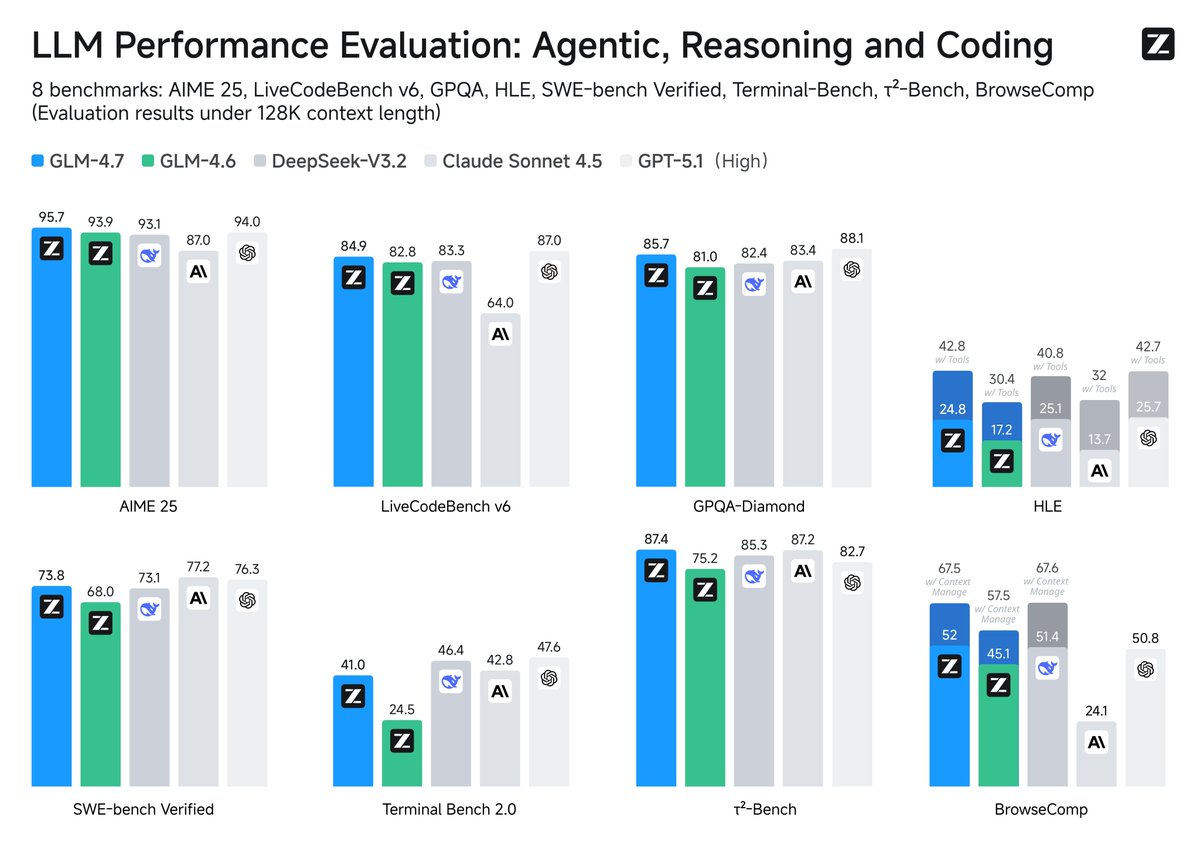
GLM-4.7 is here!
GLM-4.7 surpasses GLM-4.6 with substantial improvements in coding, complex reasoning, and tool usage, setting new open-source SOTA standards. It also boosts performance in chat, creative writing, and role-play scenarios.
