GLM-5.2 on FriendliAI: #1 throughput AND lowest tool call error rate on @OpenRouter.
→ 48 tok/s avg — fastest of any provider
→ 0.11% tool call error rate — the lowest on the board
Speed + reliability for long-horizon agents.
GLM-5.2 is live Day-0 on FriendliAI Model APIs: serverless, pay-per-token, OpenAI-compatible. Point @Claude Code, @kilocode, @cursor_ai, @cline, @opencode or any agent at a custom endpoint and go.
Full breakdown → https://t.co/s2VQKdJ3KI
Try it out → https://t.co/GlOqIWfQKh
#GLM #Inference #AIagents #OpenRouter
Heading to @icmlconf in Seoul? Come spend an evening with the teams building at the frontier.
FriendliAI is hosting an invite-only night on July 6 — the first day of ICML 2026.
📅 July 6, 2026 | PM – PM
📍 FriendliAI Seoul Office, Gangnam-gu, Seoul
💌 RSVP → https://t.co/4vOjSfdqxa
Hear from:
🎤 Yu Jin (Lou), Head of Dev Ecosystem @ https://t.co/Kl9KGga11U
🎤 @bgchun (Gon), Founder & CEO @ FriendliAI
Space is limited. If this sounds like your scene, register now. See you there!
FriendliAI secures $20M in Seed-Extension Funding!
This round was led by Capstone Partners with participation from SIERRA Ventures, Alumni Ventures, Korea Development Bank, and KB Securities.
As AI inference adoption accelerates globally, this funding positions us to power startups and enterprises with high-performance, cost-efficient AI inference at scale.
Read the full article 🔗 https://t.co/DIZcdSUsXi
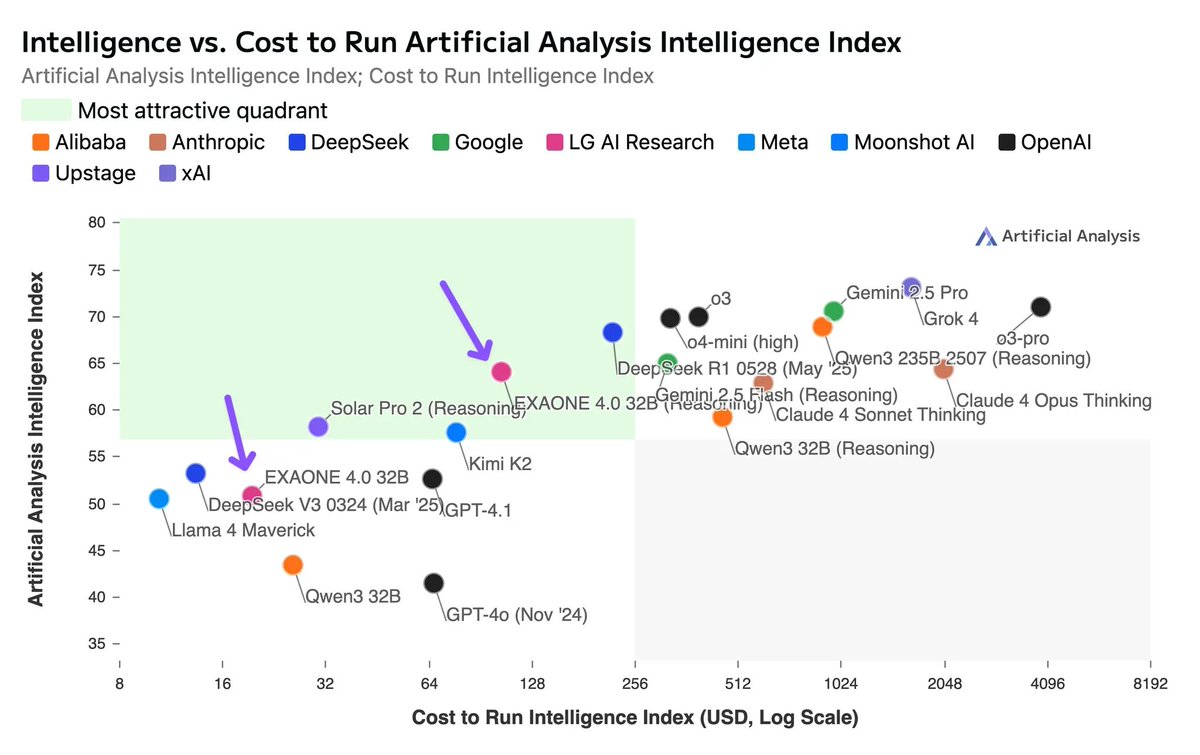
EXAONE 4.0 uses more output tokens than Claude 4 Opus in Thinking mode. However, its lower per-token pricing on FriendliAI makes it much less expensive overall than Claude 4 Opus in Thinking mode
DeepSeek-R1 is now available on Friendli Serverless Endpoints! 🚀
Here’s why teams are excited to integrate DeepSeek-R1 into their workflows:
⚡ Blazing-fast speeds combined with high-quality responses
🔒 Privacy-first hosting in a secure, US/Europe-based data center
📖 Support for maximum context lengths of up to 164k tokens
💰 Flexible, hassle-free pay-as-you-go pricing
Try @deepseek_ai now with a free credit 👉 https://t.co/DozL6a7TWr
Check out our blog 👉 https://t.co/dhZ75K8zdV
#FriendliAI #DeepSeekR1 #ServerlessAPI #LLM #Inference
🚀 Exciting news! FriendliAI and @huggingface are teaming up in a strategic partnership!
