(6/n) Looking forward: While these new reasoning models aren't fully practical yet, they show huge potential. Once they solve the fast/slow thinking problem and learn when to stop deliberating, they'll be game-changing. My prediction? The future belongs to such thinking models!
A Quick Deepseek R1 Testing for SQL Generation (with Waii)
Finally got to test Deepseek R1! Tried both versions: distilled LLaMA 8B from R1 (runs in local ollama) and Deepseek R1 (671B) from fireworks. Here's what I discovered. 🧵
(5/n) About the distilled model - don't get too excited. It can't handle complexity:
- Struggles with AMC-8 (8th-grade math competition) questions -- just went into an infinite loop of output and cannot give me an answer.
- Can't generate SQL based on the schema input.
(4/n) more downside:
- Query generation takes 4-5 mins vs 10-20 secs with GPT-4o
- Most time is spent on unnecessary self-debate. The solution is clear in first 20-30% (40-60 secs), but it keeps rewriting and second-guessing the correct solution
(3/n) Downsides? Everything comes with a cost:
- Model takes long <think> output for any task, even simple entity extraction
- I still need to use GPT-4o for quick tasks (reranking, entity extraction) during the test, otherwise it will take forever.
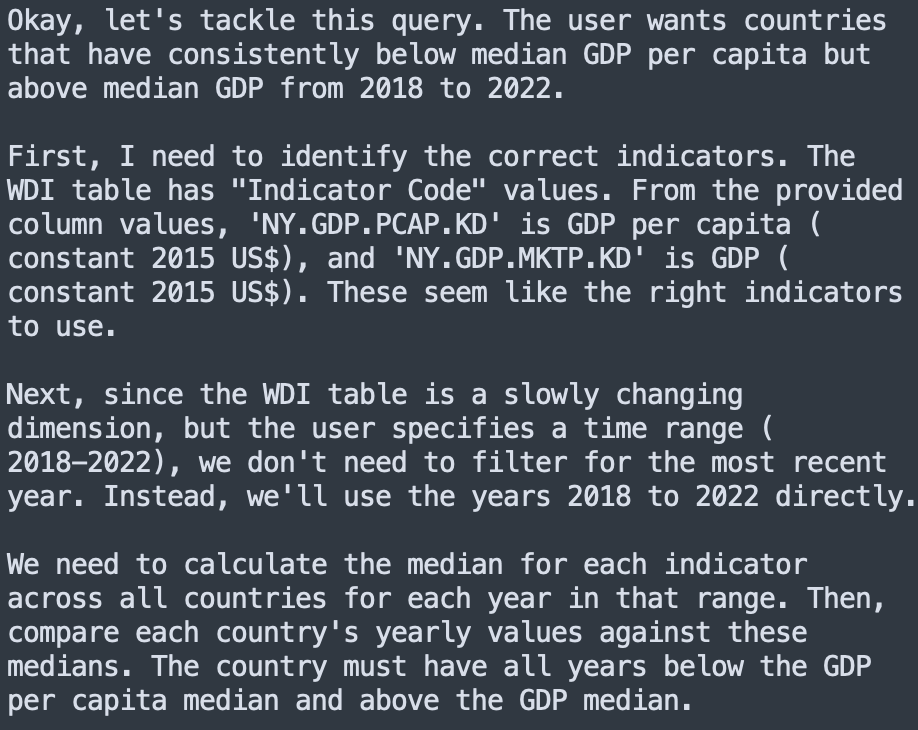
(2/n) R1 is REALLY good at understanding aggregation. Current models like GPT-4o, Claude 3.5 sometimes mess up complex aggregations (like avg of daily avg sales) or window functions with filters. But R1 handles these consistently better than other models I've tested. Example:
(1/n) 1) The self-debate is fascinating - it's like watching a real, capable but hesitant person think through problems. Check out this snippet for one of the query
Mobile ALOHA's hardware is very capable. We brought it home yesterday and tried more tasks! It can:
