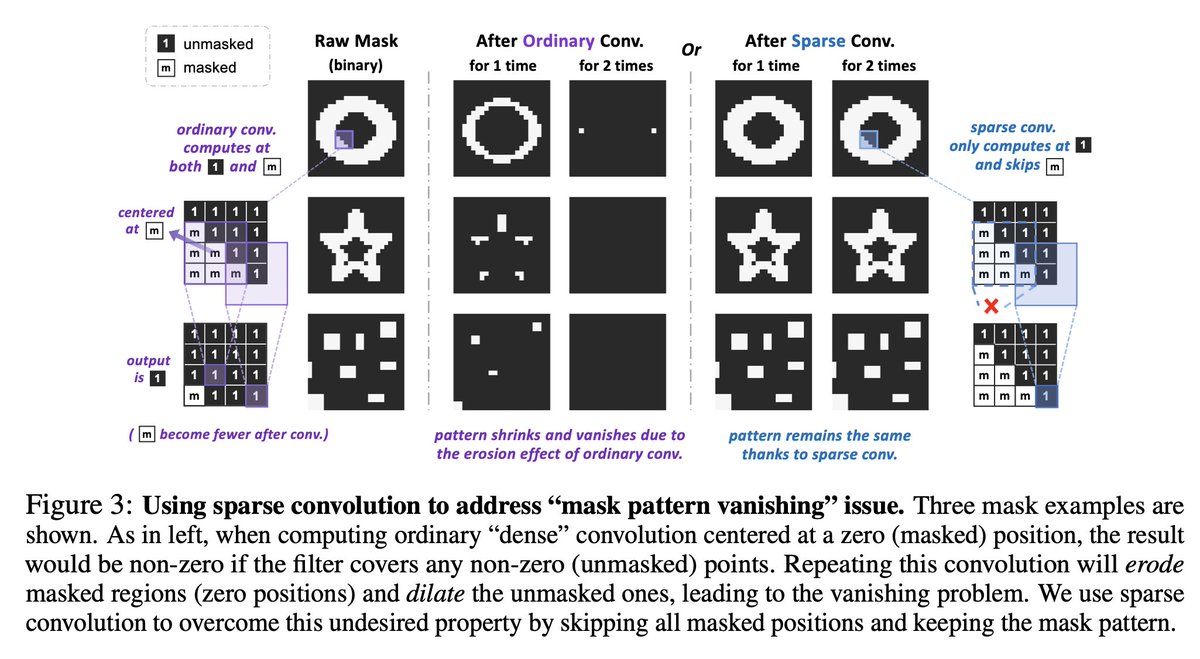
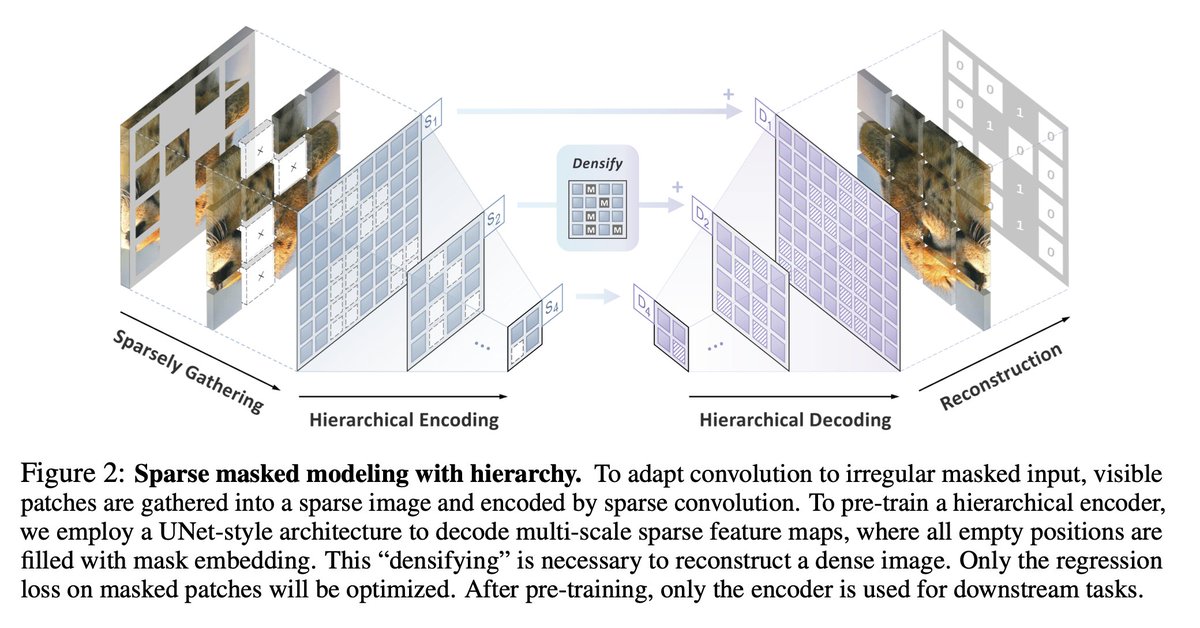
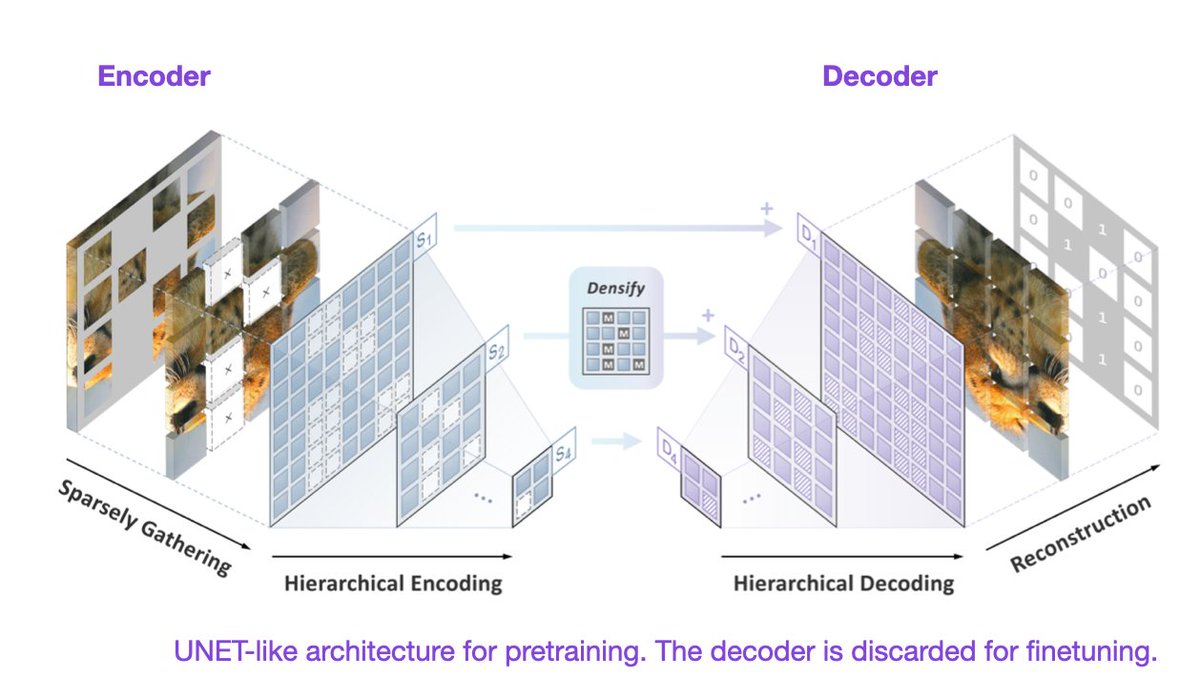
How can we leverage successful pretraining techniques from transformers to improve purely convolutional networks? The answer is *Sparse Convolutions*!
Let's see what happens when purely convolutional networks are pretrained with 1.28 million unlabeled images ...
1/7
SparK - [ICLR'23 Spotlight] The first successful BERT-style pretraining on any *convolutional network*; Pytorch impl. of "Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling" https://t.co/vdgxhmPxS1
@foozlefoo Thanks, we're glad SparK may be helpful to your project! Sorry we delayed the update for a few days because it's Lunar New Year today, we'll get back to you as soon as they're posted.
PS: our original submission in Oct. 2022 was titled "Sparse and Hierarchical Masked Modeling for Convolutional Representation Learning"; we've changed it to the new one to more clearly express our vision for bringing the powerful BERT-style self-supervised learning to CNNs.
