More information ...
ASSERT launch post:
https://t.co/1F7dJutwDR
ASSERT on GitHub: https://t.co/9tEJjB1fHx
Microsoft Build session about ASSERT, evals, and security governance: https://t.co/KTEgusI3Mb
Microsoft announced a bunch of interesting new AI models and tools this week. Model launches alway get lots of attention. But don't sleep on the new ASSERT evals framework that launched today.
I'm on record as arguing that 2026 is the year of evals.
Evals are the glue for all the "jobs to be done" at every level of AI: model training; testing and deciding on what models to use and how to use them; and testing and improving AI agents in production.
Evals unify our work on those different layers of the stack.
These days, when we talk about evals, observability, and testing, we're talking about overlapping parts of a large set of tools we're still early on in figuring out.
As the AI engineering ecosystem matures, diversifies, and increases massively in scale, we really, really need good evaluation (observability, monitoring, testing, data management) frameworks.
I got a chance to test the new Microsoft ASSERT evals framework before it was released, and it has some very nice core ideas.
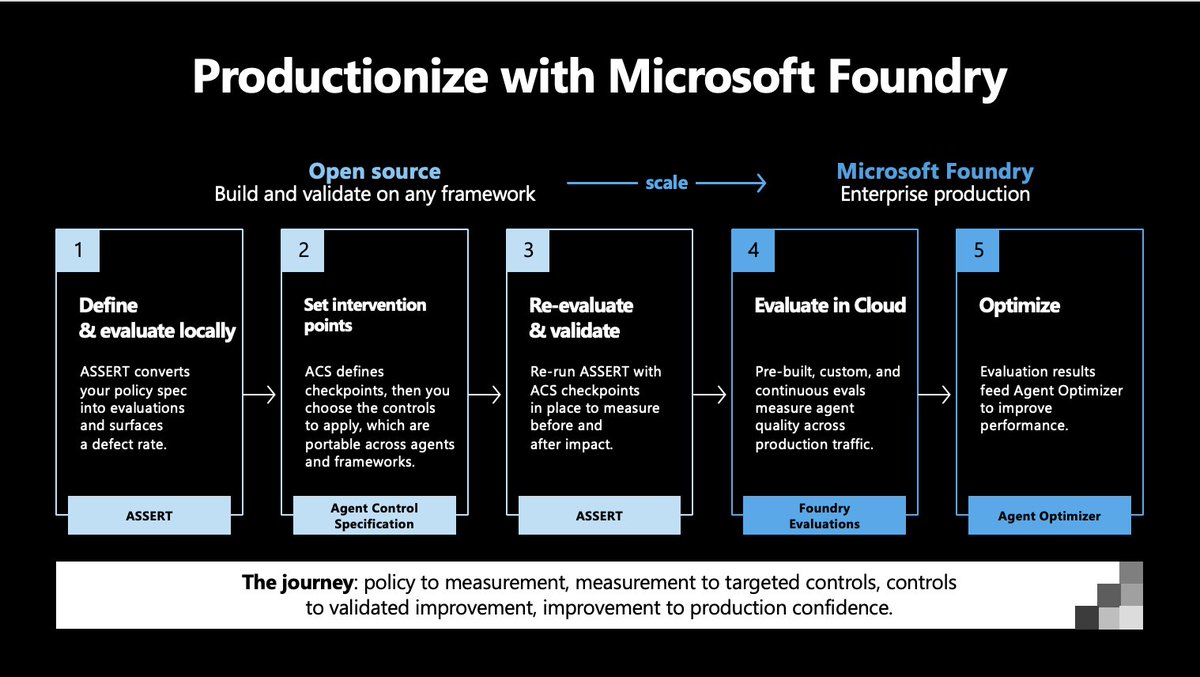
1) ASSERT is open in two important ways. First, the team is serious about broad support for models, frameworks, and use cases. Microsoft spent time understanding voice agent use cases and building Pipecat support, for example. Second, the code is completely open source, released under an open MIT license.
2) We're all working in and with agentic coding tools today. That means we are planning in natural language, and all of our software development and ops tools have to evolve for these new, natural language, workflows. ASSERT takes descriptions of desired agent behavior and generates specifications for the ASSERT suite of tools to run against.
In a world where "English is the programming language," how we actually make natural language "code" precise enough and repeatable enough is perhaps the big unsolved tooling problem that all of us are working towards in different ways. This is true whether we work on coding agents, AI opps tooling, orchestration frameworks, or vertical applications.
3) Microsoft describes ASSERT as a policy-driven framework. Rather than eval against generic performance metrics, ASSERT aims to generate stable but adaptable evaluation criteria for specific agents.
