Good news for the future of in-depth independent reporting: The Alicia Patterson Foundation is joining forces with The Fund for Investigative Journalism https://t.co/EkBj6SJYZS
Scientists have created one of the most detailed 3D reconstructions of a human cell (eukaryotic cell) ever produced.
This groundbreaking model, often termed a "Cellular Landscape Cross-Section Through a Eukaryotic Cell," combines data from X-ray tomography, nuclear magnetic resonance (NMR), and cryo-electron microscopy to map molecular structures in extreme detail.
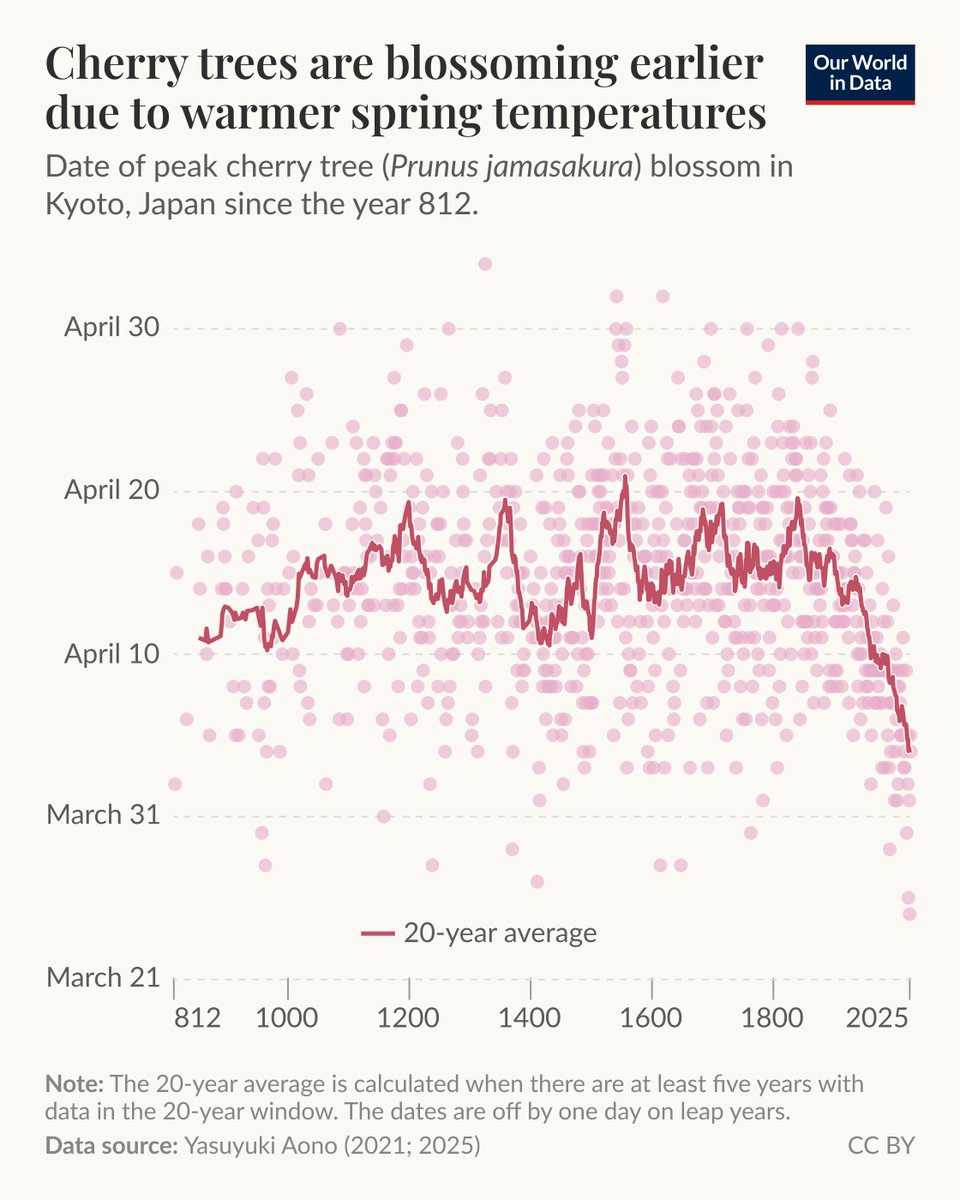
I'm a data scientist @OurWorldinData and I need help from a botanist or someone local to Kyoto, Japan! 🌸
We present one of the world’s longest climate records: 1,200 years of peak cherry blossom dates in Kyoto.
