Most vector databases treat retrieval as a single operation. That's the wrong abstraction.
Storing embeddings and returning nearest neighbors is a solved problem. The hard problem is what happens next. We solve it through composable vector search, built in Rust.
Today, led by AVP, with Bosch Ventures, Unusual Ventures, Spark Capital, and 42CAP, we're announcing our $50M Series B to accelerate it.
Learn more about Qdrant’s composable vector search and our latest funding round here: https://t.co/oUfi99APjt
When you're running GenAI on the edge, you don't get to blame the network.
Alan Zhu from @Qualcomm is coming to Vector Space Day to talk about what it means to build for on-device inference, where latency isn't a tradeoff to manage but the thing users feel with every interaction.
Join 300+ AI builders for a full day on agents and memory in production, retrieval from cloud to edge, and multimodal AI. Get your ticket: https://t.co/a190Cwv5EF
Search is one of the most important parts of the e-commerce experience, and one of the hardest to get right.
That’s why we’re excited to be speaking at MICES 2026, the e-commerce search meetup and official satellite event of Berlin Buzzwords.
@krotenWanderung from Qdrant will present:
“Fine-Tuning Sparse Neural Retrievers for E-Commerce Is Not That Scary (And Often Worth It)” based on @ptdamiba's work!
For more info: https://t.co/KHhTExRmIq
The session explores the practical side of sparse retrieval and SPLADE:
→ When sparse neural retrieval makes sense for e-commerce
→ Fine-tuning strategies that actually improve relevance
→ Hard negative mining and evaluation
→ Building an end-to-end retrieval pipeline
Date: June 10
Link: https://t.co/IeXLskJCEb
Where does AI memory actually live right now? In markdown files, vectors, graphs, a mix of all three? Dave Nielsen from @cognee_ is coming to Vector Space Day to cut through the hype and map out what short and long-term memory look like in real systems today, and where it's all heading.
Vector Space Day is a full-day single-track conference for engineers going deep on retrieval and agent memory. We also have talks on retrieval from cloud to edge, and multimodal AI.
If you’re building something novel in vector search, AI memory, context engineering, or retrieval infra, get your ticket for June 11: https://t.co/a190Cwv5EF
Video is the most information-dense modality we have, and most retrieval pipelines treat it like text with pictures.
James Le from @twelve_labs is coming to Vector Space Day to show what's actually possible when you build multimodal retrieval right, from semantic search across sports and audio to agentic workflows that handle object tracking and highlight generation at scale.
If you're curious where vector search is heading, this is a session worth being in the room for. Join us at The Midway: https://t.co/a190CwvDud
No plans this weekend? There's still time to compete in our virtual hackathon! Submission deadline is Monday, $10k up for grabs
https://t.co/DsZXTqMvJH
Most in-car media systems still expect you to search with keywords.
But when you’re driving, you don’t think in keywords - you think in moods, vibes, and intent.
This project by Sarvesh Talele, built with Qdrant Edge, creates a fully local AI-powered media discovery system that lets users search music semantically through voice, text, and mood-based queries.
What’s interesting:
→ Local voice transcription with Whisper
→ Semantic retrieval with vector embeddings
→ On-device vector search using Qdrant Edge
→ No cloud dependency required
A great example of how vector search can power privacy-first, real-time experiences directly on-device.
Read here:
https://t.co/hQrftThDOu
𝗘𝗻𝘁𝗲𝗿𝗽𝗿𝗶𝘀𝗲 𝗔𝗜 𝗰𝗮𝗻𝗻𝗼𝘁 𝘀𝘁𝗼𝗽 𝗮𝘁 "𝗺𝗼𝘀𝘁 𝗿𝗲𝗹𝗲𝘃𝗮𝗻𝘁 𝗿𝗲𝘀𝘂𝗹𝘁."
At Vector Space Day SF, @Adobe and @neo4j will show how governed retrieval, GraphRAG, and context graphs make agents faster, safer, and more explainable.
Register: https://t.co/VgxELoVEH4
Tweaking chunk sizes and running a few demo queries is not an evaluation strategy.
Laurie Voss (Head of DevRel, @arizeai) is coming to Vector Space Day on June 11 to replace vibes with measurement: the retrieval metrics that matter, golden datasets that survive contact with reality, and how to wire evals into CI so you find out about regressions before your customers do.
If you’re building something novel in vector search, AI memory, context engineering, or retrieval infra, check out Vector Space Day on June 11 at The Midway: https://t.co/a190CwvDud
Berlin folks 🇩🇪
Join us for an evening focused on AI retrieval, agents, and modern search systems.
