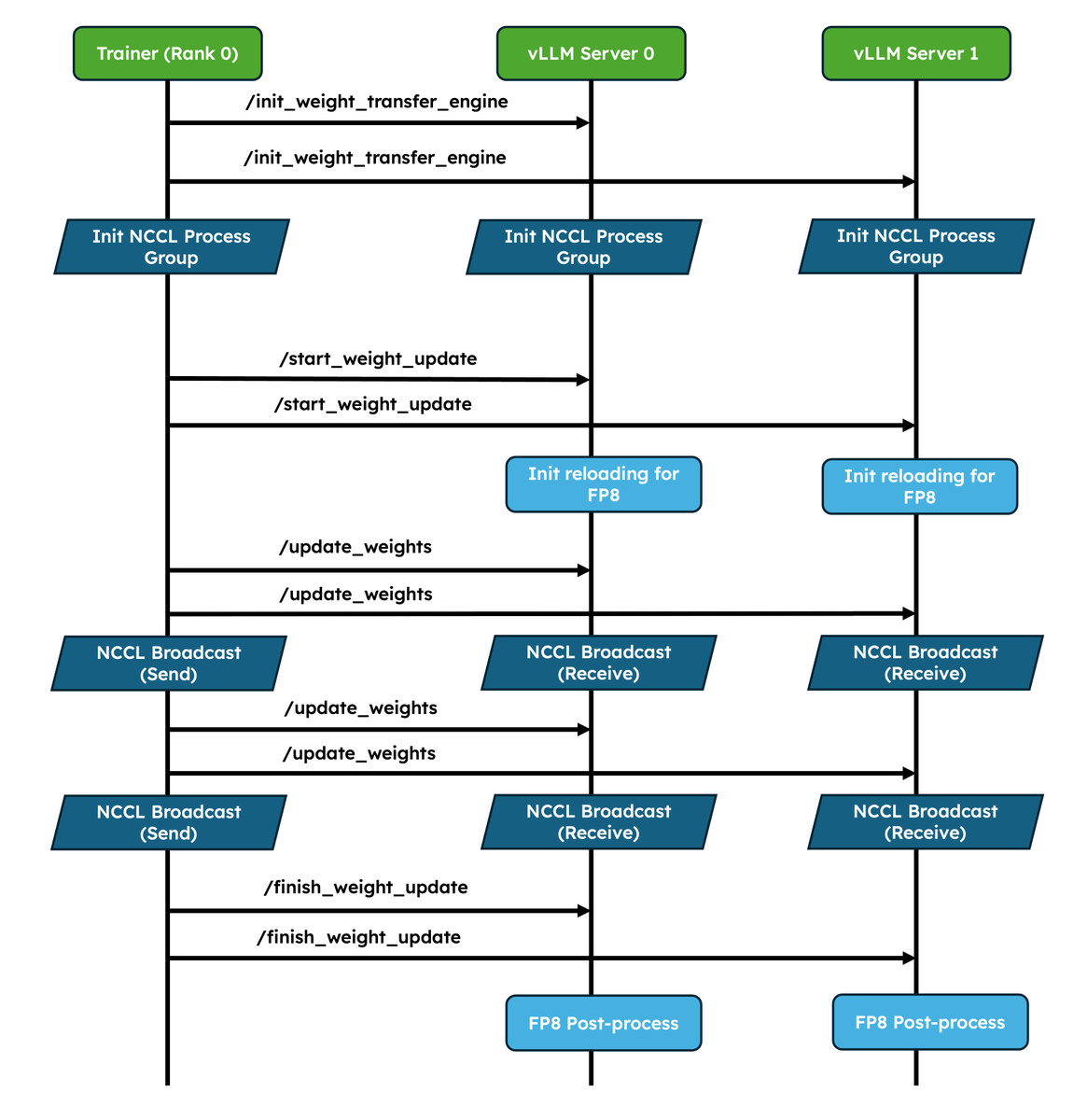
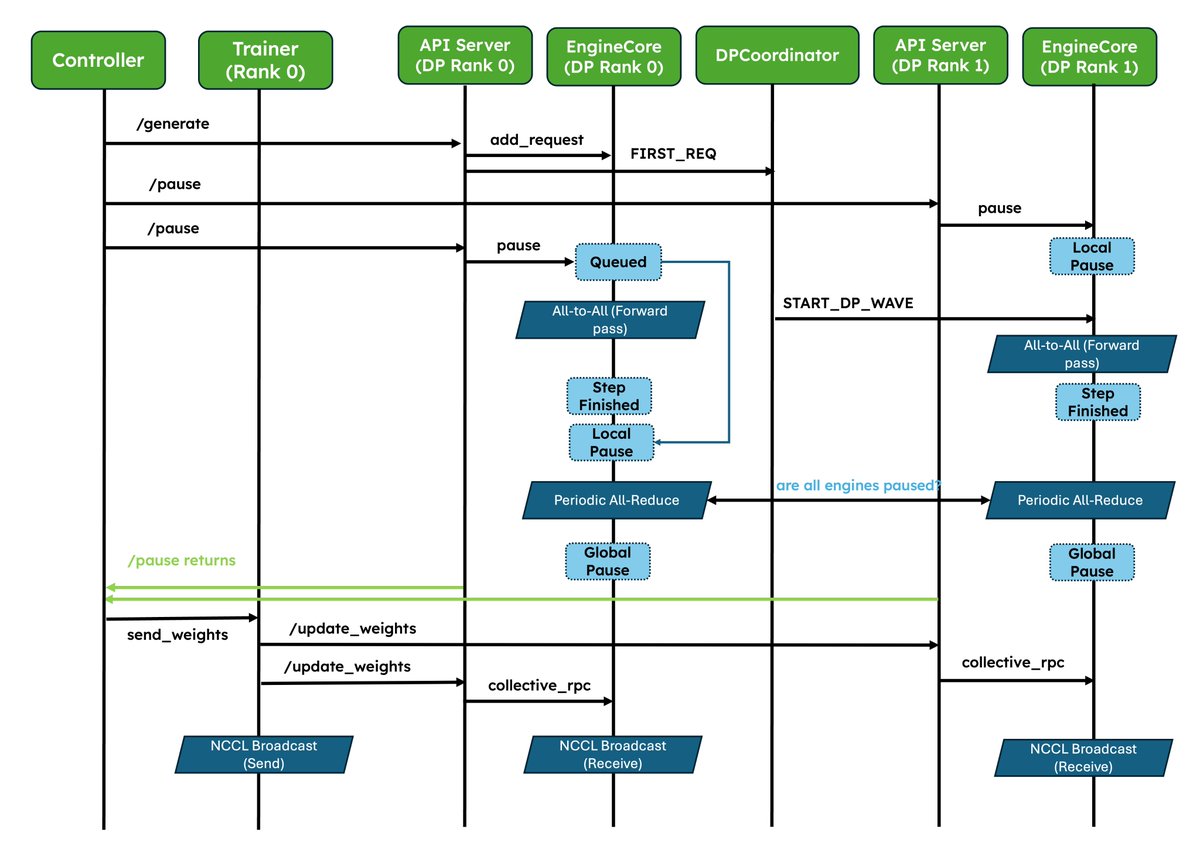
Amazing work! More and more RL frameworks are using vLLM as default. @vllm_project along with @anyscalecompute and @NovaSkyAI revamped weight syncing and improved wide-ep deployment for rollout!
We've shipped two major upgrades for RL✨!
1. Native weight syncing APIs: Standardizes weight transfer, provides optimized implementations for NCCL and CUDA IPC out of the box, and also lets frameworks easily bring their own.
2. Improved pause/resume for Async RL: Careful coordination between DP ranks so that engines don’t deadlock. Validated at scale in P/D, wide-EP setups!
In collaboration with @anyscalecompute, @NovaSkyAI, and @RedHat.
More and more RL frameworks are using vLLM as the default for inference, details in the blog 👇
https://t.co/LLmL8zJLtR
🦀 The Rust frontend is officially merged into vLLM!
As GPUs get faster, the frontend has become a real share of CPU time. The new Rust frontend is a drop-in alternative to the Python API server — same engine, same ZMQ boundary. Opt in with VLLM_USE_RUST_FRONTEND=1.
Early numbers: on a preprocess-heavy workload, ~837 req/s vs ~162 req/s for default Python — ~5x in a single process.
A few design choices we're excited about:
• Layered crates with clear boundaries
• Stream-native pipeline — non-streaming for free
• Builds on stable Rust
Huge thanks to @BugenZhao from @inferact for introducing the work at @PyTorch Meetup Singapore.
https://t.co/Tw8PoIjbH9
Great cohosting this luncheon with @a16z and Mirendil at MLSys 2026 yesterday! 🙌
We brought together top researchers and AI systems engineers for an afternoon of rich conversations on @vllm_project, the frontier of inference, and where AI systems are headed next.
