🥳🥳 Introducing "CoT-ICL Lab" to #ACL2025
A highly flexible (synthetic) data generation framework to study Chain of Thought learning with "In-Context" examples.
TL;DR: This work bridges the gap between theoretical setups and complex NLP settings to study how transformers learn abstract concepts and their underlying causal dependencies. 🧵
Joint work with: @mamhamed, Maziar Sanjabi
We are open sourcing bytecheckpoint and veomni!
bytecheckpoint is the Bytedance's production checkpointing system for foundation model training, battle-tested with jobs with 10k+ GPUs. Blazing fast save/load, load-time checkpoint auto-resharding for different parallelism across training stages (pretrain/SFT/RL).
veomni is a open source model training framework for llm and multi-modal training. UI-TARS (the SOTA GUI Agent model prior to OpenAI operator's release) is trained with veomni. Developed with modular design, integrated with sequence/expert/zero-optimizer parallelism, offloading optimizations, @liger_kernel. Trainer-free (let user control the training loop) and easy for researcher to hack! The go-to framework for text/multimodal llm pre-training and post-training, from research to production.
Try them today, your feedback is welcome!
Code:
- https://t.co/IKM7ceK7GN
- https://t.co/HAzL6Omc6j
Paper:
- NSDI paper: https://t.co/HjHgbjv9r0
🚀 Liger Kernel is Now Live on https://t.co/aDtcSvEjPl!
We're stoked to announce that Liger has landed on https://t.co/aDtcSvEjPl! No more environment setup headaches - just pure, seamless Liger magic at your fingertips.
🔥 Unbeatable Pricing: Get mind-blowing RTX 4090 compute power for just $0.39/hour — one of the best deals in the industry!
🎁 Exclusive Launch Offer: Use Liger's referral code to unlock 8 HOURS of FREE compute time!
⚡️ Limited slots available — act fast before they're gone!
Ready to supercharge your AI workflow?
Jump on board now: https://t.co/VOhSBiVUcm
#LigerKernel #GlowsAI #LLM
Happy Chinese Lunar New Year!
The Liger team is excited to announce our milestone of 1,000,000 downloads! Since our initial release in August 2024, we have observed tremendous growth in both usage and community engagement. We appreciate all the recognition and will continue to deliver high-quality LLM kernels.
We are also happy to announce our open source community's partnership with @glowsai ! @glowsai will sponsor our recognized contributors by providing access to their GPU platform.
They offer one of the most cost-efficient GPU clouds in the market - powered by their advanced orchestration engine Tripods and delivering 80% cost savings compared to major cloud providers. Our community members have been battle-testing it for development, and the experience has been delightful.
Liger Kernel v0.5
https://t.co/VuBKKvywc1
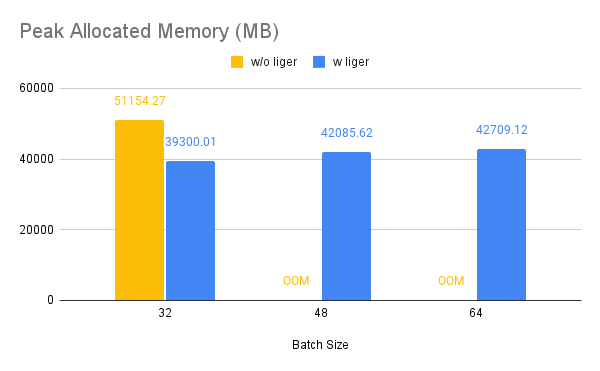
Post Training Loss: Introducing the first open-source optimized post-training losses in Liger Kernel with ~80% memory reduction, featuring DPO, CPO, ORPO, SimPO, JSD, and more. No more OOM nightmares for post-training ML researchers!
AMD CI: With AMD’s generous sponsorship of MI300s, we’ve integrated them into our CI. Special thanks to Embedded LLM for building the AMD CI infrastructure.
XPU Support: In collaboration with Intel, we now support XPU, demonstrating comparable performance gains with other vendors.
LinkedIn's Engineering blog on Liger Kernel is now live!!
https://t.co/Cd4OHwS68c
Since its initial release in August 2024, Liger-Kernel has grown rapidly across the community, accumulating 3,500+ stars and 350k+ downloads. We have integrated with mainstream training frameworks, including Axolotl, LLaMA-Factory, SFTTrainer, Hugging Face Trainer, SWIFT, and supported distributed training frameworks such as PyTorch FSDP and Microsoft DeepSpeed.
We especially thank our amazing partners Hugging Face, Lightning AI, Microsoft, Facebook, AMD, Intel Corporation, Embedded LLM, Hot Aisle Inc., Union ai, Anyscale and Modal for their continued support of the project.
Fun fact: The original plan was to publicly release in December, having open-sourced in August to gradually gain traction and feedback. However, the repo went viral on LinkedIn and X and is already loved by numerous LLM developers.
