LM Studio with Multi Token Prediction (MTP) is now in beta.
1. Update to 0.4.14+3 in-app
2. Make sure your llama.cpp engine is 2.15.0
3. Turn on MTP when loading a model
Use a model that supports it, like Qwen3.6-35B-A3B-MTP-GGUF or Qwen3.6-27B-MTP-GGUF
LM Studio with Multi Token Prediction (MTP) is now in beta.
1. Update to 0.4.14+3 in-app
2. Make sure your llama.cpp engine is 2.15.0
3. Turn on MTP when loading a model
Use a model that supports it, like Qwen3.6-35B-A3B-MTP-GGUF or Qwen3.6-27B-MTP-GGUF
Batching for vision models is now available in Beta with our latest MLX engine update 👾
The updated engine also brings major improvements to caching for faster inference overall.
Turn on Developer Mode, choose the beta runtime channel, and select LM Studio MLX v1.8.1.
Locally AI is joining LM Studio!
We are beyond excited to welcome @adrgrondin and @LocallyAIApp to the LM family.
Together we are doubling down on native AI experiences across your devices, anywhere you go.
Read our announcement https://t.co/Yzcnr8EEP0
Our servers are overloaded at the moment, and we are working to fix this! Very sorry for the inconvenience.
Model search, download, LM Link, and website are impacted. Stay tuned for updates.
We worked with @NVIDIAAI to bring up support for DGX Station GB300 at launch!
✨ 748GB of coherent memory
👾 Install llmster and enable LM Link
🛰️ Load models and use them from other devices
Learn how to set it up: https://t.co/TU6Lf8Lr2u
🚀⚡️🔥
LM Studio 0.4.7 Beta (build 3) is now available.
This build contains many bug fixes:
🐛🔨 LaTeX ($ signs) rendering, extraneous <think> tags in coding agents, fixes for tool calling parsing, and more!
Update in-app or from https://t.co/xtndufzi6B
Nemotron 3 Super by @nvidia is now live in LM Studio!
🦾 Open-weight 120B MoE, 12B active params
📜 Supports up to 1M tokens context window
Requires about ~83GB to run locally 🚀
https://t.co/5v6WKnnUra
One of the coolest uses of @lmstudio and @AIatAMD is using LM Link to have a Framework Desktop be a remote inference server for a laptop, including something little like Framework Laptop 12. It feels native on the laptop, but gets the desktop’s performance.
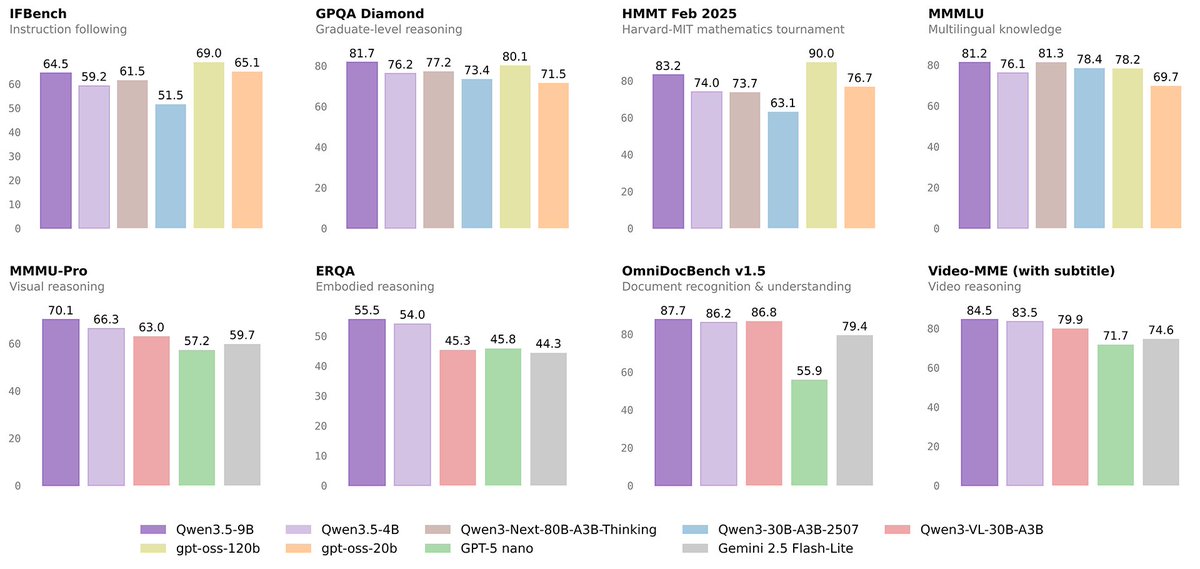
🚀 Introducing the Qwen 3.5 Small Model Series
Qwen3.5-0.8B · Qwen3.5-2B · Qwen3.5-4B · Qwen3.5-9B
✨ More intelligence, less compute.
These small models are built on the same Qwen3.5 foundation — native multimodal, improved architecture, scaled RL:
• 0.8B / 2B → tiny, fast, great for edge device
• 4B → a surprisingly strong multimodal base for lightweight agents
• 9B → compact, but already closing the gap with much larger models
And yes — we’re also releasing the Base models as well.
We hope this better supports research, experimentation, and real-world industrial innovation.
Hugging Face: https://t.co/wFMdX5pDjU
ModelScope: https://t.co/9NGXcIdCWI
Introducing LM Link ✨ Connect to remote instances of LM Studio, securely.
🔐 End-to-end encrypted
📡 Load models locally, use them on the go
🖥️ Use local devices, LLM rigs, or cloud VMs
Launching in partnership with @Tailscale
Try it now: https://t.co/Vl2vr6HlF5
Introducing Parallel Requests for MLX!
Multiple requests to the same model can now be processed simultaneously ✨🚄⚡️
Works both in the API and in Split View chats.
See it in action 👇🕺