We’ll be at the event below discussing how retrieval is evolving in the age of agents, production RAG, memory systems, and vector search: https://t.co/zTuvAQ5UrM
And we’re not stopping there - later the same day, we’re also hosting our Vector Space Meetup: Retrieval in the Age of Agents at the same location!
Expect great discussions, networking, and builders from across the AI ecosystem.
Meetup link: https://t.co/BnEdTYQ3uT
See you in Berlin 🙌
About 90% of enterprise data is unstructured, and most of it lives in documents. PDFs, spreadsheets, Word files, the stuff that runs businesses. Preston Carlson from @llama_index is coming to Vector Space Day to talk about why even frontier models struggle with real-world documents, and what better OCR and agent harnesses actually unlock.
Vector Space Day is a full-day conference for engineers building the next generation of retrieval systems. Get your ticket for June 11 at The Midway, SF:
https://t.co/a190CwvDud
We’re hosting Vector Space Meetup: Retrieval in the Age of Agents on June 11.
RAG is the architectural foundation of production AI, and retrieval has fundamentally changed over time. Agents don’t just retrieve anymore - they decide when to search, what to search for, and whether results are good enough to act on.
We’re gathering builders shaping this shift: @cognee_, @n8n_io, @deepset_ai, and @llama_index for a panel driven entirely by YOUR questions.
You’ll also hear from Qdrant’s Co-Founder & CTO, @generall931, who will join for open discussions and networking with attendees.
Join us! Register (approval required): https://t.co/BnEdTYQBkr
Building an AI agent is one thing. Building one that's intelligent, reliable, and actually ready for an enterprise environment is a different problem entirely.
Gabriel Lebow from @Vultr is coming to Vector Space Day to frame the key architectural ideas behind production-ready agentic AI: how scalable systems support context-aware reasoning, handle real-time decision-making, and hold up when the stakes are real.
Get your ticket at https://t.co/a190Cwv5EF
Today we're announcing Aman as our exclusive partner in Israel.
Israeli enterprise teams (in banking, insurance, manufacturing, gaming, and beyond) are building production AI on top of search infrastructure that wasn't designed for it.
Qdrant is purpose-built for that next stage: a composable vector search engine written in Rust, with predictable low-tail latency at billion-scale across cloud, on-prem, hybrid, and edge.
Java-based engines, Postgres solutions, and vector add-ons can't deliver the latency or accuracy that modern agentic and RAG workloads need.
Aman brings 25+ years of experience modernizing data infrastructure for Israeli enterprises. Pairing their reach and local expertise with Qdrant's engine gives Israeli teams a faster path from "this isn't working" to production AI that performs.
If you're evaluating vector search in Israel, talk to Aman: https://t.co/AOyf6LaS3R
Vectors tell you what's similar. They don't tell you what's connected. Stephen Chin (VP of Developer Relations, @neo4j) is coming to Vector Space Day to talk about how context graphs give agents the relational understanding they need to actually reason, not just retrieve.
Join 300+ AI builders for a full day on agents and memory in production, retrieval from cloud to edge, and multimodal AI. Join us June 11 at The Midway, SF. Get your ticket at https://t.co/a190CwvDud
Paige Bailey from @GoogleDeepMind has a question for anyone building agents: why are humans still writing static markdown files to tell your agent what it can do?
She's coming to Vector Space Day to make the case that SKILLS.md is a transitional phase, and to talk about what replaces it.
If you're building production agents, this one's for you. June 11 at The Midway, SF. Get your ticket at https://t.co/a190Cwv5EF
Most teams think continual learning is a training problem. Taranjeet Singh from @mem0ai thinks they're solving the wrong thing. At Vector Space Day on June 11, he'll show how giving agents better memory, not better gradients, is what actually makes them improve over time in production.
Vector Space Day is a full-day conference for engineers going deep on vector search, retrieval, and agent memory. Join us in San Francisco.
