NVIDIA just dropped Nemotron-3.5-ASR: one 0.6B model, 40+ languages, streaming.
parakeet.cpp already runs it. On a plain CPU, 2.5x faster than @NVIDIAAI 's Nemo runtime, output byte-for-byte identical (WER 0).
No GPU needed. Offline or real-time. Pick a language with --lang, or auto.
GPU numbers are coming to compare with Nemo framework.
The new @GoogleColab bridges the gap between local environments and the cloud, providing a zero-friction execution platform for developers and AI agents alike. The CLI Supports:
⚡️ Agent-driven Colab workflows
⚡️ Instant GPU/TPU provisioning
⚡️ Remote script execution
⚡️ Interactive runtime access (console/REPL)
Learn more in the blog: https://t.co/n8TOYStlrp
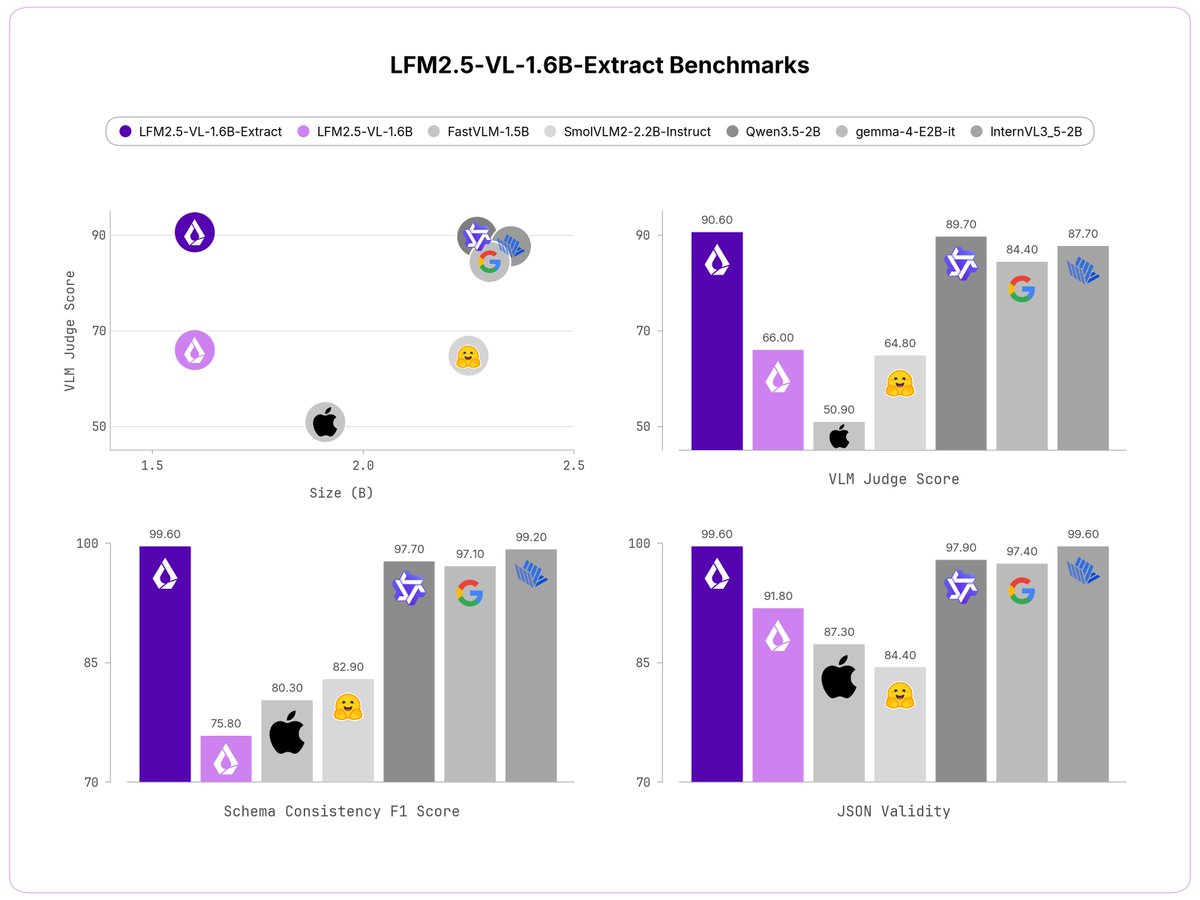
Introducing LFM2.5-VL-1.6B-Extract and LFM2.5-VL-450M-Extract: Vision-language models that return structured JSON, not free-form text.
Pass in an image and a list of fields. Get back a clean JSON object.
> Two sizes: 1.6B parameters and 450M
> open-weight
> run on any device SoC
🧵
Higgs Audio v3 TTS is here.
Built for voice AI that speaks, not just reads:
• 100 languages with single-digit WER/CER
• inline control over emotion, style, prosody, and sound effects
• API, Workspace, and open weights
• Blog 👉 https://t.co/C8frDlfO5D
Watch the demo 👇
We’ve been researching new ways for ChatGPT memory to carry context across conversations and keep it useful over time.
Today, that work is rolling out as a more capable memory system in ChatGPT. https://t.co/0MyFKCe2Mu
Second big release from us today: Nemotron-3.5-ASR-Streaming!
🌎40 languages
⚡️80ms - 1s controllable latency
🔥240 - 2400 concurrent streams on 1xH100
🧱FastConformer Cache-Aware RNN-T architecture
https://t.co/lxmcAnKeOl
Introducing Ideogram 4.0: the best open image model in the world.
Think it. Make it. Own it.
Download the weights, fine-tune on your own data, and run it on your hardware. Live on every Ideogram plan and the API today.
We’re launching Gemma 4 12B: Our unified, encoder-free model that brings powerful multimodal intelligence straight to your laptop 🚀
The model bridges the gap between our mobile E4B model and larger 26B MoE models, packaging frontier-class reasoning and native audio into a highly optimized footprint, all under a permissive Apache 2.0 license.
Here’s what makes it unique:
+ Encoder-Less Architecture: We removed the multimodal encoders. The vision and audio inputs flow directly into the LLM backbone.
+ Agentic Performance (16GB VRAM): Run complex, multi-step workflows locally, with performance nearing our 26B model.
Seven new models launching at Build: let’s go!
Reasoning. Code. Image. Transcribe. Voice.
Built from scratch on a clean data lineage, designed for efficiency, working seamlessly as a family of models
Thread 🧵
#MSBuild