"Policy-driven" also implies a full loop design. Policy (generated from specific requirements) -> evaluation -> optimization -> monitoring in production -> improving the policy description -> evaluation -> ...
4) Enterprise agents need to be evaluated along many dimensions: task completion, individual conversation turn behavior, latency, mode-specific metrics like audio disfluencies, and safety/security. Microsoft designed ASSERT to be used together with a new safety governance toolkit called Agent Control Specification.
5) Finally, ASSERT is integrated into the Microsoft Foundry ecosystem. Today, AI engineering tools have to be open source and vendor neutral to get attention from developers and gain widespread adoption. *And* it's equally important to give enterprise customers tools that work as a coherent stack.
This is hard to do well. There are real tensions between open source development versus engineering a great full stack developer experience. However, if you sweat the details on both ends, you benefit from a full spectrum of feedback about real-world development pain points. It's more work, but it's worth it!
Kudos to Microsoft for embracing this and committing to an open, community oriented approach, plus doing the extra work to build the full stack for enterprise customers.
Fantastic commentary on the Microsoft MAI tech report released yesterday. Wonderful to see this level of detail about a large scale training effort, and this kind of super helpful analysis from @eliebakouch.
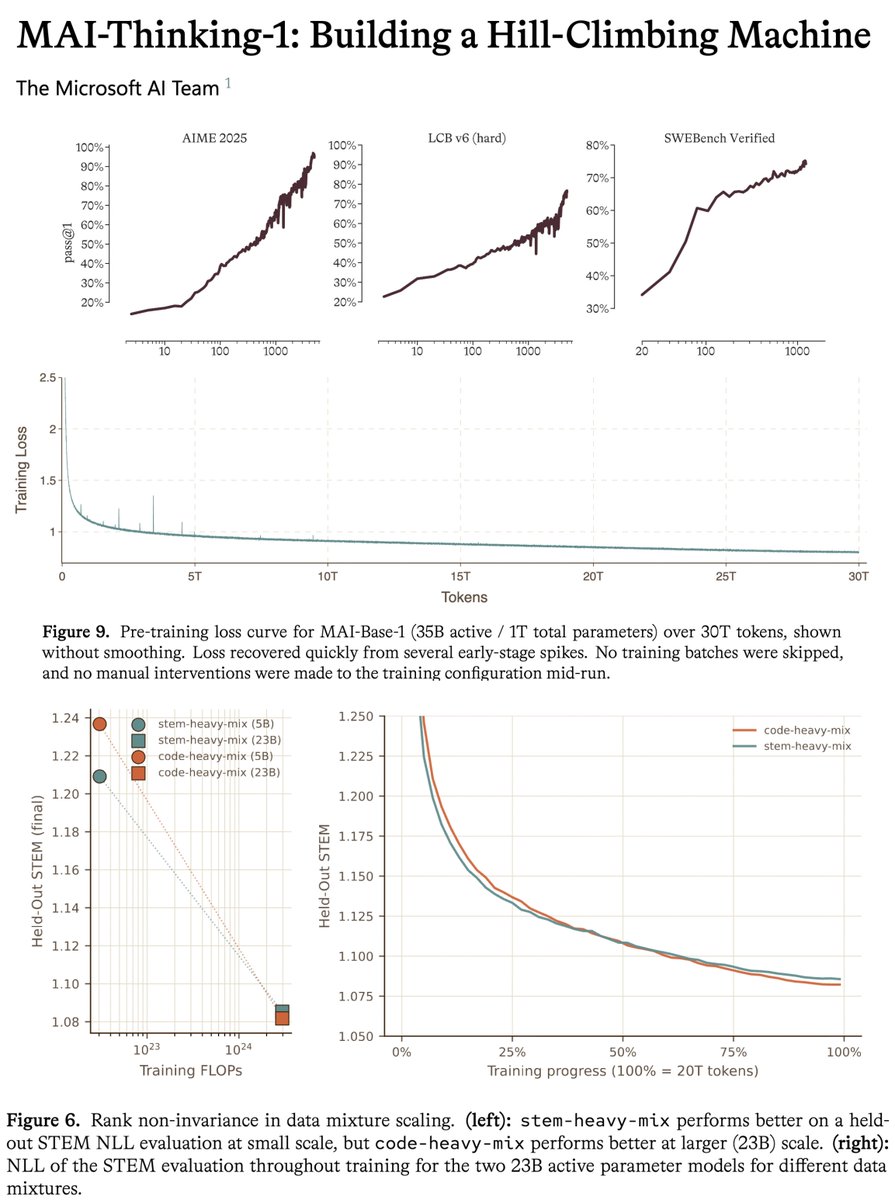
microsoft MAI tech report is a gold mine, one of the most transparent for a model at this scale.
