@kyr_dreamer@jobergum@HornetDev from the blog post:
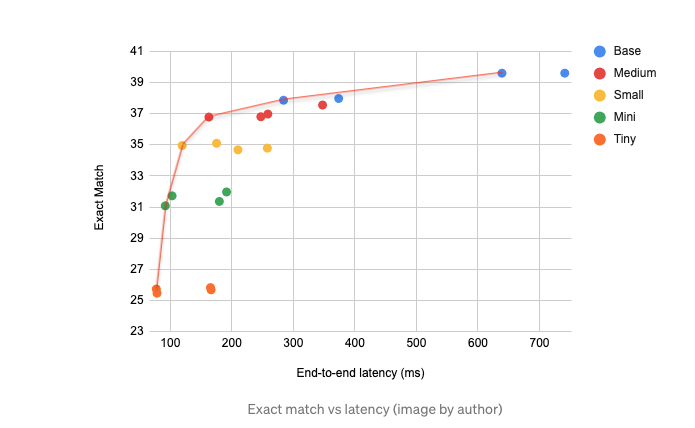
> Each test ran on a single AWS Graviton4 instance with 32 vCPUs and 128 GiB of memory. Hornet served the 100M-document index entirely from memory in about 56 GiB.
We have updated our news search and recommendation tutorial for https://t.co/UqaWLT7FpD - A small thread to highlight some awesome Vespa features which are demonstrated in the tutorial 🧵1/10
From research to production: scaling a state-of-the-art machine learning system.
A lot of experiments went into this blog post. From a set of research python scripts to a production ready web serving using @vespaengine.
https://t.co/BYoB6cxGZa
https://t.co/DeeL552LX3
Great blog post on using https://t.co/UqaWLT7FpD for matching and ranking people! A challenging use case with intricated matching constraints. https://t.co/U1I8v7dqLw
Very proud of @verizonmedia’s @vespaengine (#opensource big data serving engine) for stepping up to the COVID-19 Open Research Dataset Challenge (CORD-19) and making helpful data easily searchable. You can read about the Challenge here: https://t.co/7TmsywOBO7
The @vespaengine (#opensource big data serving engine) team indexed 45k scholarly articles and created a search engine (https://t.co/4hB29y35X6) to help the medical community efficiently sift through research and synthesize the findings. This is how we move #forwardtogether.
One of many applications which uses @vespaengine in @verizonmedia. Check out this presentation from AWS re:Invent 2019: How Verizon Media implemented push notification using Amazon DynamoDB. 150K/s push notifications, resolving of targets done by Vespa. https://t.co/QstnrvJ4ju
If you have https://t.co/myUCfjaZQm it's not too late to make yourself a state of the art and infinitely scalable e-commerce site in time for Black Friday.
@jobergum explains how in https://t.co/0DYPVNWU6g