Grab your ticket at https://t.co/a190CwvDud
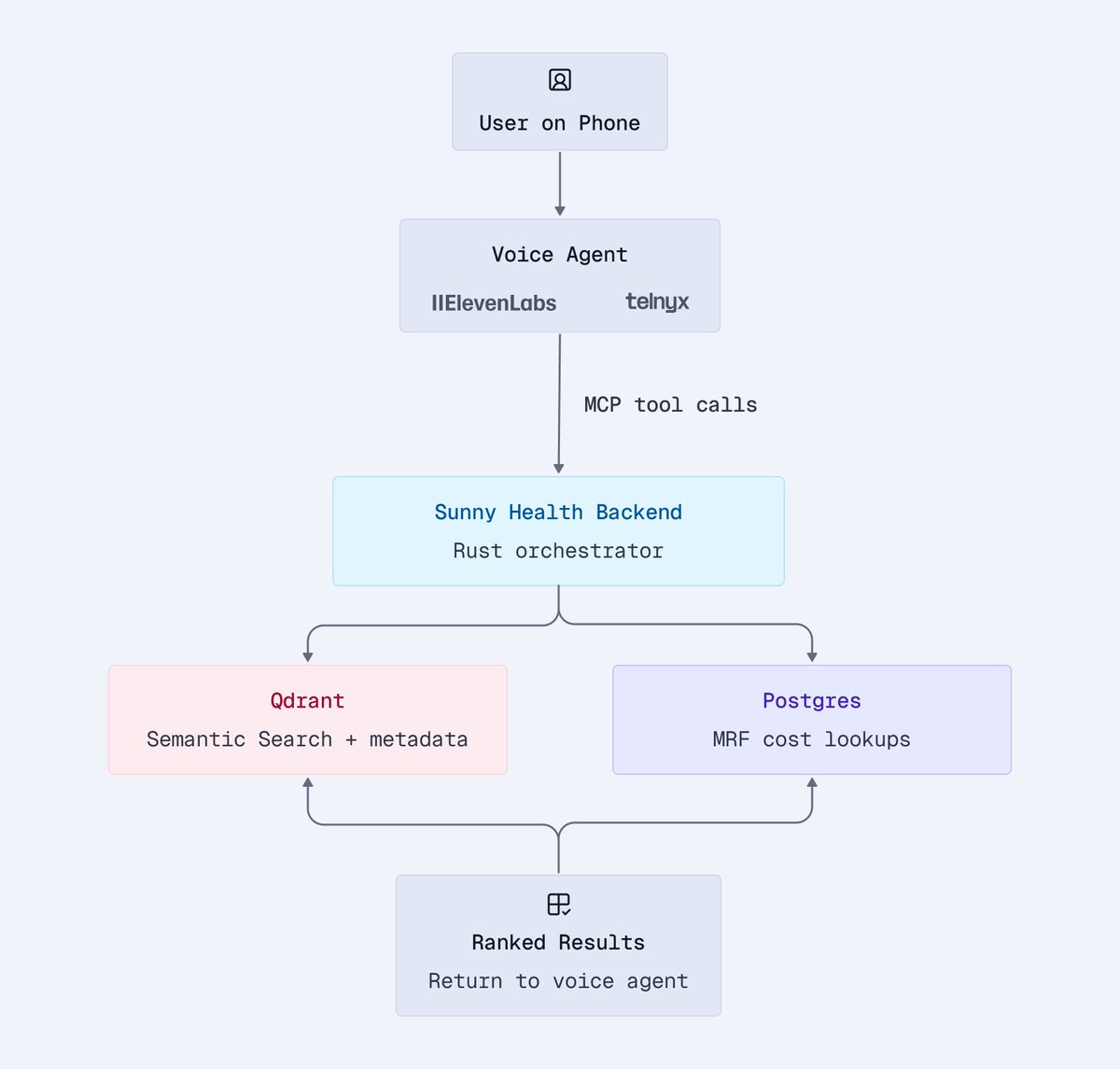
Most people pay for insurance and barely understand what it covers. The pamphlet is dense, the insurer’s website is complex, and finding an in-network provider with availability takes more energy than most patients have.
@SunnyHealthAI is building a healthcare concierge that insurance companies and care providers offer to their members. Members sign in through their payer, the platform already knows their plan and benefits, and a chat experience helps them find in-network providers and book real appointments through an AI voice agent.
The retrieval engine underneath is Qdrant. @SunnyHealthAI migrated from Postgres because the schema rigidity slowed every new metadata field they wanted to add, and fuzzy matching couldn’t handle precise patient queries. They needed hybrid search (must-filters expressed alongside semantic ranking), first-class geo re-ranking, and a flexible payload model for deeply nested provider records.
That same retrieval layer now powers patient search and the AI voice agent that books appointments on patients’ behalf.
Read how they built it:
https://t.co/84Sn9auQul
Excited to share that Qdrant will be speaking at the @MistralAI AI NOW Summit in Paris 🇫🇷
Chadha Sridi (Developer Advocate at Qdrant) will present:
“Semantic Search on Messy Documents with @MistralAI OCR and Qdrant”
We’ll explore how semantic search + OCR can turn noisy, unstructured documents into searchable, usable knowledge using @MistralAI and Qdrant.
Looking forward to connecting with the AI community in Paris 🙌
Link: https://t.co/zjcB89V6Xg
TurboQuant Webinar Reminder
Better compression without sacrificing recall 👀
Join us on May 26 to see:
→ TurboQuant vs SQ/BQ
→ Real benchmark results
→ Production tradeoffs
→ Live technical walkthrough
🗓️ May 26
🔗 https://t.co/SD3a6PZvWU