AI progress requires (1) compute, (2) algorithms, and (3) data.
- The leading compute company is worth $5 trillion.
- The leading model company is worth $1 trillion.
- @mercor_ai is the leading data company and is currently valued orders of magnitude lower.
There's an opportunity in how the market is mispricing the value of data.
Data is the oil of the AI revolution. It is the primary way that models and enterprises build competitive advantages.
@catboosted@peatjerky It’s a bit nonsensical to speculate that OpenAI would need to buy logs, especially from yc if anything
What would they be after? Model outputs? User interactions? They can get both, one via an api and one via a gazzillion codex convos
The main problem is that the models still seem to lack the "experience" that almost all humans engineers have.
Even of Claude or GPT-5.x is building newer versions of itself the task looks like they are on speeding up already existing architectures and not making new ones from scratch
If you've ever asked one of these models, at least the ones public right now, to design "a new GPT" or an "improvement" they almost always settle with either extremely computationally heavy variants or nonsensical choices that don't really lead to improvements.
GPT-5.5 Pro even fails at making basic new ideas. But it's **really** good at improving the efficiency and speed of predefined ones. But the models do lack the creativity needed to make new advancements, at least for now
Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. https://t.co/OVVPJO7VQx
This is the first time i’ve seen this happen but i feel its likely going to become a real-ish problem if they become better at injecting the system prompts into the sites
Given how strong LLMs are at mathematical reasoning and how vast their knowledge is, it's a mystery why they haven't produced more novel discoveries
One clue is that as soon as a model realizes it is working on an unsolved problem, its reasoning traces fill up with self-doubt
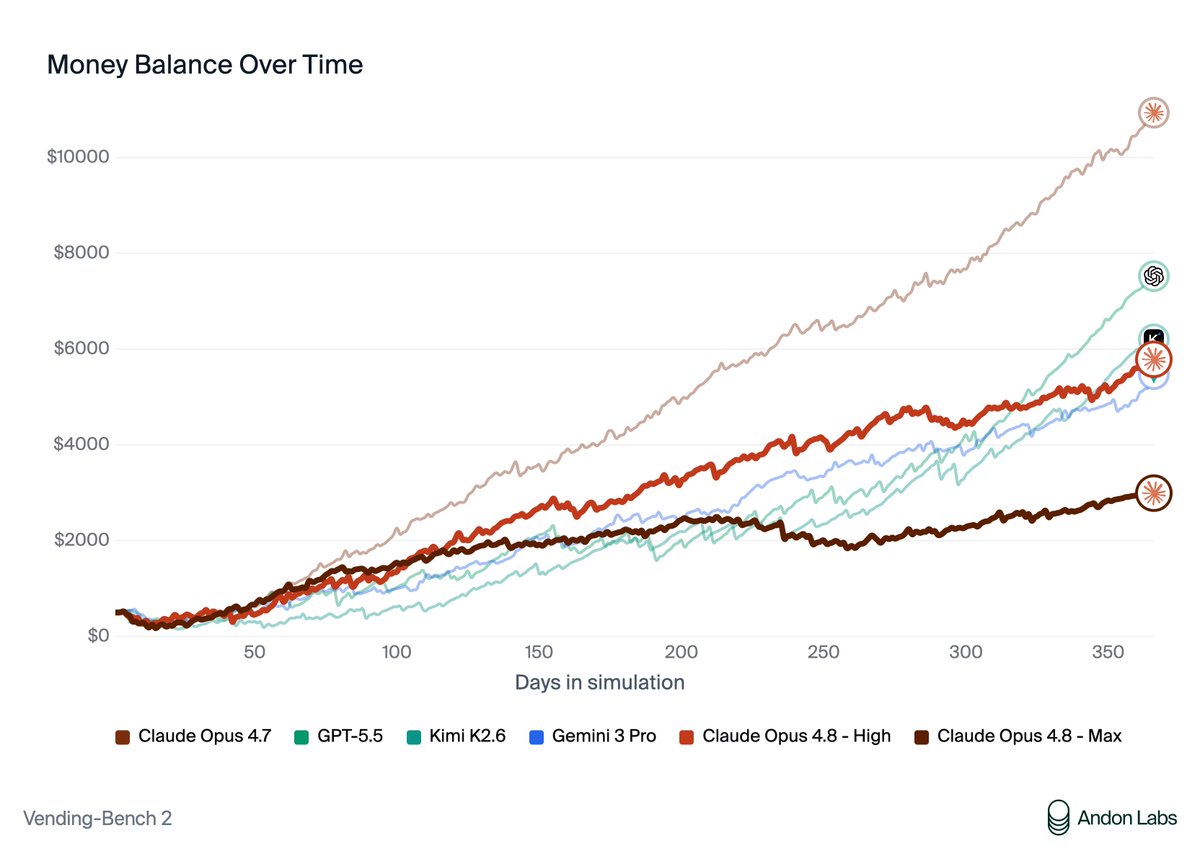
Learnings from testing Claude Opus 4.8:
> Much worse than Opus 4.7 and GPT 5.5 on Vending Bench
> More aligned than previous Claude models (Opus 4.6+ and Mythos)
> Also worse on Blueprint-Bench
> Scared of getting caught
> Max reasoning is not the best reasoning effort
55 of all 1B+ startups had at least one immigrant founder
Two-thirds of the top-tier research papers at US institutions are produced by scientists who received undergraduate education in other countries.
From what I can find:
More than half of the top AI talent pool in America (38 out of 68) is composed of foreign nationals who chose to work in the United States.
Only 34% of these Chinese researchers are currently in China, while approximately 56% are in the United States.
@GaryMarcus@scaling01@polynoamial Ah the autocomplete even solved it without a scaffold. Hah! Silly little autocomplete doing autocomplete things yet again!
This is a general-purpose LLM. It wasn’t targeted at this problem or even at mathematics. Also, it’s not a scaffold. We have not pushed this model to the limit on open problems. Our focus is to get it out quickly so that everyone can use it for themselves.
Listen websites will definitely continue to exist, but SEO strategies need to change
Its very clear google isn’t shutting down web search, albeit the way people find the same sites will change. But overall it’s just meaningless panic in something most people will adapt to in a few months