Vespa is now available as a Document Store in Haystack. Use VespaDocumentStore for hybrid and semantic search with a powerful, production-ready engine, and pair it with VespaEmbeddingRetriever to index and retrieve documents directly in your pipelines. Metadata filtering included.
@vespaengine excels at large-scale information retrieval with advanced features like real-time indexing, multi-modal search, and distributed document management - ideal for applications that demand both speed and sophistication.
🐍 pip install vespa-haystack
🔗 https://t.co/Z1pz3A32tz
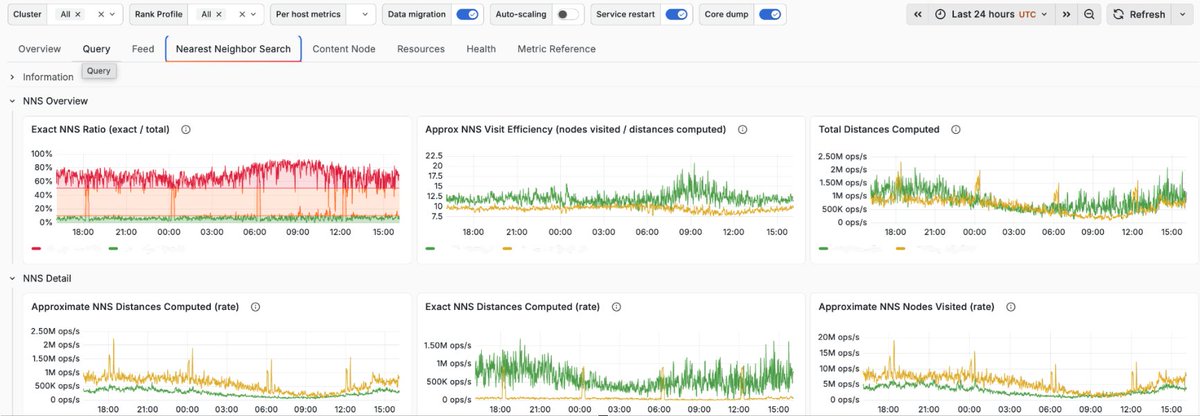
Detailed metric dashboards: Some people like to dig deep, and using a cloud solution shouldn't prevent them. We've made all the dashboards user by Vespa operators available in the Vespa Cloud console out of the box.
bm25 is nice and all, but you won't believe how easy it is to improve upon it with and how much more you can squeeze from lexical features in @vespaengine
Cluster-size independent config of relevance effort: Vespa has several parameters that let you influence how much effort should be spent on relevance quality for a query, such as ANN and WeakAnd targetHits, and second-phase rerank-coint.
These have been set in terms of amounts per node, which is impractical when the number of nodes change, and doesn't work well with autoscaling.
Now we have added variants prefixed by "total" which sets the effort over the whole cluster instead.
The May https://t.co/abkb8IjPSH Newsletter is out!
This month we’re announcing updates focused on retrieval quality, ranking flexibility, and developer productivity (agents: try out the skills and let us know).
- Vespa Cloud: Detailed metric dashboards
- Vespa Cloud: Index backup
- Vespa Cloud: Fine-grained maintenance controls
- Vespa Cloud: Custom resource tags
- Vespa skills for agents
- @VoyageAI , @OpenAI , and @MistralAI embedders
- A new query operator for text matching
- Cluster-size independent config of relevance effort
- Boolean array fields
- Match specific array elements
- In-memory document ids
- Search group pinning
- Near matching aware ranking
- Detect ignored write operations
- Accessing the max first phase score in re-ranking
- Geo distance in grouping
Read it here: https://t.co/jC8Ewk7Lb5
One skill that will particularly accelerate the move to modern AI search is our ElasticSearch migration skill: https://t.co/EptZnaiERk
We're already getting feedback saying this enabled people to migrate complex ES applications to Vespa in less than a day.
Vespa skills for coding agents: Claude Code and competitors are very useful for working on Vespa applications. Everything is always completely specified in application packages, which are in their favorite form factor.
Still, they do better with a good collection of skills. Skills are a dime a dozen though, what you want are skills that are proven by evals to carry more than their own weight.
We're maintaining a collection of optimized and evaluated skills you can grab here: https://t.co/XU7yuOoJQ2
Fine-grained maintenance controls: One consequence of Mythos-like capabilities soon being broadly available is that we'll need to get used to upgrade all parts of the software stack much more frequently. You're already working on a plan for this, right?
Those running on Vespa Cloud are already in great shape here since platform and OS upgrades just happen automatically. We'll need to make OS upgrades more frequent though, which means they'll be more intrusive. That's why we have added controls that allows you to specify at what time windows they can happen.
Index backup: Since indexes on Vespa are realtime, backing them up is not straightforward. However, this may make disaster recovery much faster. You can now turn on automated index backups on Vespa Cloud
Detailed metric dashboards: Some people like to dig deep, and using a cloud solution shouldn't prevent them. We've made all the dashboards user by Vespa operators available in the Vespa Cloud console out of the box.
Radu Gheorghe is a software engineer at @vespaengine. He joins @seanfalconer to discuss vector search limits, tensor based retrieval, ranking tradeoffs, and where AI search is headed next.
@radu0gheorghe
https://t.co/8ANaLTuFzB
I really look forward to our first @vespaengine full-day community event in London, September 10! Don't forget to submit a talk, or just hang out with other practitioners. Secure your Early-bird ticket now!
This is an event to learn from each other and get inspiration for how to build state-of-the-art applications: https://t.co/v1Ovdmvz3f