Local native-audio voice agent running on an RTX 5090.
- @NVIDIAAI Nemotron 3 Nano - audio|text ➡️ text
- patched vLLM to implement complete turn prefix caching
- ~125ms TTFT
- @kyutai_labs Pocket TTS - text ➡️ audio
- Nemotron Speech ASR - streaming audio ➡️ text
- @pipecat_ai Smart Turn end-of-utterance
- ~500ms total voice-to-voice latency
- runs bash via tool calls
If you're interested in voice and realtime multi-modal AI, come join us at the SF Voice AI Meetup on Thursday May 7th. Talk to engineers from NVIDIA, Kyutai, and Pipecat about what you're building!
Links to meetup registration, code, and models on @huggingface below ...
Big day today. Pipecat version 1.0. Two years in the making. The most widely used framework for voice agents, but not just voice agents. Pipecat is a framework for realtime, multi-modal, multi-model AI applications. Contributions from NVIDIA, all the foundation labs, AWS, GCP, and Azure. Used by thousands of startups, scale-ups, and enterprises.
Pipecat Subagents v0.1.0. A new library for sub-agent orchestration. Which is just a fancy way of saying running lots of inference loops in parallel, with partially shared context. The basic architecture of Pipecat Subagents is an event bus that works locally, and over the network.
And Gradient Bang. The side project that broke containment. Built with Pipecat and Pipecat Subagents. Gradient Bang was actually the proving ground for the early Subagents work. But ... it's also a really fun game.
Sub-agents in (latent) space!
We’ve been working on a side project.
As far as I know, this is the first massively multiplayer, completely LLM-driven game. Come play Gradient Bang with us. See if you can catch me on the leaderboard.
This whole thing started because I wanted to explore a bunch of things I’m currently obsessed with, in an application of non-trivial size, that felt both new and old at the same time.
So … a retro-style space trading game built entirely around interacting with and managing multiple LLMs. Factorio, but instead of clicking, you cajole your ship AI into tasking other AIs to do things for you.
Some of the things we’ve been thinking about as we hack on Gradient Bang:
- Sub-agent orchestration
- Partial context sharing between multiple LLM inference loops
- Managing very long contexts, and episodic memory across user sessions
- World events and large volumes of structured data input as part of human/agent conversations
- Dynamic user interfaces, driven/created on the fly by LLMs
- And, of course, voice as primary input
If you’ve been building coding harnesses, or writing Open Claw agents, or doing pretty much anything that pushes the boundaries of AI-native development these days, you’re probably thinking about these things too!
This is all built with @pipecat_ai, the back end is @supabase, the React front end is deployed to @vercel, and all the code is open source.
Gemini 3.1 Flash Live, a new version of Google's speech-to-speech LLM, just launched.
As you can see in the video, the vibes are really good, and our friends who worked on the model are very excited.
There is, of course, day 0 support in @pipecat_ai so you can try the model out just by creating an agent and running it locally:
```
uvx --from pipecat-ai-cli pipecat init
```
This is a teaser for a longer tutorial that @chadbailey59 built together with the @GoogleDeepMind team!
We have lots more fun stuff cooking with this model. Stay tuned for technical deep dives, detailed long-conversation benchmark numbers, and multi-model orchestration sample code that combines this Live model with Gemini reasoning sub-agents in a "thinking fast and slow" architecture.
Join us on Thursday in SF for conversations about voice agents, speech models, and realtime AI infrastructure.
I'm on a panel with:
- @natrugrats from @DeepgramAI
- @farazmsiddiqi from @getbluejay_ai
- Aaron Lee from Parakeet Health
There will be food and lots of opportunities to ask questions and share your knowledge.
One thing I'm looking forward to is comparing notes about GTC last week.
Come by and see @EvanGrenda at the AWS booth at GTC. @tavus video avatars, voice agents built with NVIDIA Nemotron models, and new realtime AI architecture patterns in @pipecat_ai!
Today's @NVIDIA Nemotron 3 Super launch is an exciting development for voice AI developers.
We’re proud to be a launch partner, with day-0 @pipecat_ai support. Developers now have a meaningful open stack for realtime voice, with @NVIDIAAI — Nemotron 3 Nano, Nemotron Speech ASR, Nemotron 3 Super. Open models, open training data.