Default Model for Coding Plan: https://t.co/Nk8Y98Il7s
Try it now: https://t.co/WCqWT0raFJ
Weights: https://t.co/CpKNBpXTWu
Tech Blog: https://t.co/CfXPHbrBPm
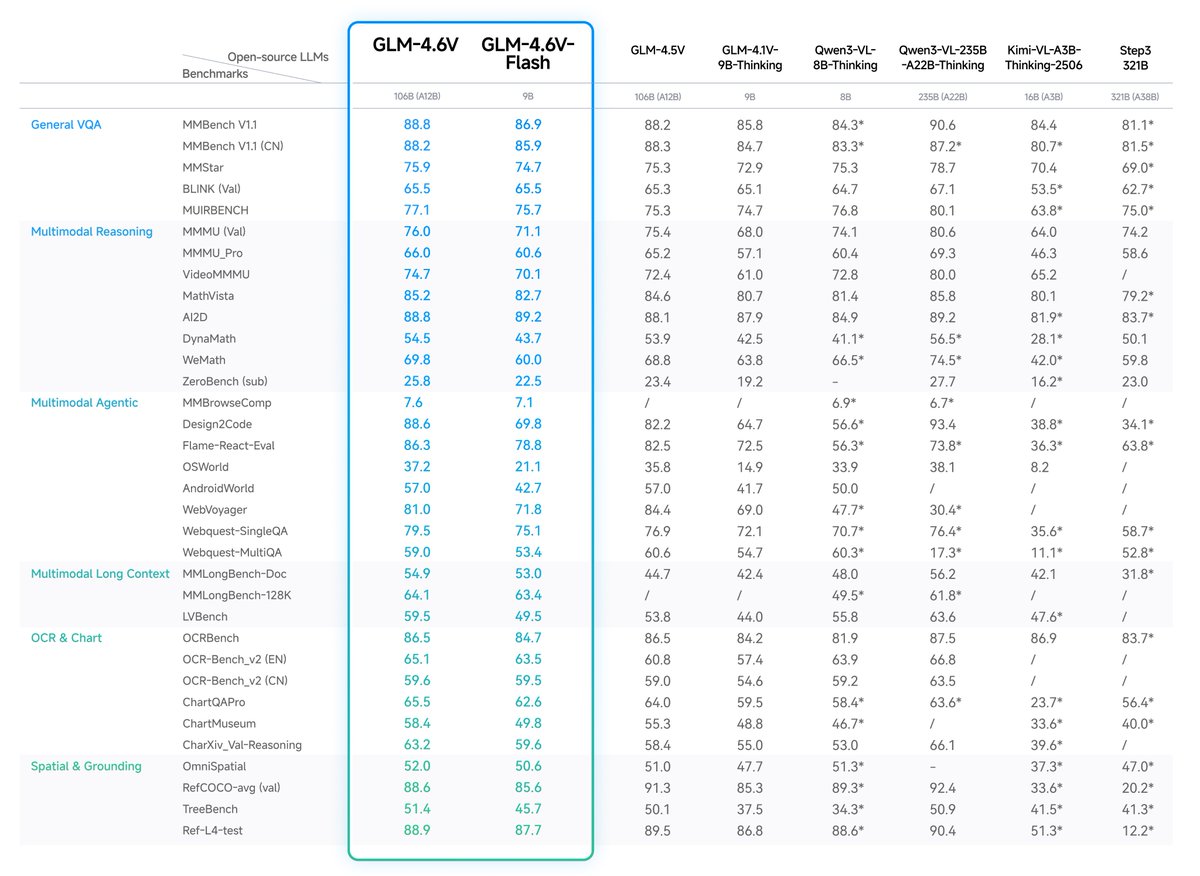
GLM-4.6V Series is here🚀
- GLM-4.6V (106B): flagship vision-language model with 128K context
- GLM-4.6V-Flash (9B): ultra-fast, lightweight version for local and low-latency workloads
First-ever native Function Calling in the GLM vision model family
Weights: https://t.co/vKmNosrHeo
Try GLM-4.6V now: https://t.co/WCqWT0raFJ
API: https://t.co/pPSGa3meyS
Tech Blog: https://t.co/w9t96C2EKQ
API Pricing (per 1M tokens):
- GLM-4.6V: $0.6 input / $0.9 output
- GLM-4.6V-Flash: Free
@JeffKazzee@jandotai To be honest, I don't really trust this company. I haven't found any major issues with this model yet, but the biggest problem is...glm4.6 is actually cheaper (because the token capacity is much larger) and performs better.
@carlo_clores@elonmusk I don't think Minimax performs as well as glm, and it's also more expensive than GLM (because Minimax's token quota is actually quite low, so the average cost is actually higher than GLM).