Huge thanks to everyone who joined — the energy in the room was something else. This is exactly the kind of cross-pollination between labs, infra teams, and industry that pushes the whole stack forward.
More to come. 👀
#MLSys2026 #vLLM
A vLLM MoE deployment's DP/EP topology used to be locked in at launch — scaling or swapping config meant a full restart, in-flight traffic dropped. Elastic Expert Parallelism changes that. One API call resizes a live deployment:
curl -X POST localhost:8000/scale_elastic_ep \
-d '{"new_data_parallel_size": 16}'
Under the hood: standby comm groups span the target topology, EPLB redistributes experts across the new EP group, and weights are transferred directly between GPUs over NVIDIA NVLink/RDMA. The same runtime reconfiguration path is what fault-tolerant serving needs: evict failed ranks, redistribute their experts, bring replacements back, no restart.
Thanks to @NVIDIAAI, Sky Computing, @anyscalecompute, @RedHat_AI, and the community.
📖 https://t.co/bHmyFNZPEg
🎉 Day-0 vLLM support for Command A+! Congrats to @cohere on their most powerful open-source model yet.
🧠 218B MoE / 25B active, Apache 2.0
🌍 Multimodal + 48 languages
⚡ Runs on as little as 2× H100s @ W4A4
Serve it now in vLLM! 🚀
📖 https://t.co/NKFHejTNtl
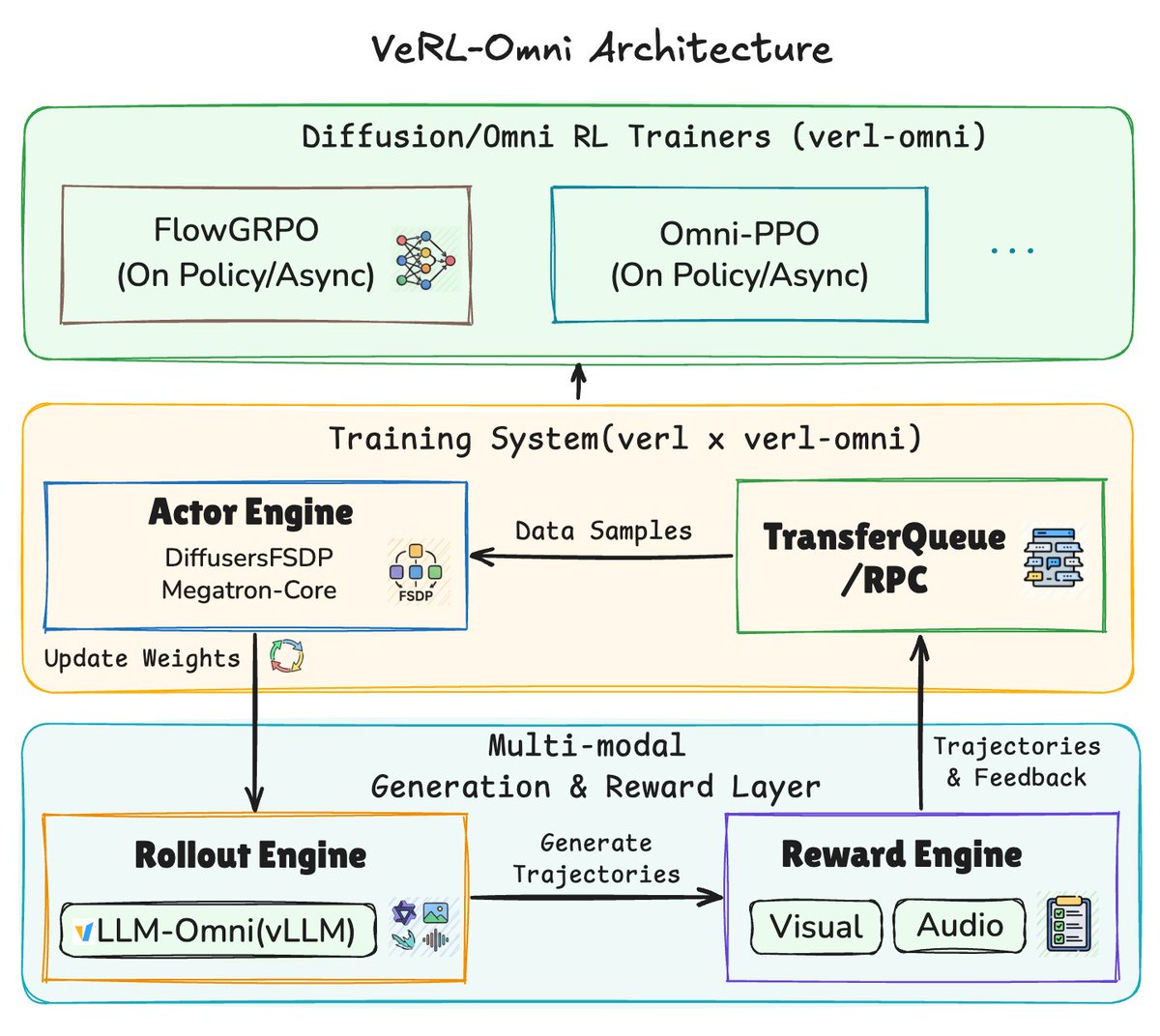
🎉 Congrats to the VeRL-Omni team on the pre-release of a general RL post-training framework for multimodal generative models. Built on verl + vllm-omni.