- do laundry👔👖
- self-charge⚡️
- use a vacuum
- water plants🌳
- load and unload a dishwasher
- use a coffee machine☕️
- obtain drinks from the fridge and open a beer🍺
- open doors🚪
- play with pets🐱
- throw away trash
- turn on/off a lamp💡
Project website: https://t.co/9rzIX8wLEp
Co-lead @tonyzzhao, advised by @chelseabfinn
(amazing photographing from @qingqing_zhao_ )
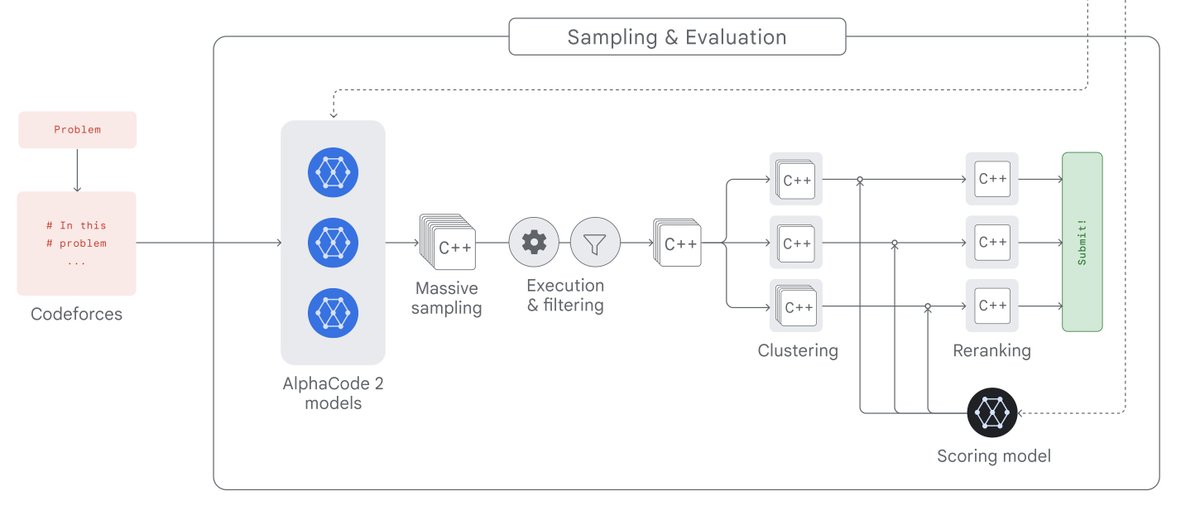
AlphaCode-2 is also announced today, but seems to be buried in news. It's a competitive coding model finetuned from Gemini. In the technical report, DeepMind shares a surprising amount of details on an inference-time search, filtering, and re-ranking system. This may be Google's Q*? 🤔
They also discussed the finetuning procedure, which is 2 rounds of GOLD (an offline RL algorithm for LLM from 2020), and the training dataset. AlphaCode-2 scores at 87% percentile among the human competitors.
Don't miss it: https://t.co/A8Y64cAqrx
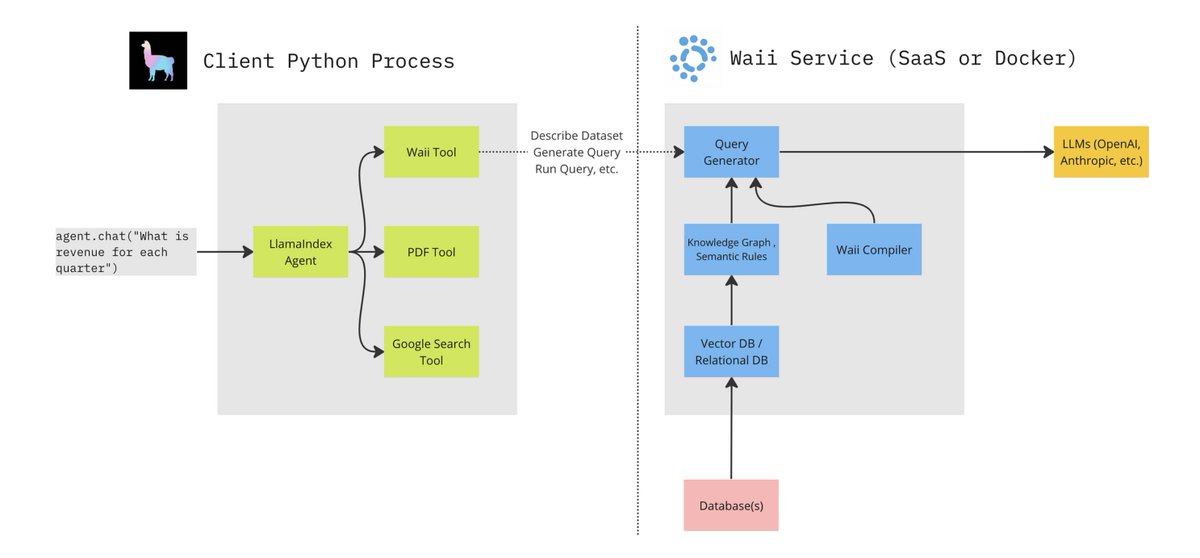
Building advanced text-to-SQL is hard. Building advanced QA over both structured and unstructured docs is even harder.
We’re excited to feature a blog by @leftnoteasy (https://t.co/gumBYCXYl2) - build an agent that can query enterprise-grade DB’s along with PDF data, with @llama_index + https://t.co/gumBYCXYl2
The enterprise text-to-SQL consists of the following:
✅ Knowledge Graph modeling metadata/query history to help table/schema selection
✅ Semantic rules: guide producing the right queries
✅ Automatic error correction through query compiler
We use this over a SQL database of retail data, and combine this with a @llama_index RAG pipeline over a Deloitte PDF report. This allows our agent to compare the structured/unstructured data ⚖️ - e.g. the top items sold during the holidays.