@rasbt Thank you so much! Your notes are really helpful in letting people know about what we do! And I'm glad to see this work has the opportunity to make a meaningful contribution to our community.
@reidatcheson@rasbt Thanks for your interest! We are writing a google Colab tutorial to make it easy to play with our pre-trained models (e.g. to reconstruct the images you upload). We'll release it before this weekend and hope it can be helpful.
@rasbt Yeah, that's true for point 2. It'd be better to say "CNNs achieved higher performance than Transformers".
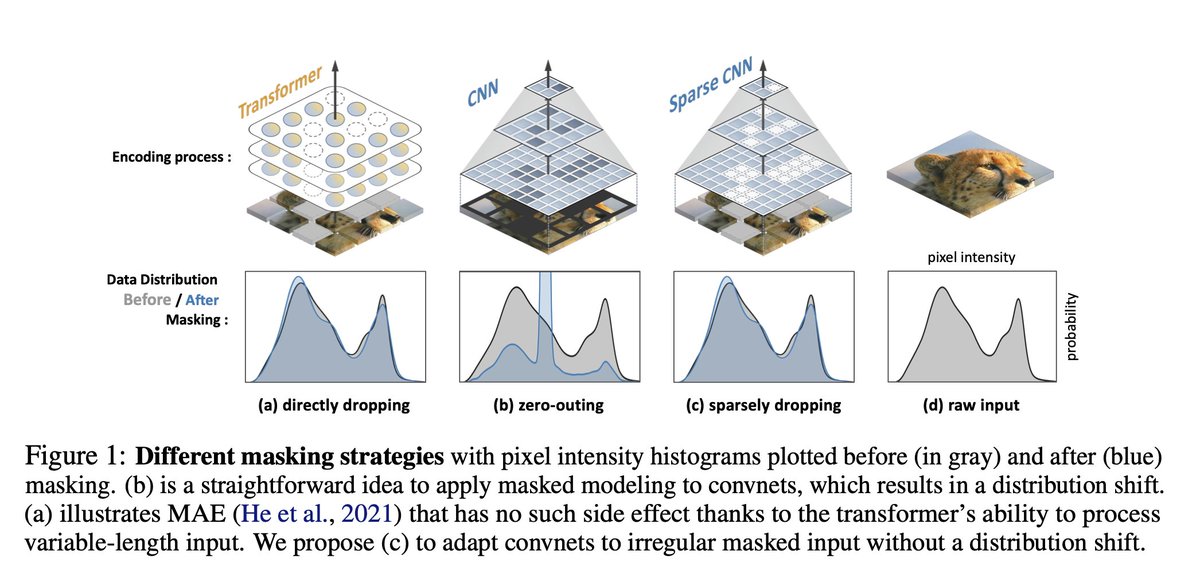
BTW, I really appreciate the contrastive idea, which seems more natural for image data than randomly masking. But it turns out the BERT-style pretraining is more effective.
How can we leverage successful pretraining techniques from transformers to improve purely convolutional networks? The answer is *Sparse Convolutions*!
Let's see what happens when purely convolutional networks are pretrained with 1.28 million unlabeled images ...
1/7
[CV] Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling
K Tian, Y Jiang, Q Diao, C Lin, L Wang, Z Yuan [Peking University & Bytedance Inc & University of Oxford] (2023)
https://t.co/TJwQep1Has
#MachineLearning#ML#AI#CV
[1/2]
@HappyToKnowThat@jamesr66a it's kinda like the number of neurons in a brain, the more, the smarter. And each parameter is a float in Java, so you can imagine how much memory it takes.
🤩The first successful BERT-style #SelfSupervisedLearning on any convolutional network! #ResNet now enjoys masked autoencoding! 🚀A breakthrough paper "Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling" by @keyutian et al.
https://t.co/YmnyCsOKHj
@kzmolikova@rasbt Thanks for noticing this, that is our work which's been on OpenReview since Oct. 2022 (https://openreview. net/forum?id=NRxydtWup1S), and uploaded to arxiv recently.
