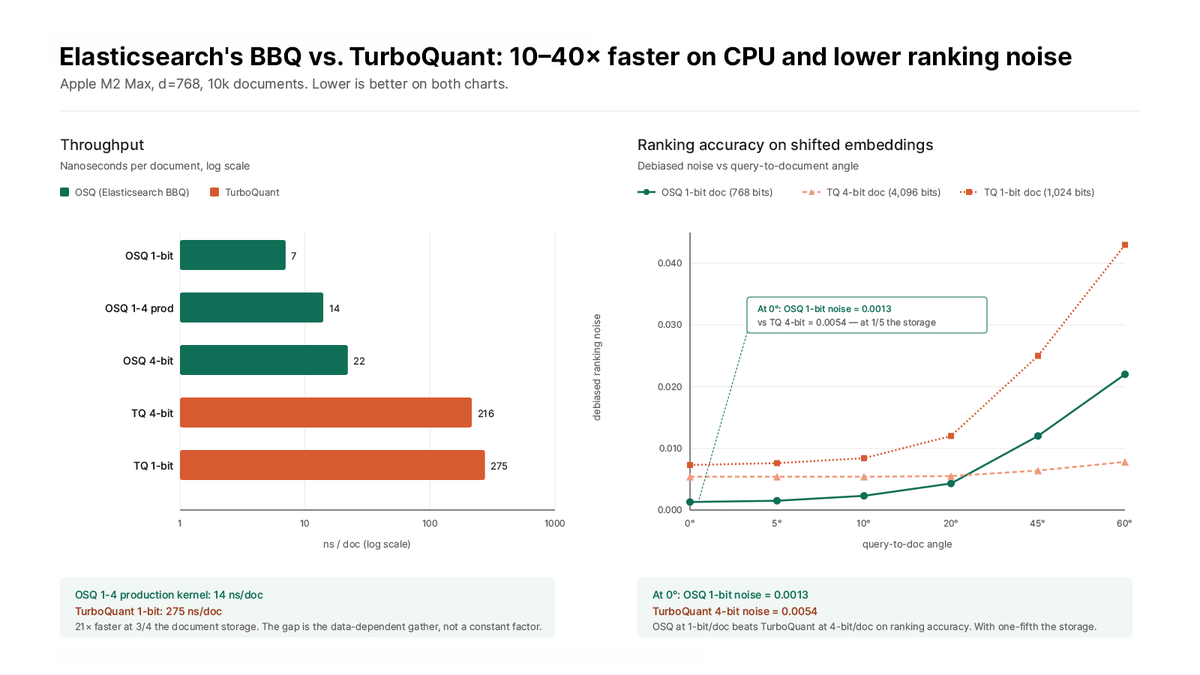
When turboquant came out, it got a lot of justified excitement. We took it for a Spin, and our year long work on Elasticsearch BBQ (better binary quantization) holds up better, especially in the abundant world of CPUs.
* also, we need to get Thom an upgrade from M2 ;)
🧵 Our BBQ at 1-bit/doc beats TurboQuant at 4-bit/doc on shifted data on ranking accuracy.
At 1/5 the storage.
We center on the segment centroid before quantization, so the bits go where they are actually needed for ranking. TurboQuant's Hadamard rotation can't exploit that structure.
Filtered vector search with restrictive filters just got 3-5x faster. Close to 10x on hyper-restrictive ones.
The old flow scored centroids without knowing if they contained matching vectors, loaded postings lists for nothing, decoded doc IDs that didn't pass the filter, and repeated until it had enough results.
The fix in Elasticsearch 9.4: a doc_id-to-centroid mapping that lets DiskBBQ skip straight to clusters with relevant vectors. Latency used to spike as filters got tighter. Now it stays flat or drops.
30x faster than Prometheus on gauge averages sounds like a typo. It's not.
Elasticsearch 9.4 rebuilt TSDS and ES|QL into a fully columnar metrics engine. Vectorized time series aggregations, zero-copy decoding, doc value skippers replacing inverted indices.
The result at 1.4M time series: queries that took Prometheus 30+ seconds finish in under 2.
jina-embeddings-v5-omni is now on Elastic Inference Service.
Text, images, audio, video. One index, one query.