Check out the full blog! https://t.co/5N2Yjnluc1
Notebook: https://t.co/DsbnO96Err
Signup with Waii here: https://t.co/RGHCfGQhvI
Building advanced text-to-SQL is hard. Building advanced QA over both structured and unstructured docs is even harder.
We’re excited to feature a blog by @leftnoteasy (https://t.co/gumBYCXYl2) - build an agent that can query enterprise-grade DB’s along with PDF data, with @llama_index + https://t.co/gumBYCXYl2
The enterprise text-to-SQL consists of the following:
✅ Knowledge Graph modeling metadata/query history to help table/schema selection
✅ Semantic rules: guide producing the right queries
✅ Automatic error correction through query compiler
We use this over a SQL database of retail data, and combine this with a @llama_index RAG pipeline over a Deloitte PDF report. This allows our agent to compare the structured/unstructured data ⚖️ - e.g. the top items sold during the holidays.
Check out the full blog! https://t.co/5N2Yjnluc1
Notebook: https://t.co/DsbnO96Err
Signup with Waii here: https://t.co/RGHCfGQhvI
Fine-Tuned GPT-3.5 vs. GPT-4 For SQL Generation The results? We found that the fine-tuned version outperformed GPT-4, achieving higher accuracy at 1/3 of the cost! We also explore how fine-tuning affects readability and SQL statements usage. link: https://t.co/ztD4qupWol 🚀
@yakrobat 5/5 🔮 #GPT4 has ushered in a new era of AI capabilities for SQL generation. Stay tuned for more updates as we push the boundaries of what's possible in automating SQL generation and data analytics!
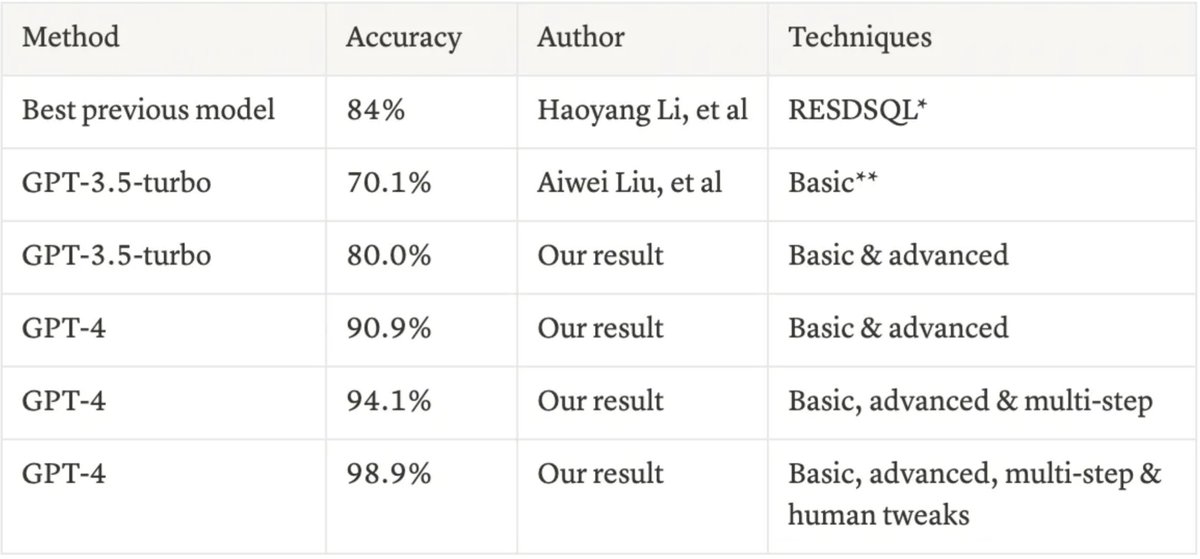
GPT-4's SQL Mastery: Solved 'Text to SQL' Problem?
@yakrobat and I collaborated on research that demonstrates GPT-4's impressive SQL generation abilities through fine-tuning and optimized techniques (Read our blog post: https://t.co/hEdLCmwInU). Summary see this 🧵
@yakrobat 4/5 🌐 Our goal is refining GPT-4's query generation for enterprise warehouses. Challenges include testing on real-world databases, handling wide data models, and generating complex queries. We're working on addressing these limitations. #AI#Enterprise
@yakrobat 3/5 🛠️ Techniques like constraints, query examples, samples, semantics, and human guidance help optimize SQL generation. However, complexity remains a challenge, with more complex queries less likely to succeed. #FineTuning#AI
@yakrobat 2/5 🧪 We tested GPT-4 on the Spider dataset, a SQL generation benchmark. Our evaluation focused on query result correctness. With proper prompting and tuning, GPT-4 outperforms previous methods. #Benchmarking#ML