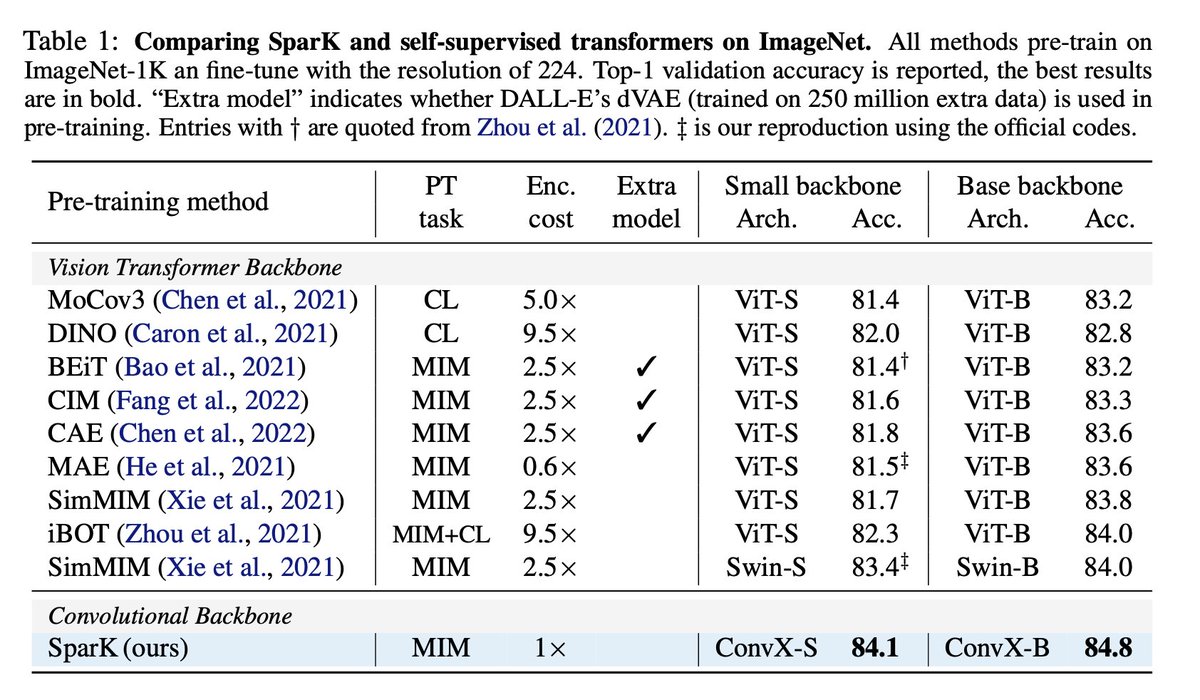
It gives some different results from ConvNeXt v2, e.g., our method works pretty well on ConvNeXt v1 and ResNet.






![fly51fly's tweet photo. [CV] Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling
K Tian, Y Jiang, Q Diao, C Lin, L Wang, Z Yuan [Peking University & Bytedance Inc & University of Oxford] (2023)
https://t.co/TJwQep1Has
#MachineLearning #ML #AI #CV
[1/2] https://t.co/erswznpp2X](https://pbs.twimg.com/media/FmdtNxyX0ActBEs.png)
![fly51fly's tweet photo. [CV] Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling
K Tian, Y Jiang, Q Diao, C Lin, L Wang, Z Yuan [Peking University & Bytedance Inc & University of Oxford] (2023)
https://t.co/TJwQep1Has
#MachineLearning #ML #AI #CV
[1/2] https://t.co/erswznpp2X](https://pbs.twimg.com/media/FmdtNxwXgAAQ04s.jpg)
![fly51fly's tweet photo. [CV] Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling
K Tian, Y Jiang, Q Diao, C Lin, L Wang, Z Yuan [Peking University & Bytedance Inc & University of Oxford] (2023)
https://t.co/TJwQep1Has
#MachineLearning #ML #AI #CV
[1/2] https://t.co/erswznpp2X](https://pbs.twimg.com/media/FmdtNxvWIAAJrpu.jpg)



















![fly51fly's tweet photo. [CV] Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling
K Tian, Y Jiang, Q Diao, C Lin, L Wang, Z Yuan [Peking University & Bytedance Inc & University of Oxford] (2023)
https://t.co/TJwQep1Has
#MachineLearning #ML #AI #CV
[1/2] https://t.co/erswznpp2X](https://pbs.twimg.com/media/FmdtOKVWQAUCoC_.jpg)