AI is bound to fail.
The biggest lie you’re told: “Just plug an MCP into your knowledge base, and you have a smart assistant.”
You don’t.
That just connects your AI to data.
It doesn’t prove the data is safe to trust.
It doesn’t prove the policy wasn’t replaced yesterday.
So the model does what models do: reads outdated context with perfect confidence.
That’s how AI systems actually fail in production.
Not because the model is stupid.
Because the system handed it unsafe evidence and asked it to be certain.
We built @kyrodb to fix exactly this.
It’s a context correctness runtime that sits between your AI agents and your knowledge stores.
Before context reaches the model, KyroDB checks freshness, scope, provenance, and proof.
If it’s stale, unsafe, or unprovable, your AI doesn’t guess.
It knows when it knows.
And refuses when it doesn’t.
KyroDB is the last line of defense before your AI speaks.
First 100 developers get 25% off. Coupon + link in the comments.
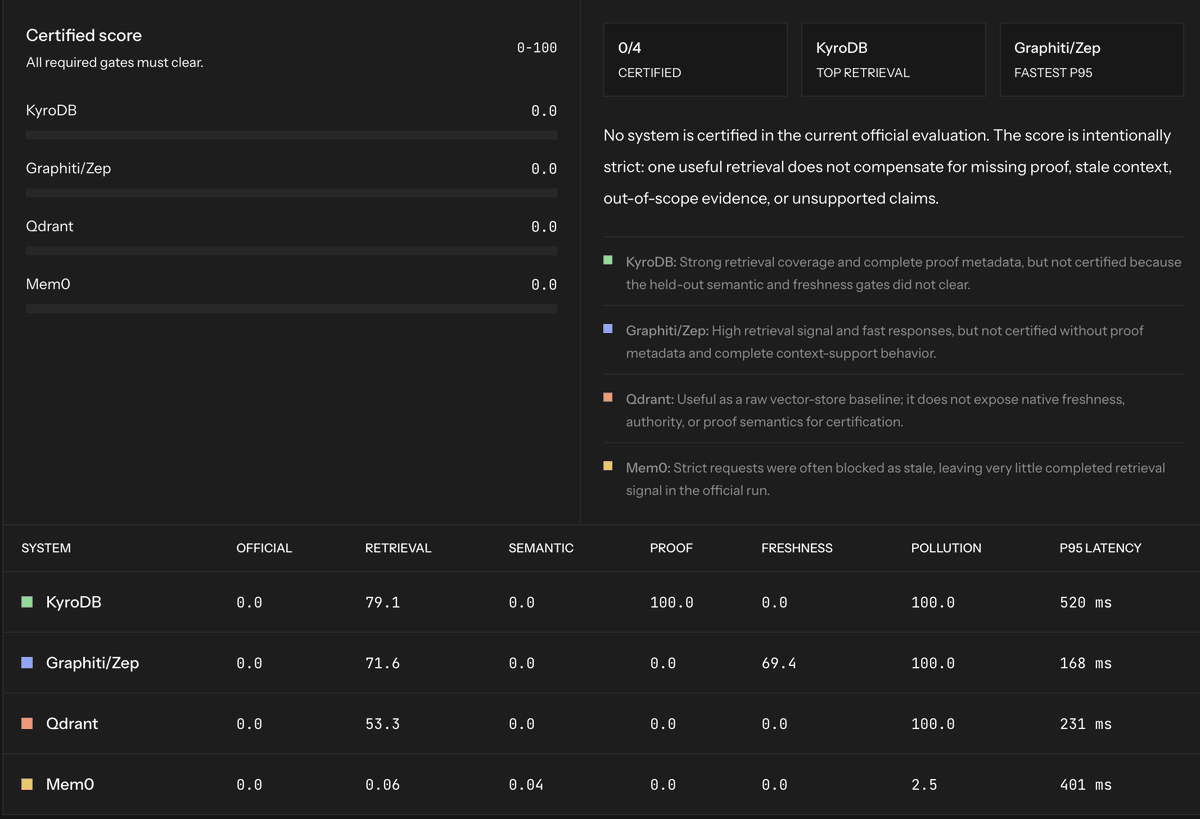
KyroBench paper is out, a benchmark focused on context correctness & safety-critical failures in real production agent/RAG workloads.
Frontier systems still score 0 on certification.
Link in comments.
Today we’re releasing KyroBench: a benchmark for context correctness in production-shaped agent/RAG workloads.
A system can retrieve semantically similar text and still be dangerous if it is stale, cross-tenant, deleted, lower-authority, polluted by prompt injection, or missing proof.
Currently, Frontier Systems scores 0 on the certification.
KyroBench pushes agent/RAG evaluation toward safety-critical context behaviour.
Designed for teams to catch failures that matter in legal, healthcare, support, SRE, CRM, and coding agents.