The researcher who maintained it, Professor Yasuyuki Aono, sadly passed away last year.
The FDA won’t tell Americans where their generic drugs are made, so ProPublica did it instead.
Use information from your prescription label to locate the factory and see if the plant has a history of inspection violations.
https://t.co/10GXAeIOtp
For the first time, scientists have measured atmospheric gases from the late Pliocene, yielding data that could help to predict the future climate https://t.co/qrZCPGIU7k
It’s not every day that one gets to listen to a former British Prime Minister recite from memory the opening passages of The Iliad in Ancient Greek, with no notes, in response to a random question from an undergraduate—and all while wearing what appear to be Thomas The Tank Engine socks. But today was one such day.
My thanks to my good friend Brad LaMorgese for the opportunity to see the colorful and comic Boris Johnson speak tonight at the University of Dallas.
the boom in autism therapy is Medicaid’s fastest-growing jackpot : $29 million to treat 84 kids https://t.co/Jv1Q6OSgzV
The terrible trio strike again @cdweaver@mcgint@annawmathews
Antarctic sea ice extent in 2026 neared the long-term summer average after four years of extreme lows, yet remained below the 1981–2010 norm, highlighting ongoing climate variability. https://t.co/FprCZqaCcG
Scientists believe the Milky Way is flying through space at 600 kilometers per second while also wobbling slightly, as if it’s flipping its wings through the cosmos
#A new bio-hybrid memory device combining synthetic DNA and perovskite semiconductors achieves high-density data storage with 100 times less power than traditional electronics. @penn_state https://t.co/MtJ0s1bbkA https://t.co/d9sYpseHce
Mission VA267 by Helix: tracking dense satellite deployments
Deploying dozens of satellites in a single mission is only part of the challenge.
Knowing exactly where they are, and where they are going, is just as critical.
This is where Helix, ArianeGroup’s space surveillance and launch tracking system, comes into play.
Designed to handle dense satellite deployments, Helix processes open-source space data to rapidly detect, identify and predict the trajectories of multiple objects released during complex launch sequences. By optimizing sensor tasking and orbit calculations, Helix delivers early and reliable orbital awareness, from the first moments after separation.
As satellite constellations grow in size and frequency, tracking at scale becomes a strategic capability. Helix is built to meet that challenge, supporting both civil and defence space operations in an increasingly congested orbital environment.
When dozens of satellites are deployed at once, Helix can track them all.
#RocketMakers #Defense #Helix
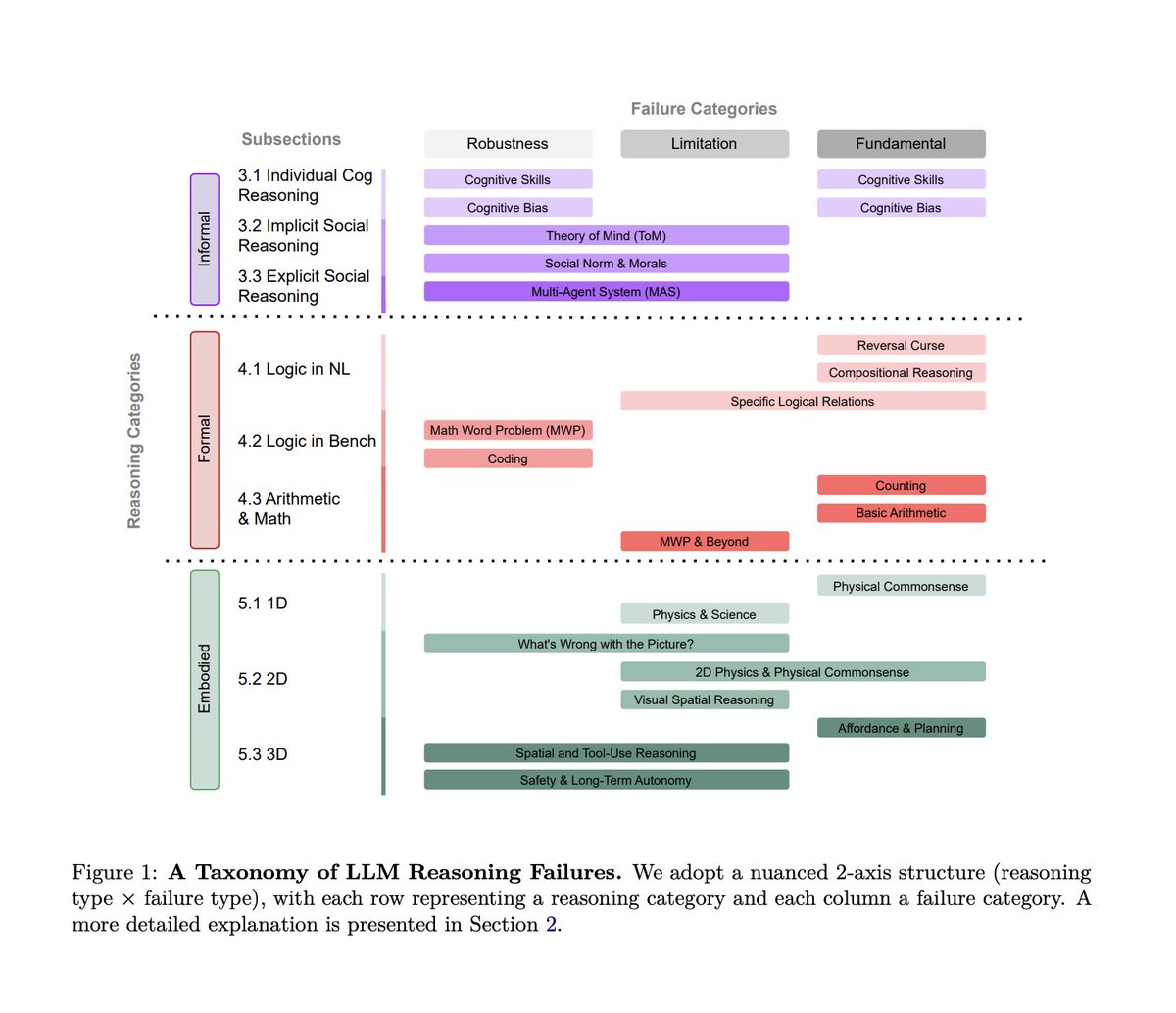
🚨 Holy shit… Stanford just published the most uncomfortable paper on LLM reasoning I’ve read in a long time.
This isn’t a flashy new model or a leaderboard win. It’s a systematic teardown of how and why large language models keep failing at reasoning even when benchmarks say they’re doing great.
