When I start a computational biology project these days, I set up a git repo and a LaminDB instance. It lets me do a lot more, in a reasonable time, in a reproducible way. That's a rare combination in this field. I recently made a short blogpost about it: https://t.co/AdUWmH67TN
When spatial datasets accumulate across experiments and technologies, managing, querying, and training models on them becomes a major challenge. To address this, we built support for scverse's SpatialData format into LaminDB, enabling cross-dataset queries, dataset validation, and lineage tracking.
The main challenge was extending pandera-based schema validation to the complicated structure of SpatialData; Parquet and AnnData are easier!
Blog: https://t.co/pmpT2A6uOy
Code: https://t.co/tb6t2FJ7tt
With @LukasHeumos and many others!
Hi friends, I wrote a guest post for Lamin on using the open source LaminR package in an R workflow with the PBMC 3k dataset.
Focus: provenance — tracking code, environment & execution order so analyses are reproducible when you (or someone else) comes back to them.
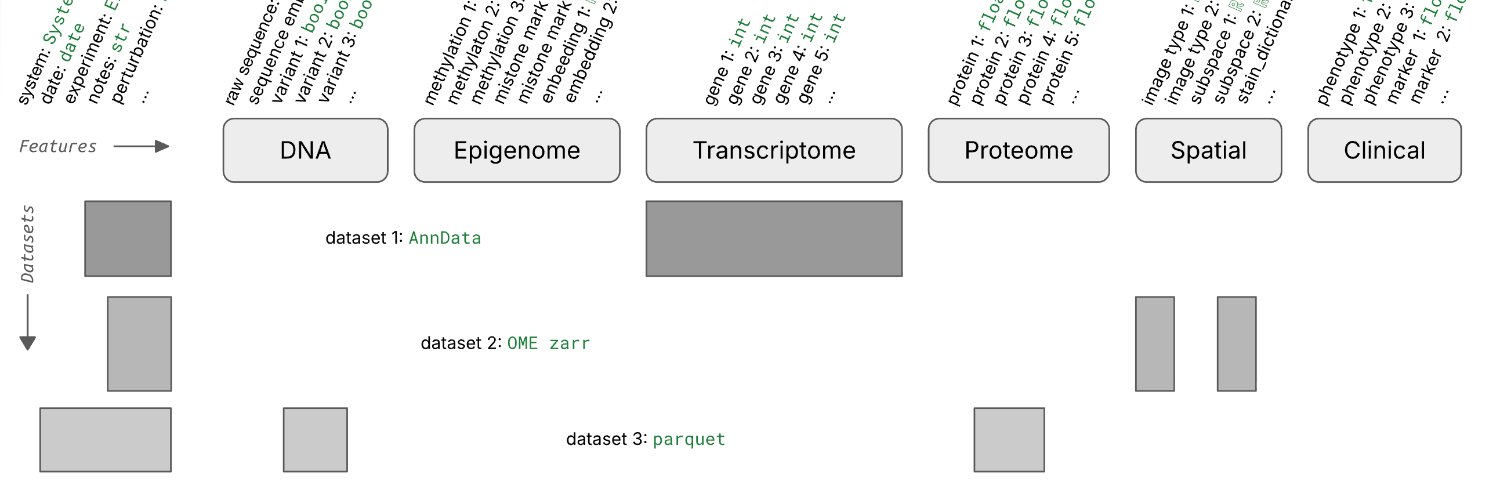
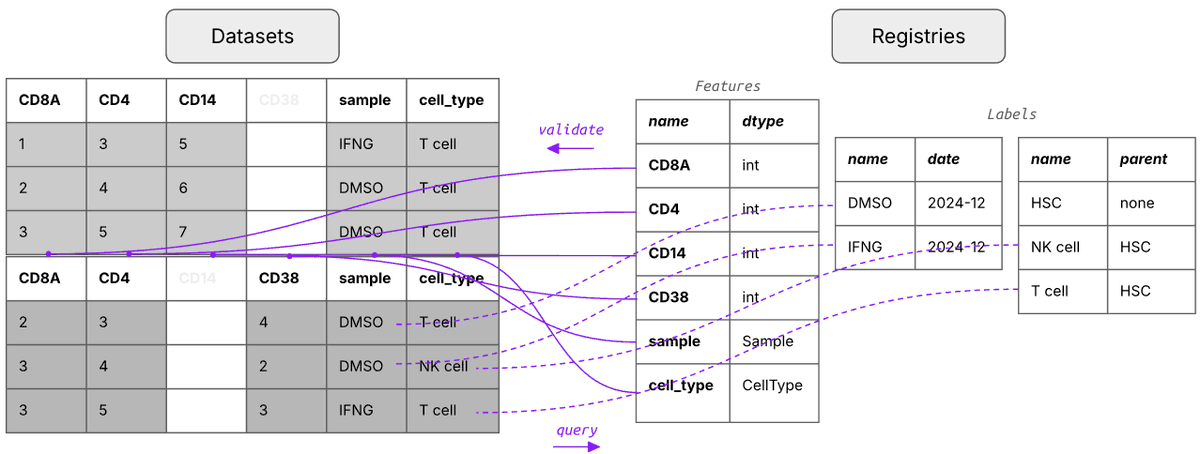
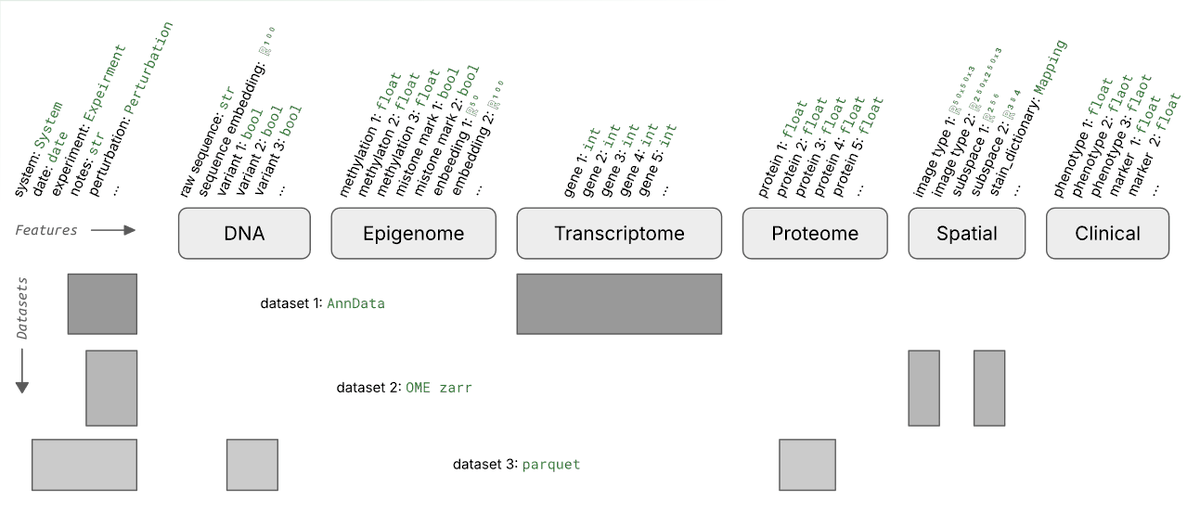
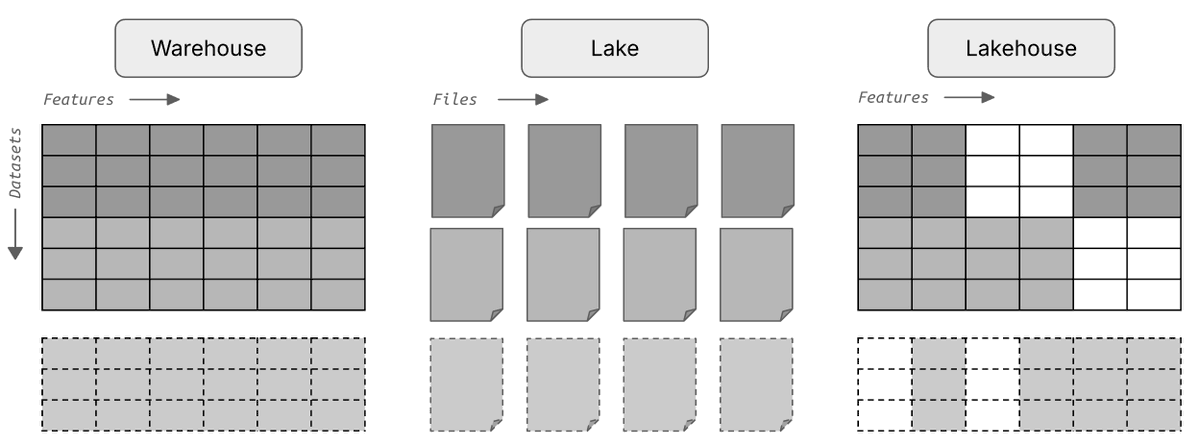
Existing data infrastructure can't make sparse measurements across millions of features queryable. Warehouses are too rigid, data lakes can't be queried, tabular lakehouses don't understand the formats. Biology needs a data lakehouse with support for bio-formats and registries.