• Best-in-class visual understanding under 1B parameters
• Beats models 20x its size on multilingual visual tasks
• Beats ByteDance Seed 1.6 on video (55.57 vs 29.30 on Charades-STA)
• BBQ quantization: 93% storage reduction, under 3% accuracy loss
• nano runs on commodity hardware without GPU
Introduction below with @florianhoenicke
30x faster than Prometheus on gauge averages sounds like a typo. It's not.
Elasticsearch 9.4 rebuilt TSDS and ES|QL into a fully columnar metrics engine. Vectorized time series aggregations, zero-copy decoding, doc value skippers replacing inverted indices.
The result at 1.4M time series: queries that took Prometheus 30+ seconds finish in under 2.
Lots of noise around TurboQuant. It is good at MSE quantization. But claims around unique groundbreaking results are exaggerated. As it stands, I don't think it should be used for vector search indices. Tom Veasey shows why: https://t.co/EJREzonWig
95 ns/vector vs 412 ns, Elasticsearch simdvec VS jvector scoring float32 at 32,500 vectors on x86.
But the number isn't really the story here. The story is that at scale, past L3 cache, memory latency beats compute every time and simdvec is built just for that.
At this depth, the kernel spends more time waiting for data than processing it. Prefetch too early and you've wasted the slot. Too late and you're stalling anyway. The window is narrow and simdvec times it right.
Explicit prefetch instructions on x86 pull the next vectors into cache while the current batch is still scoring. On ARM, interleaved loads do the same job differently. Either way, the pipeline stays fed.
Hardware counters show what that buys: 139K L1 cache misses drop to 19K. That's where the 4x gap lives.
The simdvec team wrote up the full architecture and benchmarks, including their hardware counter data.
Native promql support for metrics in Elasticsearch, fused right into our ES|QL so you can optionally fuse it. Pretty cool and tons of more metrics news (perf! Moar columnar!) coming soon!
If your team lives in PromQL, you no longer have to context-switch to query your Elasticsearch metrics.
The new PROMQL source command in ES|QL lets you run PromQL queries directly against Elasticsearch time series data, whether ingested from Prometheus Remote Write, OpenTelemetry, or other sources. Because it's built on the ES|QL engine rather than a separate query layer, PromQL output can be piped into filters, sorts, joins, and enrichments.
That's not something you can do in Prometheus.
The Axios attack again proved the status quo is broken. We caught it by using AI to diff package repo updates. Built Friday, caught the compromise Monday.
We open sourced the project so the community can iterate on it. We all need a higher floor for defense.
We open sourced the tool used to detect the Axios supply chain compromise! I built it Friday after a red eye home from RSAC. Also, wrote up the full story, including the hectic moments after that first critical alert
https://t.co/HAm8eMr8vO
We have discovered a massive supply chain compromise in the Axios npm package.
A backdoored maintainer account delivered a cross-platform RAT for Linux, Windows & macOS, targeting the Axios package, which has ~100M weekly downloads and is in the top five most popular Node.js packages.
We filed a GitHub Security Advisory to coordinate the disclosure, ensuring that the maintainers and the npm registry could act swiftly on the compromised versions.
Full analysis: https://t.co/XFHWdjXJT3
jina-embeddings-v5-text is here! Our fifth generation of jina embeddings, pushing the quality-efficiency frontier for sub-1B multilingual embeddings. Two versions: small & nano, available today on Elastic Inference Service, vLLM, GGUF and MLX.
We've got two days left to get these folks on at @SXSW! 👇
🌟 @MichelTricot — CEO & Co-Founder, Airbyte
🌟 Shay @kimchy Banon — CTO & Founder, @Elastic
🌟 @LindaMLian — CEO & Co-Founder, @CommonRoomHQ
🌟 Paul @kiwicopple Copplestone — CEO & Founder, @Supabase
Do your part by voting for them here: https://t.co/cN1tpRNq7P
If you do, they'll share how open-source communities offer a competitive edge, fueling faster innovation, unlocking developer mindshare, and laying the foundation for enterprise adoption.
OpenSearch moves away from Lucene, while we work hard to make Lucene and Elasticsearch better, the difference between faking it and actually building https://t.co/qTvOTduZ77