Developers can now easily deploy and serve models directly from the Hugging Face Hub using FriendliAI’s high-performance inference infrastructure.
With just a few clicks, unlock blazing-fast, cost-efficient endpoints powered by FriendliAI—seamlessly integrated with the Hugging Face platform.
Read the full press release 👉https://t.co/Pl8zC15Foe
Explore our blog post 👉 https://t.co/jla5vnYUN6
Try deploying Llama 3.1 8B now 👉 https://t.co/Bm56zFkWB2
#FriendliAI #HuggingFace #Partnership #OpenSource #Deployment
FriendliAI, a leading generative AI engine company, is proud to announce the public beta release of PeriFlow Cloud. This powerful platform empowers users to run PeriFlow, an engine for generative AI serving, within a managed cloud environment.
With its innovative approach specifically tailored to large language models (LLMs), the PeriFlow engine achieves remarkable improvements in throughput while maintaining low latency. This cutting-edge engine is built upon FriendliAI’s groundbreaking batching and scheduling techniques, which are protected by patents in the United States and Korea, including U.S. Patent No. 11,514,370, U.S. Patent No. 11,442,775, Korean Patent No. 10-2498595, and Korean Patent No. 10-2479264.
PeriFlow is fast and versatile, attracting a growing number of companies that develop their own LLMs through pretraining or fine-tuning open-source LLMs. Supporting a broad range of LLMs, including GPT, GPT-J, GPT-NeoX, MPT, LLaMA2, Dolly, OPT, BLOOM, T5, FLAN, UL2, and more, PeriFlow offers diverse decoding options such as greedy, top-k, top-p, beam search, and stochastic beam search. Furthermore, it supports multiple data types, including fp32, fp16, bf16, and int8. With PeriFlow, users can optimize the balance between precision and speed.
PeriFlow Cloud simplifies the adoption of PeriFlow for organizations of any scale. With PeriFlow Cloud, users can enjoy exceptional speed at low costs (70~90% GPU savings) for LLM serving without the hassle of cloud resource setup and management.
Through PeriFlow Cloud, users can centrally manage every deployed LLM from anywhere. Users are able to effortlessly upload model checkpoints, deploy models, and instantly send inference requests. Comprehensive monitoring tools empower users to track events, errors, and performance metrics while interactively testing deployed LLMs in the playground. It dynamically handles performance and fault issues while auto-scaling based on traffic patterns, freeing users to focus on creating LLMs and driving innovation.
Byung-Gon Chun, Founder & CEO of FriendliAI, emphasizes the significance of efficient LLM serving, stating “Generative AI is revolutionizing our lives, enabling more creative, intelligent, and productive services. Many organizations are now training their own models, but they have yet to fully realize how costly and painful it is to serve these models at scale for a large user base.”
“We’re due for a significant transformation in the way we serve LLMs to empower organizations to fully harness the potential of their LLMs,” Chun adds. “PeriFlow Cloud is an instant and cost-effective solution. We are incredibly excited to see the innovative services users will develop with their generative AI models, powered by PeriFlow Cloud.”
The public beta version of PeriFlow Cloud is now available. Users can deploy their large language models (LLMs) on PeriFlow in a matter of minutes. Visit https://t.co/GdttOvRgSo to get started today.
FriendliAI announced that they will be presenting their research BPipe, which accelerates the training of large language models like ChatGPT, at the International Conference on Machine Learning (ICML '23) on July 26.
https://t.co/sq9O9zXiRb
We are thrilled to announce that our groundbreaking research on LLM training has been accepted for oral presentation at ICML ’23! In our latest work, we introduce a novel parallelism method for LLM training. For more details, please visit our blog post. https://t.co/DZ8MLZxO1N
#friendliai #generativeai #periflow #llm #training
We are happy to share that you can now run highly sought-after open-source LLMs, MPT, LLaMA, and Dolly, on Periflow! Periflow provides high serving performance powered by our patented technology. 🚀
Get more information in our blog post: https://t.co/orDLOMEJC2
#friendliai #periflow #llm #mpt #llama #dolly #generativeai #inference #serving
FriendliAI holds patents on groundbreaking batching techniques that unlock unrivaled speed on LLM inference. Supercharge your LLM serving with the game-changing advantage of FriendliAI’s patented batching technology using PeriFlow today!
#patent#llm#inference#batching