Plain vector retrieval is not enough; memory systems help; graph systems help differently, but production context needs freshness, deletion, scope, authority, and proof.
Proof is all what founders want to give nowadays for the work they do on their startup,
That's too overrated for me , so I decided that now onwards just going to pick up my camera and give you a glimpse of everyday life while we build something for the world,
This is day 1 , so follow along for the journey ahead while we build @kyrodb
DeepSeek V4 proved something significant with a 1M token context window.
At 1M tokens, MRCR 8-needle accuracy drops to 0.59. That's a 41% failure rate on fact retrieval at depth.
And that's after compressing the KV cache to 2% of the standard attention cost.
So the needle problem at extreme depths still remains fundamentally unsolved by attention-based systems.
V4's architecture is the best available evidence that the LLM itself cannot be the context system. Consider what CSA is doing:
It compresses 4 tokens → 1 KV entry, ranks blocks by relevance, and drops the low-ranked ones.
That is, in essence, a retrieval problem disguised as an attention problem. And DeepSeek solved it inside the model weights, meaning it's baked in, static, non-updatable, and blind to your actual knowledge freshness.
But here's the catch: the model layer can compress context. It can retrieve better, but it cannot know that the pricing doc you fed it expired a week ago.
The larger extrapolation of this is- as LLMs get bigger context windows, developers will stuff more into context, more docs, more history, more knowledge. The probability of stale/wrong information contaminating that context grows proportionally
@kyrodb fixes this problem with a Context Runtime, giving AI agents fresh, verifiable, transaction-safe context as business knowledge changes
Bigger context windows don't fix the accuracy/reliability problem; they make the surface area for stale facts larger.
🚨 78% of AI failures are invisible.
That's right. AI gets something wrong, but no one catches it. Not the user, not traditional monitoring, not even a sentiment analysis. These failures cluster into recurring patterns:
→ The confidence trap- AI is confidently wrong, and the user accepts it
→ The drift- AI gradually answers a different question than what was asked
→ The silent mismatch- AI misunderstands but produces something plausible enough that the user doesn't push back
These patterns persist across 93% of cases even with more powerful models, because they stem from interaction dynamics, how models present outputs, and how users communicate intent, not capability gaps.
This is one of the core problems we are solving at @kyrodb . We believe, for the deployment of responsible and reliable AI, the real and critical bottleneck is the infrastructure around it, the harnesses with which the model interacts, not the model itself.
We built the KyroDB runtime to fix one part of it- the WRONG CONTEXT. It contributes largely to the model hallucinating and even more blunder, answering something wrong that too, with confidence.
KyroDB makes sure the context is fresh, safe, and reliable to use before it reaches your model.
Check out KyroDB to stop your AI from lying with confidence. Link in comments.
Saw a reel in which a contestant pitched a context solution to @waitin4agi_ and he rejected that by saying 'Context won't be a problem in the long run' by giving an example of increasing context window in LLMs.
I have great respect for Varun, but he is 100% wrong here. The idea of 'We can solve context problem by increasing the context window' is out of touch in so many ways.
Bigger context windows help capacity, but they do not automatically solve selection, relevance, or pollution.
'Needle in the haystack and 'context rot' problems are one of the most complained issues when you visit developer forums(on X too).
We are fixing this context issue at @kyrodb.
Long context ≠ usable context
Many frontier researchs also highlighted this issue.
🧵
Model intelligence won't solve context.
Memory/context is not a feature. It is becoming the data plane of AI.
Long context windows help, but they do not eliminate the need for memory/context infra. They mostly change what the infrastructure has to do.
The state of AI where we are at right now, the requirement is:
How do you continuously assemble the right, fresh, permissioned, compressed, explainable context for an AI system that is reasoning, acting, remembering, and coordinating across tools?
The future will not be 'one giant model that remembers everything.'
The future is:
Many intelligent models operating over governed, persistent, external state.
That external state is where the business value lives.
Models will become more interchangeable over time. Context will become more proprietary.
The company’s memory, workflows, relationships, permissions, and operational data will be the moat.
We need to build a system that can answer:
What should the AI know right now, why should it trust it, what is it allowed to do with it, and how do we prove that later?
AI systems do not fail only because the model is weak. They fail because the context is stale, incomplete, unsafe, or irrelevant.
The next layer of AI infrastructure is context that is fresh, scoped, and provable before the model acts.
The industry treats agentic memory as a storage problem.
We treat it as a distributed systems correctness problem
Launching a SOTA CONTEXT/MEMORY solution from @kyrodb this weekend.
Stay tuned.
Opening up my calendar to chat on AI agents, mostly around retrieval/context/memory.
If you are someone working in this field or even interested in this, let's chat and discuss what's going on in the market.
Link in comments.