Transformers are data‑hungry in sequential tasks because they lack the right inductive bias.
It’s well known that for many sequential problems (from adding numbers to step‑by‑step agentic execution and multi‑hop reasoning), transformers fail to generalize to longer sequences than they were trained on. “Train short, test long” often fails.
The usual workaround is to "just train on whatever length you’ll need at test time".
---------
📉 But we show the consequence of this is data inefficiency:
• Transformers can learn tasks for a single fixed sequence length fairly efficiently, but learning across multiple lengths requires much more data.
• More importantly, transformers tend not to share mechanisms across tasks of different lengths; instead, they often learn isolated, length‑specific solutions.
---------
🧪 A simple way to test this:
Consider modular addition (with and without CoT). Train a model to add 2, 3, …, L numbers at once and measure the data needed. Then train separate models for each length (2, 3, …, L) and sum their data requirements.
💡The intuition:
If a model truly shares mechanisms across lengths, learning a distribution of lengths should require far fewer samples than learning each length separately.
This comes from amortizing the learning cost: data for length n also helps the model learn length n+k.
---------
📊 Results:
Sharing Factor κ = (sum of samples to learn each length separately) ÷ (samples to learn all lengths jointly)
- κ > 1: mechanism sharing and amortized learning.
- κ ≈ 1: learning length-specific solutions in isolation.
- κ < 1: destructive interference; length-specific solutions compete for model capacity.
Transformers showed low sharing factors, and even destructive interference with CoT.
---------
✨ Implications:
This suggests that end-to-end learning in applied agentic settings, like robotics or GUI control, could be even more challenging.
If data requirements grow unfavorably with sequence length, that might also help explain the persistent issues we see at large context lengths (e.g., context rot).
Standard attention mechanism appears inefficient for step-by-step tasks, and we may ultimately be better off with recurrent agents.
1/
We know Transformers fail at length extrapolation. But new research shows a deeper flaw: they fail at IN-DISTRIBUTION state tracking. They don't learn algorithmic rules, they just memorize isolated circuits per length. 🧵
Looking at the thread. The common frame to look at the more general phenomenon involves an eigenproblem of the form Oƒ = λƒ, where the operator O encodes either: a symmetry (translations, rotations, general group transformations), or a
a statistic (e.g. covariance, correlation),
@y0b1byte And heartbreaking to see the founder stepping down due to mistreatment (from users and kernel maintainers). So much value lost 😥
https://t.co/0rEXLUBAkd
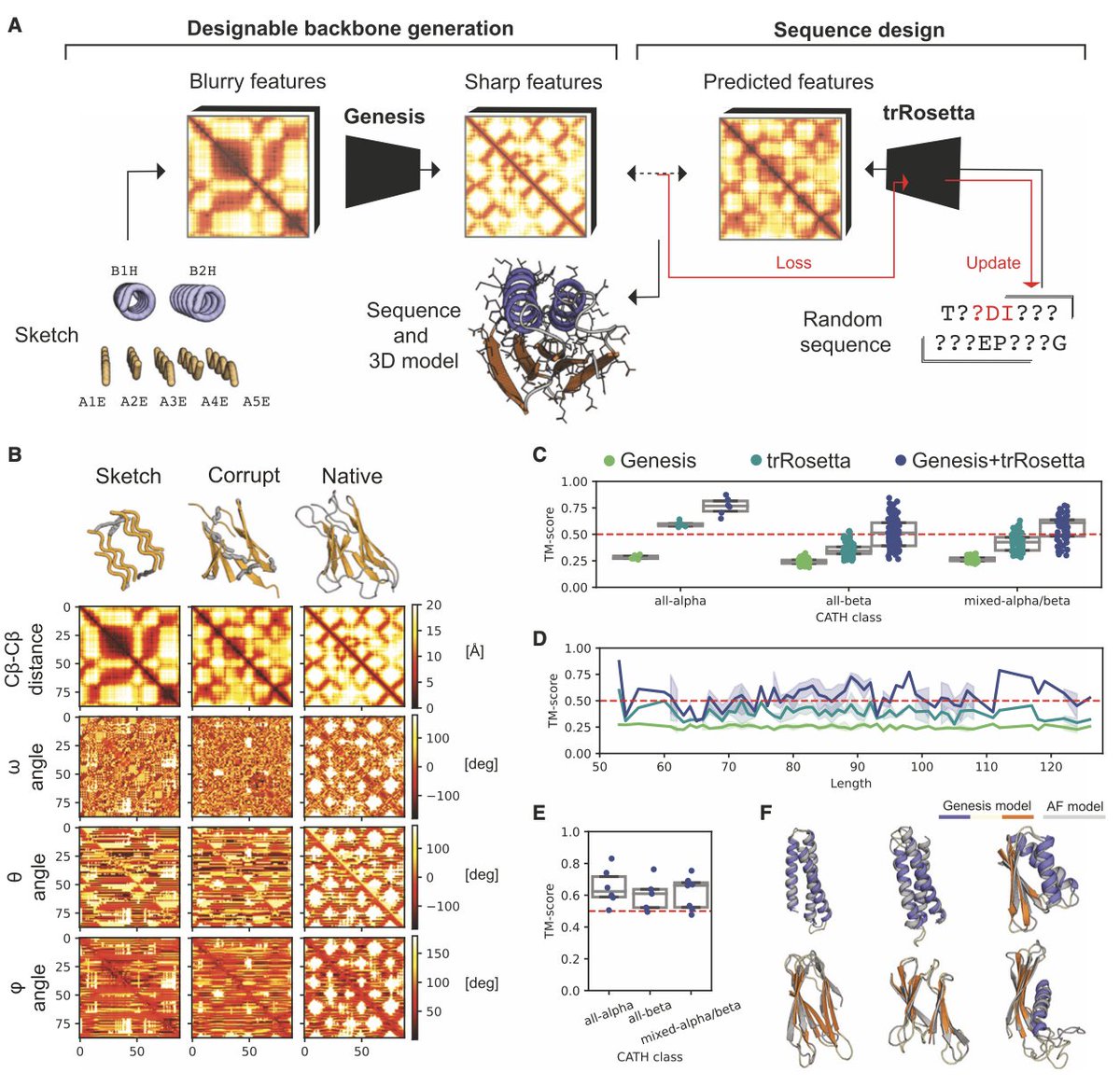
Exploring “dark-matter” protein folds using deep learning @CellSystemsCP
• Introducing Genesis VAE, a convolutional variational autoencoder that transforms low-resolution protein fold sketches into designable, stable 3D models.
• Genesis VAE enables rapid exploration of “dark-matter” protein folds, creating novel protein architectures that have never been observed in nature.
• Coupled with trRosetta, Genesis can design protein sequences for both known and novel folds, validated through experimental protease resistance assays.
• One major innovation is Genesis’ ability to learn structural patterns from low-resolution sketches, refining them into native-like protein backbones.
• The framework successfully designed five native folds and three novel “dark-matter” folds, demonstrating its capacity to generalize beyond natural protein spaces.
• High-throughput experimental validation showed several of the designed proteins were stable, with folding behavior on par with natural proteins.
• Genesis opens the door for the de novo design of proteins with entirely new functions, breaking through current limitations in protein design.
@zanderharteveld@mmbronstein@befcorreia@JoshSouthern13@CasperGoverde@m_deff@loukasa_tweet@trekkinglemon
💻Code: https://t.co/sJvvJofqCJ
📜Paper: https://t.co/rKpm4q312Q