With Liger-Kernel, you can now fine-tune Qwen2-VL @Alibaba_Qwen on @modal_labs by one command with 10%+ throughput and 50% less memory, thanks to the contribution from @tyleraromero!
https://t.co/OI1H6eoazx
v0.4.1: Gemma 2 Support, CrossEntropy Patching FIx, and GroupNorm
https://t.co/01FBywrtEi
1. **Gemma 2 Support**: The long pending gemma 2 is finally supported thanks to Chun-Chih Tseng! He has implemented the nasty softcapping in fused linear cross entropy (https://t.co/itgktyOP15) and discovered the convergence issue which later fixed by @ByronHsu and Chun-Chih Tseng together. (https://t.co/YOtQMmUkhc)
2. **CrossEntropy Patching FIx**: If you use monkey patch for `CrossEntropy` (Not FLCE), it is actually not patched after transformers `4.46.1`. This is because `CrossEntropy` was replaced with `F.cross_entropy` in the model code. We fixed the issue in the PR (https://t.co/C4zoe1I6E8)
3. **GroupNorm Kernel**: Our new contributor Pramodith B implemented a GroupNorm kernel https://t.co/C4zoe1I6E8 with 2x Speedup.
Liger Kernel v0.4.0 has arrived! https://t.co/4dssL5jKGL
1. Full AMD Support: We have partnered with https://t.co/LNWFjDBTvV to adjust the Triton configuration to fully support AMD! With version 0.4.0, you can run multi-GPU training with 26% higher speed and 60% lower memory usage on AMD. See the full blogpost from https://t.co/CwtRwdtz2d. @EmbeddedLLM
2. Modal CI Migration: We have moved our entire GPU CI stack to Modal! Thanks to intelligent Docker layer caching and blazingly fast container startup time and scheduling, we have reduced the CI overhead by over 10x (from minutes to seconds). @modal_labs
3. LLaMA 3.2-Vision Model: We have added kernel support for the LLaMA 3.2-Vision model. You can easily use `liger_kernel.transformers.apply_liger_kernel_to_mllama` to patch the model.
4. HuggingFace Gradient Accumulation Fixes: We have fixed the notorious HuggingFace gradient accumulation issue (https://t.co/9SuZ5v1OUX) by carefully adjusting the cross entropy scalar. You can now safely use v0.4.0 with the latest HuggingFace gradient accumulation fixes (transformers>=4.46.2)!
5. JSD Kernel: We have added the JSD kernel for distillation, which also comes with a chunking version!
6. Technical Report: We have published a technical report on arXiv (https://t.co/vNxn1erP36) with abundant details.
@emnlpmeeting@nlee288 Thankfully, we now have more than 1,300 open checkpoints in the Hugging Face community🙌
And thanks to groundbreaking work by @liger_kernel team, you can use ORPO with up to 10 times more efficient memory usage🤯
https://t.co/XmCP20nBuS
Our tech report on Liger Kernel is now available on arXiv: https://t.co/1NsA14oXyC
We discuss the advantages of Triton, kernel fusion, kernel optimization (e.g. chunking, in-place, etc), the design philosophy of the interface, testing best practice, and benchmarks on a wide range of LLMs.
Note: the report only captures the status around v0.2.0. We will continue to update the report and include the collaborative effort from open source.
Join our online meetup on Oct. 16 for efficient LLM deployment and serving, co-hosted by SGLang, FlashInfer, and MLC LLM! 🥳 You are all welcome to join by filling out the Google form https://t.co/AWwnMqZo5p
It will cover topics such as low CPU overhead scheduling, DeepSeek MLA optimizations, kernel generation for high-performance LLM serving, universal LLM deployment, Low-latency serving, and fast grammar-based decoding.
🚀 Liger Kernel has surpassed **100,000+ downloads** after a month!
We're humbled by the many success stories shared by both the research community and enterprises. Our commitment remains strong: we'll continue to support more kernels and models while improving performance.
Based on community feedback, we've crafted our Q4 roadmap (https://t.co/iNaKlLiu8b). It includes exciting features like multimodal and JSD kernels, among others. We're actively seeking contributors to help shape the future of Liger Kernel. Join us to the next milestone!
Liger-Kernel: https://t.co/h4Hj9KTH7f
🚀🚀 v0.3.0 Release
1. Large Vision Language Model Support (Qwen-VL)
2. Patch Kernels on Model Instances
3. SWIFT Trainer Integration
4. KL Divergence Kernel and extended cross entropy
For the full release note, see https://t.co/BOTGsMJmG6
We are also hosting our 1st IRL event, "Scaling AI Infra - GPUs, Kernels, LLMs and More". We will discuss Liger-Kernel and invite speakers to talk about DeepSpeed, SGLang, and the TensorCore team. Please RSVP at https://t.co/v37bZGuuEL
🎉 We are excited to have surpassed 50,000 downloads (stable+nightly) in less than 3 weeks! We've added many new features and models. Expect something cool in the next release!
https://t.co/GwO3GzMT6S