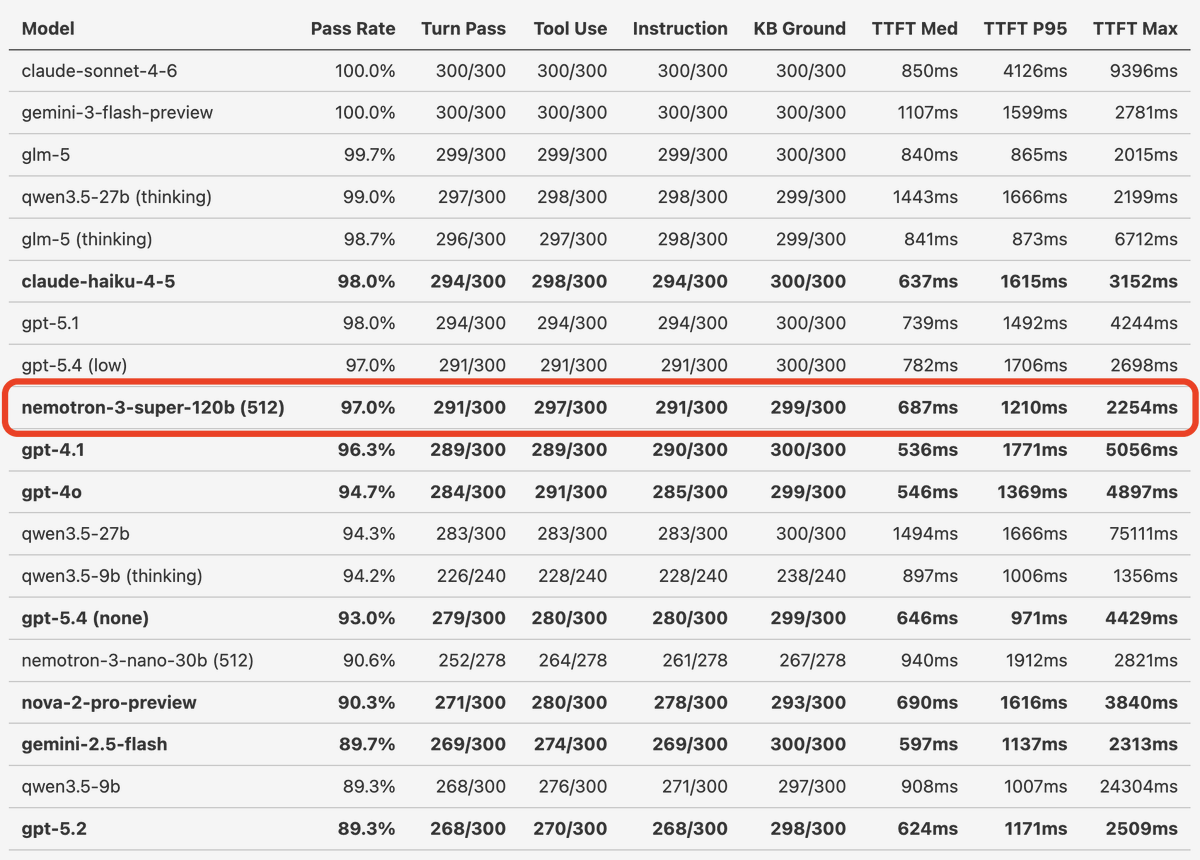
Review how Nemotron 3 Super matches proprietary models in our long-conversation voice agent benchmarks. Happy building, with open source!!
NVIDIA Nemotron 3 Super launches today! We've been building voice agents with Super's pre-release checkpoints and running all our various tests and benchmarks.
Nemotron 3 Super matches both GPT-5.4 and GPT-4.1 in tool calling and instruction following performance on our realtime conversation, long context, real-world benchmarks. GPT-4.1 is the most widely used LLM today for production voice agents. So an open model that performs as well as GPT-4.1 on hard, voice-specific benchmarks is a big deal.
(Side note: we don't think a benchmark "tells the story" about a model's voice agent performance unless it tests model correctness across at least 20 human/agent conversation turns.)
The Nemotron models are *fully* open: weights, data sets, training code, inference code.
Nemotron 3 Super is 120B params, with a hybrid Mamba-Transformer MoE architecture for efficient inference. You can run it on NVIDIA data center hardware or on a DGX Spark mini-desktop machine.
1M token context.
Blog post with full benchmarks, thinking budget notes, inference setup on @Modal, and where we think this goes next. 👇
Bo Xie of @OpenAI joins our Thursday voice AI meetup. He'll talk with us about training the new gpt-realtime-1.5 speech-to-speech model, @OpenAIDevs. SF + livestream link in thread.
One of my 2026 predictions is that we're going to see a lot of interesting new experiments with LLM-powered games. There are just so, so many possibilities. The main barrier is inference cost. But that's dropping fast.
My friends Vanessa and Sunah have been tinkering with a voice game called Crush Quest.
Crush Quest has multiple characters, a bunch of really good prompting, and you can play on the web or (clone the repo and) wire up a telephone number. It's, you know, totally open source and that's radical.
As you can maybe tell from my hip use of slang, Crush Quest is set in the early 1990s. It's an homage to a classic electronic board game called Dream Phone. Check out the thread below for a link to the most perfectly 1991 TV commercial for Dream Phone. I can taste the Lucky Charms when I watch this commercial.
h/t to @chelcietay who I had a great conversation with recently about our 2026 predictions and where social and gaming is going.