this model uses zero synthetic data or distillation from previous models. this means reasoning, agentic behavior, tool use are all learned fully during post-training with no cold start. bold choice that makes it harder and requires more iterations to reach sota, but you get FULL control over your model series and it proves they are serious about being a frontier lab.
the tech report is insanely detailed and precise about numbers. to give an example, they give the exact MFU across all the iterations of the model, with the exact changes etc. they also share the full scaling ladder recipe, to my knowledge this is the first time i've seen this in a tech report at this scale
let's look at all of this in this likely very long thread 🧵
Arresting the downhill slide into sloppification of generally cited AI benchmarks is possibly one of the most important things someone thoughtful, stubborn, and well connected could work on today.
We don't talk enough about how the marketing of a typical model release today focuses on benchmarks that are somewhere between useless and actively misleading.
The incentives here are totally understandable. But the impact on every part of the ecosystem is significant. The most useful hills are not climbed. Adoption of genuinely good models for tasks they are well suited for is slower than it should be. Teams struggle to turn a great POC into a production agent deployed at scale.
This might not be solvable. Perhaps it's one of those things it's better to be sanguine about. See also, "the optimal amount of fraud is not zero, and "democracy is the worst form of government except for all the others. But I hope someone like @willdepue tilts at this windmill.
i know the solution to the AI benchmark problem but nobody is gonna like it
it’s easy: just report test perplexity on uncontaminated high-quality code/lang/etc
you give me base model api. i run on my secret dataset. i give you test ppl. all evals are downstream of that. solved
@localoptimiser@cerebras I mean, sure, but the voice-to-voice in the video is 1) using a 1T parameter model, 2) in reasoning mode, 3) with a real network stack.
Cerebras inference is very fast. So fast that it changes how we think about configuring our LLMs for voice agent use cases.
Kimi K2.6 is a 1T parameter reasoning model that @cerebras serves at 650 - 1,000 tokens per second (end-to-end throughput), with time to first token metrics as low as 150ms (latency).
These numbers are two to three times faster than other similarly capable models.
The biggest lever we get from this kind of speed is that we can use the model in reasoning mode, and still have excellent "time to first non-thinking token."
This solves a big pain point we have in 2026 for voice agent use cases. Almost all recent innovation in post-training has focused on making models good at reasoning ("test time compute"). This is great, but it makes the user-facing model latency much, much slower. Which is a problem for conversational voice agents.
We can run Kimi K2.6 with reasoning turned on, and get responses faster than other models produce with reasoning disabled.
On my 30-turn voice agent benchmark, Kimi K2.6 with reasoning enabled ties GPT 5.1 and Haiku 4.5 with reasoning disabled, and is still about 200ms seconds faster!
On my primary task agent benchmark, Kimi K2.6 is now the #2 model. It ranks just behind Gemini 3.5 Flash in "high" reasoning mode, and tied with GLM 5, Sonnet 4.6, and GPT 5.4 with reasoning set to "low." But Kimi K2.6 completes each turn in the agent loop in under 500ms. The other four models are all at least 3x slower. (Models only qualify for this benchmark if they can complete task turns at a P50 <4s.)
A couple of other things that this speed buys us, for production voice agents:
- Tool calls happen fast enough that we don't have to work around tool call latency in our pipeline design.
- We can prompt the model to output structured data at the beginning of a response, followed by plain text for voice generation. This opens up possibilities like asking the model to do complex classification/generation tasks that influence the rest of the pipeline. For example, the model could create a detailed style prompt for a steerable TTS model, for each individual conversation turn.
And, of course, you can use Kimi K2.6 with reasoning turned off. Cerebras calls this "instant" mode.
Here's a video of a Cerebras Kimi K2.6 voice agent with voice-to-voice response time, measured at the client, under 500ms. This is the true response latency as perceived by the user, including all network and audio codec overhead, transcription and turn detection, Kimi K2.6 token generation, and voice generation. 500ms is, effectively, instant. So the Cerebras naming for this mode is a propos. :-)
Open source models in the realtime video domain! Here's an open weights, open data sets, open training code release, with a nice technical overview post (links in the thread.)
And you can vote for this model today on @ProductHunt.
🚨 AVTR-1 New Model is OPEN WEIGHTS . Duplex Native , #1 on benchmarks.
Here’s what being released. Links in comments
- Model + Paper now on HF
- Full Github repo to run it really fast
Run it anywhere as low as $0.