vLLM-Omni handles the multimodal rollout with step-wise continuous batching and embedding caching; vLLM serves the VLM-as-judge / OCR reward model, overlapped with rollout and training. In the Qwen-Image OCR demo, moving the reward to its own GPU cuts per-step wall-clock by ~14%.
Released: Qwen-Image with FlowGRPO / MixGRPO / GRPO-Guard. BAGEL and Qwen3-Omni-Thinker PR-ready.
Excited to push multimodal generative RL forward together with VeRL-Omni and the broader community. 🙌
📖 https://t.co/D2TpU8EU9J
🔗 https://t.co/uwmO3EWwcS
$AMD is unstoppable now.
@AIatAMD ROCm flywheel is spinning hard: persistent MI355X access for @vllm_project@EmbeddedLLM is proud to help power that loop.
AI inference is infrastructure.
And the next era of AI infra won’t be won by default distribution. It’ll be won by kernels, compilers, runtimes, and relentless execution.
We’re here for that fight. 🚀
The shock came when on Day 0 DeepSeekv4 launch, since the community vLLM/SGLang maintainers only had access to NVIDIA GPUs, they were only able to add Day 0 NVIDIA GPU support. Since then, AMD has finally priotitzed with actions and just not words by contributing an 2.5million dollar 9 node Mi355X cluster with 8x400G Pollara NICs towards open source @vllm_project maintainers including (@EmbeddedLLM maintainers, @simon_mo_ and others) & an 1.1 million dollar dev 4 node+ MI355 dev cluster. 2\4
Great read from the @RedHat_AI team — a comprehensive investigation into TurboQuant in vLLM, with FP8 and BF16 as reference baselines: 4 models (30B to 200B+, decoder-only and MoE) and 5 benchmarks covering long-context retrieval and reasoning, all on the stable vLLM 0.20.2 release.
If you're considering TurboQuant for your workload, this is the data to start from.
📝 https://t.co/YkQIsyuDUN
This is growth-hacking dressed up in open-source language, @radixark please stop doing it immediately.
Paying people in platform credits to star a GitHub repo and repost a marketing tweet isn't "fueling the community" — it's laundering paid promotion through the trust signals open source depends on. Stars are supposed to mean someone found a project useful. Attach a $200 bounty and the number means nothing. GitHub's own policies prohibit this for exactly that reason.
