Ya se que el imbécil q controla esto no quiere q nadie vea mis tuits y hace lo posible para que ni mis seguidores se enteren, pero yo sé q a muchos les gustan los trenes y las estaciones abandonadas, y voy a seguir poniendo fotos porque aunque sean dos personas, alguien las verá.
Ahora puedes darle memoria infinita a Claude Code, Codex y Hermes.
100% gratis.
Agentmemory ya es tendencia en GitHub con +4.000 estrellas.
La herramienta:
→ guarda todo lo que Claude/Codex hace durante tus sesiones de programación
→ lo comprime con IA
→ recupera automáticamente el contexto relevante en futuras sesiones
La diferencia es absurda:
CLAUDE.md
→ 22.000+ tokens para 240 observaciones
Agentmemory
→ solo 1.900 tokens para las mismas observaciones
92% menos contexto consumido.
Y además:
→ Hasta 95% menos tokens por sesión
→ 200x más llamadas a herramientas antes de llegar al límite de contexto
→ 100% open source
A partir de unas 1.000 observaciones, gran parte de la memoria integrada de Claude deja de ser accesible.
Agentmemory mantiene todo indexado y searchable.
Esto cambia por completo cómo se usa Claude Code, Codex y Hermes, entre otras.
Ya no reinicias el contexto.
Tu proyecto simplemente lo recuerda.
Enlace abajo 👇
@OpenAIDevs Sales director by day, hobby coder by night. Building an AI copilot inside our industrial CRM: semantic engine, default-deny, 300+ tests. Goal: sales reps ask by voice ‘how’s this client doing’ and get real data back, by name. Flask, Python & too many late nights
🚨 BREAKING: Someone just built the exact tool Andrej Karpathy said someone should build.
48 hours after Karpathy posted his LLM Knowledge Bases workflow, this showed up on GitHub.
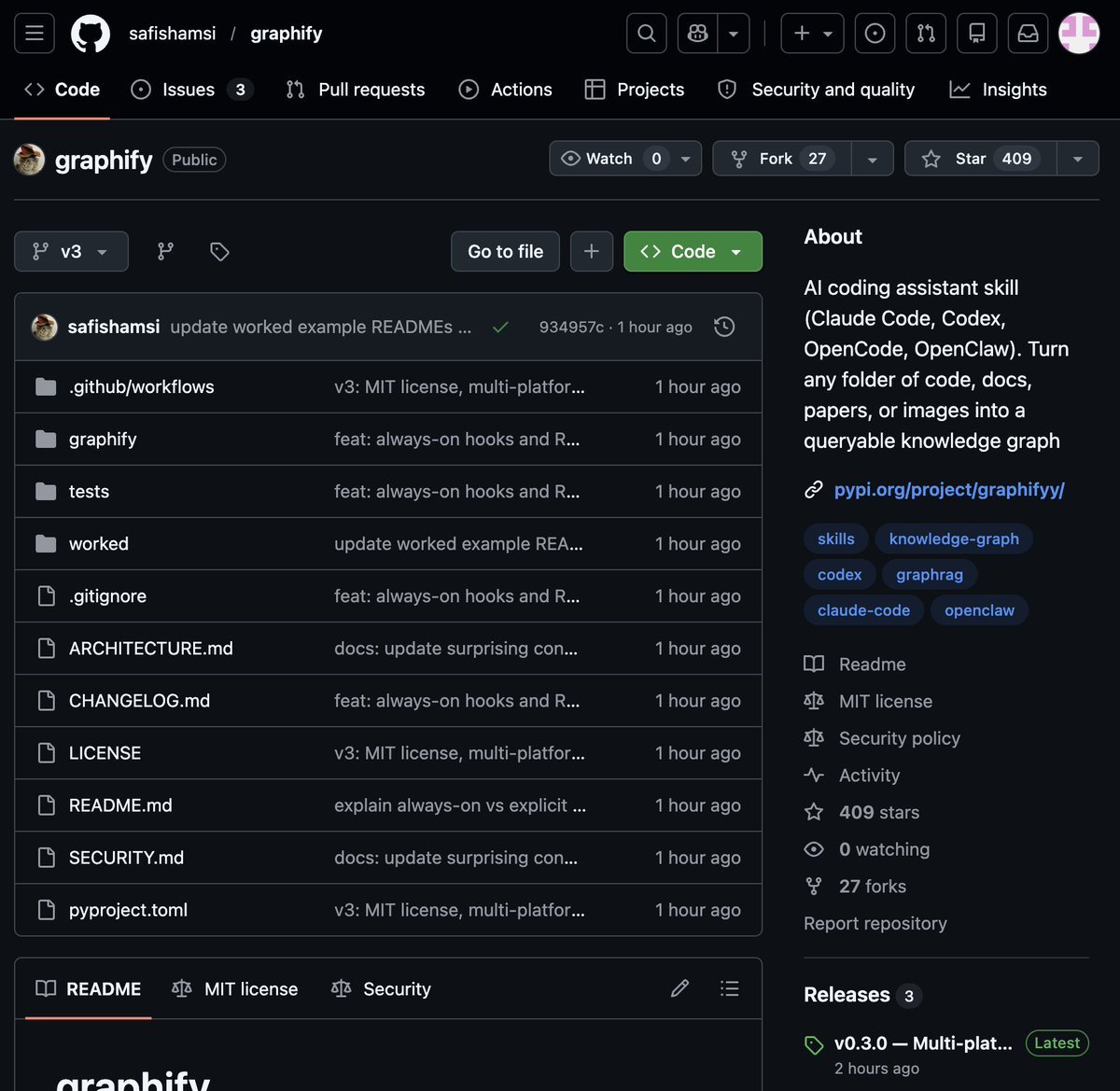
It's called Graphify. One command. Any folder. Full knowledge graph.
Point it at any folder. Run /graphify inside Claude Code. Walk away.
Here is what comes out the other side:
-> A navigable knowledge graph of everything in that folder
-> An Obsidian vault with backlinked articles
-> A wiki that starts at index. md and maps every concept cluster
-> Plain English Q&A over your entire codebase or research folder
You can ask it things like:
"What calls this function?"
"What connects these two concepts?"
"What are the most important nodes in this project?"
No vector database. No setup. No config files.
The token efficiency number is what got me:
71.5x fewer tokens per query compared to reading raw files.
That is not a small improvement. That is a completely different paradigm for how AI agents reason over large codebases.
What it supports:
-> Code in 13 programming languages
-> PDFs
-> Images via Claude Vision
-> Markdown files
Install in one line:
pip install graphify && graphify install
Then type /graphify in Claude Code and point it at anything.
Karpathy asked. Someone delivered in 48 hours.
That is the pace of 2026.
Open Source. Free.
I have built a spreadsheet. It has 847 rows. Each row is a community bank in the United States with a market cap below $200 million, a price-to-tangible-book ratio under 0.85, a non-performing loan ratio below 0.4%, and a CEO who has been in the role for at least twelve years. I update it every Sunday from 6 AM to 11 AM while my family attends church without me. I have visited the headquarters of nineteen of these banks in person. I have eaten a complimentary lobby cookie at each one. The cookies are how you can tell. A bank with a good cookie is a bank that respects its depositors. A bank with a stale cookie is a bank that will be acquired within 36 months at a 40% premium. I am never wrong about the cookies. The cookies have never lied to me. The cookies are the only thing left that tells the truth.