The paper does one very smart thing upfront: it introduces a clean taxonomy instead of more anecdotes. The authors split reasoning into non-embodied and embodied.
Non-embodied reasoning is what most benchmarks test and it’s further divided into informal reasoning (intuition, social judgment, commonsense heuristics) and formal reasoning (logic, math, code, symbolic manipulation).
Embodied reasoning is where models must reason about the physical world, space, causality, and action under real constraints.
Across all three, the same failure patterns keep showing up.
> First are fundamental failures baked into current architectures. Models generate answers that look coherent but collapse under light logical pressure. They shortcut, pattern-match, or hallucinate steps instead of executing a consistent reasoning process.
> Second are application-specific failures. A model that looks strong on math benchmarks can quietly fall apart in scientific reasoning, planning, or multi-step decision making. Performance does not transfer nearly as well as leaderboards imply.
> Third are robustness failures. Tiny changes in wording, ordering, or context can flip an answer entirely. The reasoning wasn’t stable to begin with; it just happened to work for that phrasing.
One of the most disturbing findings is how often models produce unfaithful reasoning. They give the correct final answer while providing explanations that are logically wrong, incomplete, or fabricated.
This is worse than being wrong, because it trains users to trust explanations that don’t correspond to the actual decision process.
Embodied reasoning is where things really fall apart. LLMs systematically fail at physical commonsense, spatial reasoning, and basic physics because they have no grounded experience.
Even in text-only settings, as soon as a task implicitly depends on real-world dynamics, failures become predictable and repeatable.
The authors don’t just criticize. They outline mitigation paths: inference-time scaling, analogical memory, external verification, and evaluations that deliberately inject known failure cases instead of optimizing for leaderboard performance.
But they’re very clear that none of these are silver bullets yet.
The takeaway isn’t that LLMs can’t reason.
It’s more uncomfortable than that.
LLMs reason just enough to sound convincing, but not enough to be reliable.
And unless we start measuring how models fail not just how often they succeed we’ll keep deploying systems that pass benchmarks, fail silently in production, and explain themselves with total confidence while doing the wrong thing.
That’s the real warning shot in this paper.
Paper: Large Language Model Reasoning Failures
SpaceX is now providing precise positional awareness of objects in Earth orbit to all satellite operators for free.
This will greatly reduce the probability of collisions that create orbital debris (space junk) hazards.
Writing is thinking
Outsourcing the entire task of writing to LLMs will deprive us of the essential creative task of interpreting our findings and generating a deeper theoretical understanding of the world.