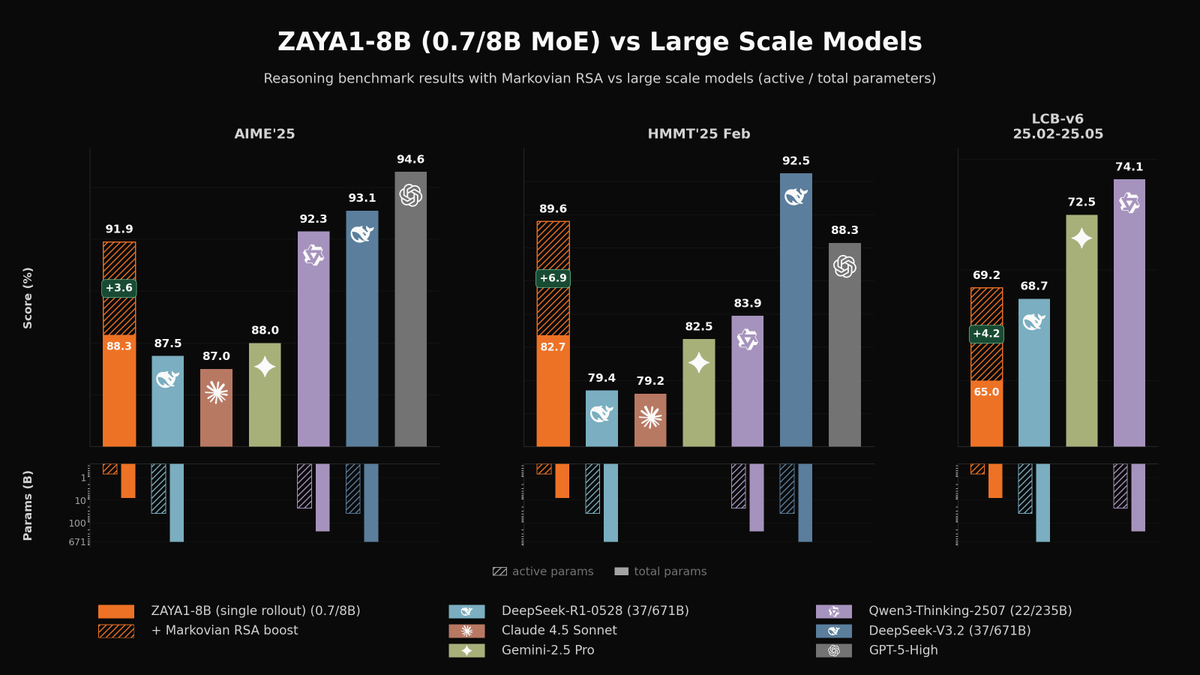
Today we're releasing ZAYA1-8B, a reasoning MoE trained on @AMD and optimized for intelligence density.
With <1B active params, it outperforms open-weight models many times its size on math and reasoning, closing in on DeepSeek-V3.2 and GPT-5-High with test-time compute. 🧵
🚀 New on the @vllm_project blog: Serving Agentic Workloads at Scale with vLLM x Mooncake.
Agentic traces grow to 80K+ tokens with 94%+ reusable prefixes, but local KV caches evict them and cross-instance routing misses them.
By integrating Mooncake Store as a distributed KV cache pool, vLLM gets:
🚀 3.8x higher throughput
⚡ 46x lower P50 TTFT
⏱️ 8.6x lower E2E latency
📈 Cache hit rate 1.7% -> 92.2%
🌐 Scales near-linearly to 60 GB200 GPUs at >95% hit rate
🔥 Powered by a deep collaboration between @Inferact and @KT_Project_AI
📖 Read more: https://t.co/XIRtQ9pYVQ
🧵👇
🚀 Day-0 MTP support for Gemma4 now available at vLLM with ready-to-use docker image!
⚡️Enjoy up to 3x faster decoding performance to supercharge your development with zero quality degradation!
Check out the full vLLM recipes for Gemma 4 model series👇
https://t.co/IrCaaa6SIo
Introducing XGrammar-2: structured generation for complex agent harnesses.
Strict tool-calling formats. Built-in DeepSeek-V4 and Qwen-3.6 support. Up to 80x speedup over XGrammar. Ready-to-use integrations with vLLM, SGLang, TensorRT-LLM, and more! ⚡
From Claude Code to OpenClaw, agents are defining more complex harnesses. XGrammar-2 ensures LLMs always interact with them in the right way.
Built in collaboration with DeepSeek, Databricks, and leading frontier AI labs to bring XGrammar-2 into latest models and products.
🧩 Structural Tag: one unified abstraction to describe any format your agent needs
🚀 Scales to 500+ strictly typed tools for complex agent harnesses
🌐 Native APIs in Python, C++, Rust, and JS, running everywhere from cloud to edge
🛠️ Integrated with vLLM, SGLang, TensorRT-LLM, and more
Excited to see what agent builders create with it!
Blog: https://t.co/N0Tbl588BH
GitHub: https://t.co/lo4yScuI2f
@inferact builds on top of vLLM, improves vLLM, and ships optimizations back to vLLM🤩
These optimizations are built on the foundation of the vLLM community's contributions—we added some contributions on top, and more to come💪🏻