Agentic knowledge work can take frontier models over 20 minutes per task, as measured in AA-Briefcase, our new benchmark
Last week we released AA-Briefcase, our proprietary agentic knowledge work benchmark testing models on long horizon tasks built by industry experts. AA-Briefcase requires models to build deliverables such as financial models, board presentations, and design mock-ups in the context of realistic multi week projects.
One of the key metrics we measure in AA-Briefcase is average time per task. This is calculated using evaluation token usage, representative model output speeds, and tool execution time recorded during evaluation.
Key time per task takeaways from AA-Briefcase:
➤ Claude Opus 4.8 is the highest-scoring available model, but it is also one of the slowest, taking ~23 minutes per task on average
➤ Several GPT-5.5 reasoning variants lie along the Pareto frontier of AA-Briefcase Elo vs. Time per Task, including medium, high, and xhigh. GPT-5.5 (xhigh) in particular stands out as one of the most efficient top-performing models, using around half the time per task of Opus 4.8 (11 minutes) while ranking top 5 on the overall AA-Briefcase Elo
➤ GLM-5.2 also sits on the Pareto frontier, scoring 1261, ahead of GPT-5.5 (xhigh, 1159) but also taking more time per task (16.3 minutes). It is also the top-performing open weights model on AA-Briefcase, with MiniMax-M3 the next best at 1113
➤ If Claude Fable 5 were still available, it would likely take around 28.5 minutes per task: while it was live, we measured ~91 output tokens per second, ~3.1 minutes of tool execution time per task, and ~139,000 output tokens per task
➤ Time spent on tool calls and execution accounts for only ~12% of the total time, with the remaining amount explained by output verbosity, turn usage, and inference speed
Seed 2.1 Pro Preview ranks #8 in Code Arena: Frontend, scoring 1539, on par with Opus 4.6. It performs strongly on React apps and lands in the top 10 for five of seven subcategories. In those areas, only a handful of frontier labs rank above it: @Zai_Org's GLM-5.2 and @AnthropicAI's Claude models.
Highlights:
- #7 on the React leaderboard, #14 on HTML
- #6 Brand & Marketing
- #9 Content Creation Tools, Data & Analytics
=#10 Reference Based Design, Consumer Product
This is an early access preview of the model. It will be publicly available in a few weeks.
MiniMax-M3 is now the best open-source model on the AAI
It's ahead of Kimi-K2.6, GLM-5.1 and DeepSeek-V4-Pro
On the Coding Index it's slightly behind V4-Pro and K2.6, but it's beating them on the Agentic Index
CritPt scores are a bit worrisome.
But the biggest highlight here is probably its reasoning efficiency compared to other open models.
(but still miles behind closed models)
@AlvarezMaynez@SEP_mx Lo dicen los padres que tienen a sus hijos en escuelas climatizadas de concreto con todas las amenidades, llevenlos a las escuelas sin ventiladores, y techos de lámina a 35-40°C
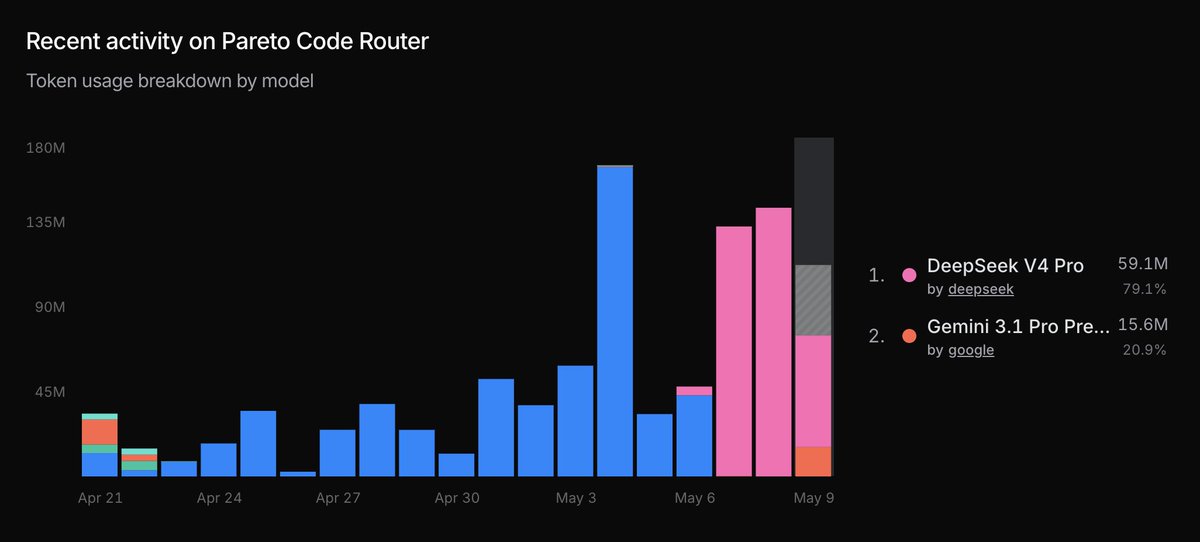
Introducing Pareto Code: a new, free, experimental coding router
Set `min_coding_score` in your request and route to the cheapest code-capable model that clears your bar, ranked by @ArtificialAnlys.