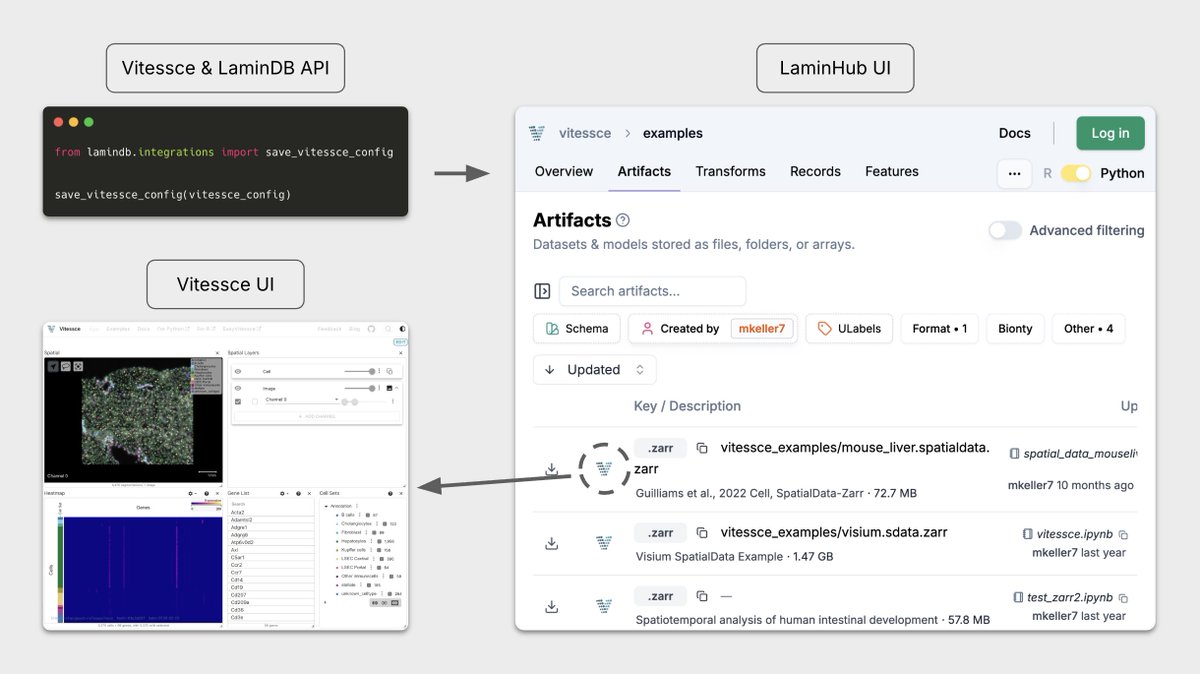
Two years ago we partnered with Mark Keller from Nils Gehlenborg’s Lab at Harvard to make Vitessce work seamlessly with LaminDB for interactive visualization of multimodal + spatial datasets.
The integration has found much use across academia, biotech, and pharma — so we wrote up on design principles & use cases.
This was a team effort involving Altana, Richard & Sunny in addition to Mark.
Read the post: https://t.co/a7vvu6p0y3
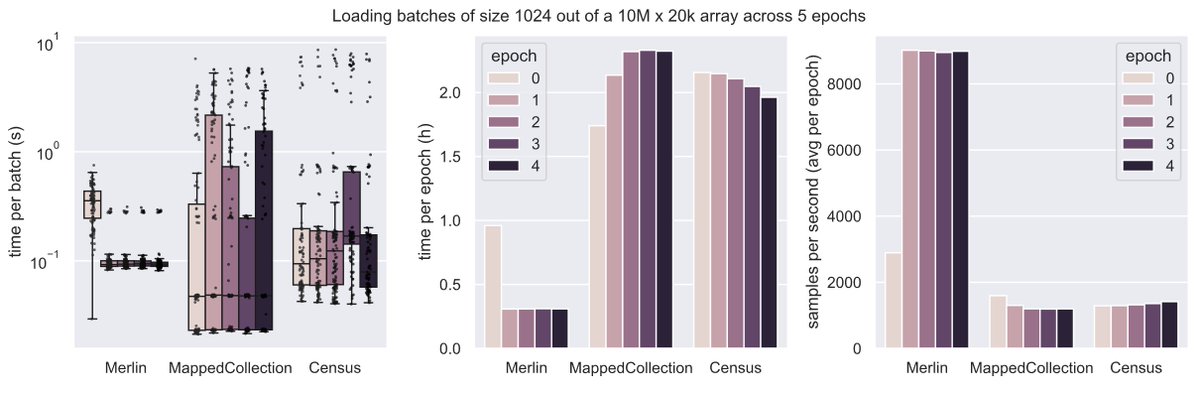
Nice, detailed benchmark of backends that allow for batched training on a large scRNA-seq corpus - efficiently dealing with the specifics of a scenario can be a big engineering challenge, lowering this barrier will enable cool computational biology down the road!
What's a good way of organizing scRNA-seq data for training foundation models?
Say you run 1k experiments and each measures counts for 1M cells with varying metadata and orthogonal data.
Storing these data in one gigantic array isn’t exactly easy.
We wondered whether it’s necessary to train foundation models and found 3 setups that made sense to us.
https://t.co/4p6g3iRbpE
Thank you for the awesome collaboration, @marenbuettner!
With Pytometry, we'd like to share readfcs: A package to load data and metadata from FCS files to AnnData.
pip install readfcs