Comment, share, star on GH to get the word out
Have you looked at the benchmarks I posted? Gemini 3.5 Flash scores 99% on the aiewf-eval benchmark with a TTFT of 960ms. Kimi K2.6 scores 98% with a TTFT (first non-thinking token) of 452ms.
1% difference here is significant, but generally means you'll be able to fix the issues you find by iterating on prompting. Think of it as 1 turn mistake every 100 turns. So if your average conversation length is 30 turns, that's one mistake every three conversations. And most of these mistakes are recoverable.
@Itsdotdev@cerebras Kimi K2.6 is clearly not an old/dumb model! That's why I posted about this. It seems like a pretty big deal to me that we have both performance that matches GPT 5.4 and much faster TTFT.
> Love the comparisons against a couple of generations older frontier models
I mean, I know what you're saying, but the Cerebras models are strictly better than the current generation models from the frontier labs if TTFT matters for your use case. And TTFT really, really matters for voice agents.
The big labs are doing amazing things with RL for reasoning and now agentic looping stuff. It's incredibly exciting. But no frontier model released since GPT-5.1 has any kind of new post-training that is an improvement for low latency use cases.
So a different way to look at what you're saying is that open source models are now *ahead* of models from the frontier labs.
Voice AI turn taking is a solved problem.
The single most common complaint about voice AI, today, is that agents interrupt too often. But the voice agents I build for myself now respond quickly and interrupt me less often than the people I talk to every day. (I actually measured this.)
@mark_backman made a @pipecat_ai PR two weeks ago that was the last piece of the puzzle for turn taking so good that I no longer ever think about it.
The approach combines three layers of processing:
1. Voice activity detection, with a short (200ms) trigger.
2. A native audio turn detection model that's small, fast, and runs on CPU. This model captures audio nuances like inflection and filler sounds that don't get transcribed.
3. A prompt mixin for the conversation LLM that decides turn completion based on conversation context.
None of these are new. We've been using VAD for a long time. We trained the first version of the Pipecat Smart Turn native audio model in December 2024. And we've been experimenting with prompt-based large model turn detection (sometimes called "selective refusal") for more than a year.
Now, the Smart Turn model and the SOTA LLMs we're using in voice agents have both gotten so good that using them together feels like we've finally "solved" turn detection.
Mark also figured out how to elegantly apply a "single-token tagging" technique to this problem. We sometimes use single-token tagging in place of tool calling, when we need a near-zero latency programmatic trigger. Mark's Pipecat mixin defines three single-token characters and prompts the LLM to output exactly one of them at the beginning of every response.
- ✓ means the agent should respond normally (immediately)
- ○ is a "short incomplete" - the agent should wait 5 seconds
- ◐ is a "long incomplete" - the agent should wait 10 seconds
The wait times, and the details of the prompt, are configurable, of course.
Watch the video to see me talk to an agent that handles all my various pauses and inflections, plus phrases like "let me think," pretty much the way a person would handle them, in terms of response latency.
Also, in the second half of the video, I ask the agent to adjust its response pattern because I'm going to tell it a phone number. This kind of "in-context" adjustment of response wait times is really useful.
The LLM in the video is GTP-4.1. We've tested the prompt and single-token adherance with GPT-4.1, Gemini 2.5 Flash, Anthropic Claude Sonnet 4.5, and AWS Nova 2 Pro. Note that older models in all these families (and, in general, smaller open weights models) aren't able to reliably output these single-token tags. But the new models we're using these days are pretty amazing.
@oneitonitram@cerebras You can get access, but I think probably need to be able to make a volume commitment. This is similar to buying dedicated compute from AWS, Azure, or GCP, which is what you have to do today to get the lowest possible TTFT for other models.
@arlogilbert@cerebras Agreed, and they are organizing the sales around this model accordingly. (It’s not “self serve.”) Too much demand, which is a good problem to have!
See the Cerebras blog post about Kimi K2.6 for more notes about the model: https://t.co/2PJWbP5oP0
Benchmark results are uploaded here:
- https://t.co/EPMF7fwVaw
- https://t.co/wkN0AI9OQS
The voice agent in the video is just a standard Pipecat pipeline using:
- Pipecat native audio Smart Turn - https://t.co/urWVrzYZ68
- NVIDIA Nemotron ASR Streaming - https://t.co/0ajndKpVb8
- Cerebras Kimi K2.6
- Kyutai Pocket TTS - https://t.co/0LVgclv814
You can use the Pipecat CLI to create an agent like this, including the peer-to-peer WebRTC network transport and the developer UI in the video.
https://t.co/fpEtdb31sp