See the Pareto frontier shifting in real time👇
Spor ve hava durumu sunucusu Em Rose, canlı yayın öncesi hazırlık anlarıyla sosyal medyada gündem oldu.
▪️Siyah dantelli iddialı sahne kıyafetiyle dikkat çeken Rose’un, yayına saniyeler kala ekip tarafından yapılan son dokunuşları kameralara yansıdı.
▪️Profesyonelliği ve rahat tavırlarıyla beğeni toplayan sunucu, kısa sürede sosyal medyada en çok konuşulan isimlerden biri haline geldi.
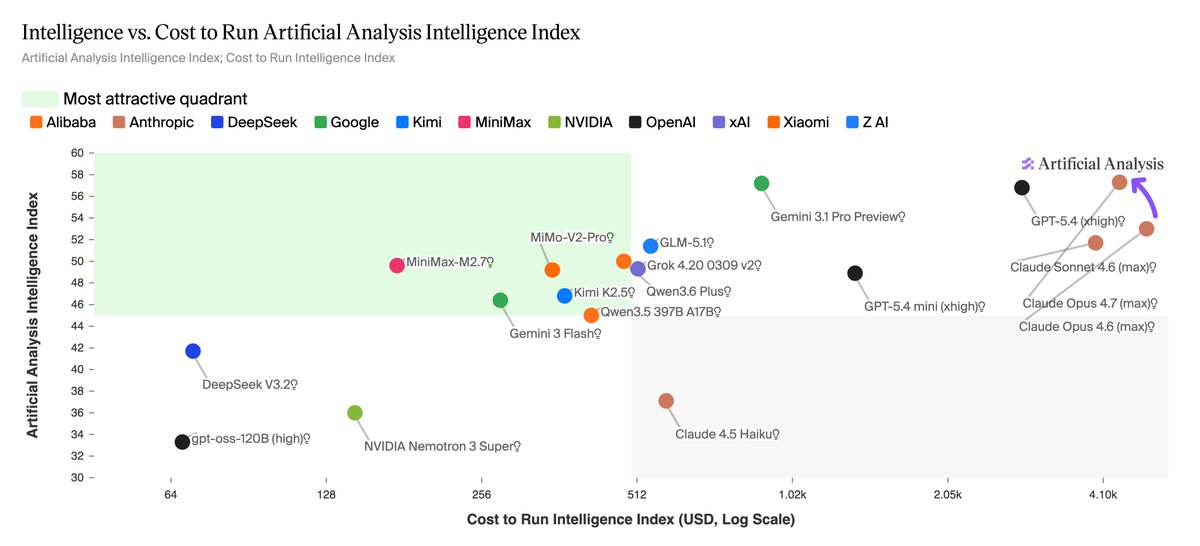
Opus 4.7 (Adaptive Reasoning, Max Effort) cost ~$4,406 to run the Artificial Analysis Intelligence Index, ~11% less than Opus 4.6 (Adaptive Reasoning, Max Effort, ~$4,970) despite scoring 4 points higher. This is driven by lower output token usage, even accounting for Opus 4.7's new tokenizer
Vosotros sois muy jóvenes y no lo recordaréis, pero hace aproximadamente 2 años y poco, Israel le disparó directamente a civiles que iban a buscar comida y medicinas a los camiones que conseguían atravesar el BLOQUEO de los colonos en las carreteras.
Así es el sionismo.
#ULTIMAHORA
🚨 CONFIRMACIÓN BOMBA: Medios Estadounidenses afirman que el supuesta ataque de Irán a Baréin fue con un Misil Tomahawk de Estados Unidos
Se confirma que EU e Israel están haciendo ataques de falsa bandera para involucrar a todos los países arabes ya que solos no pueden.
Por favor compartan este video antes de que la Casa Blanca lo mande bajar de las redes...
🚨Mátame camión 🤦🏻♂️
⭕️ Nivel medio de algunos jóvenes en EEUU:
➖“¿Qué es un ayatolá?”
➖“¿Venezuela no está en España?”
➖“No sé dónde está… pero la borraría del mapa.”
Y esta gente vota, decide guerras y lidera el mundo.
AI models have now reached Mensa-level IQ and beyond, making them smarter than most humans! 🧠
A new chart by Tracking AI ranks the top large language models on a bell curve spanning 50 to 150.
Lower scores in the 60-80 range include Qwen 3.5, Mistral Medium 3.1, Bing Copilot, and OpenAI GPT 5.3 variants. The mid-range around 90-110 features Claude 4.6 Opus, Perplexity, Gemini 3.1 previews, and Llama 4 Maverick.
Above 120 sit Kimi K2.5, DeepSeek models, and Grok 4 Vision and Thinking from xAI. The highest marks near 145 go to OpenAI’s latest GPT 5.4 Pro Vision and ChatGPT 5 PRO Vision.
AI is advancing fast!