Sam Altman, CEO of OpenAI, on what AI does to science:
"If we can start doing a decade of science in a year, the compounding effect of what we'll discover will just be extremely great."
Discovery is about to compound yearly instead of decade by decade.
The advantage won't go to whoever has the best degree. It goes to whoever learns to direct a model that proposes its own experiments.
Before the week ends, let's acknowledge one of the most INSANE week ever for open AI, with 25+ notable open-weight drops across every modality:
🧠 LLMs
→ NVIDIA Nemotron 3 Ultra: 550B hybrid Mamba-MoE, only 55B active, 1M context, MMLU 89.1. NVFP4 variant claims ~5x throughput on Blackwell. First openly-weighted 550B hybrid Mamba-Transformer, closing the gap with frontier closed models.
→ Google Gemma 4 12B: fully open dense any-to-any (text/image/audio/video), 256k context, encoder-free, 140+ languages, AIME 2026 at 77.5. Shipped with a 23-checkpoint QAT wave (mobile ONNX + MLX). Most deployable model of the week.
→ StepFun Step-3.7-Flash: 198B sparse MoE VLM, ~11B active, SWE-Bench PRO 56.3. Apache 2.0.
→ Liquid AI LFM2.5-8B-A1B: edge MoE, just 1.5B active, 128k ctx, MATH500 88.8, MLX-ready. Best on-device option this week.
→ JetBrains Mellum2-12B-A2.5B-Thinking: their first open MoE, near-Qwen3-14B coding at 2.5B active. Apache 2.0.
🎨 Image gen (the surprise of the week)
→ Ideogram 4: their FIRST-EVER open weights. 9.3B flow-matching DiT trained from scratch. #2 overall behind GPT Image 2, top open-weight model on Design Arena + LMArena. Strongest open checkpoint for text-rich images, full stop. It has taste. Still can't believe this is open weights.
🔊 Audio & Speech (a breakout week for open TTS, 4 labs shipped)
→ Boson Higgs Audio v3 4B: 102 languages, 21 emotions, singing/whispering/shouting, sub-second TTFA.
→ RedNote dots.tts: the only fully continuous (no codec) open TTS pipeline, Apache 2.0.
→ Google Magenta RealTime 2: real-time music gen, <200ms latency, text+audio+MIDI. multimodalart ported it to PyTorch within hours with live ZeroGPU demos.
→ NVIDIA Nemotron-3.5 ASR: 600M streaming, 17x more concurrent streams vs Parakeet RNNT 1.1B.
👁️ Vision & VLMs
→ PaddleOCR-VL-1.6: SOTA document parsing at 1B params, Apache 2.0.
→ Baidu NAVA: 6.3B joint audio-video gen, best-in-class A/V sync, Apache 2.0.
🎬 Video, 3D & World Models
→ NVIDIA Cosmos3-Super: 64B omnimodal world model coupling action trajectories with video+audio gen, for Physical AI.
→ JD JoyAI-Echo: up to 5-min multi-shot text-to-video on LTX-2.3.
→ ByteDance Bernini-R + VAST TripoSplat (single-image-to-3D Gaussian splats, MIT).
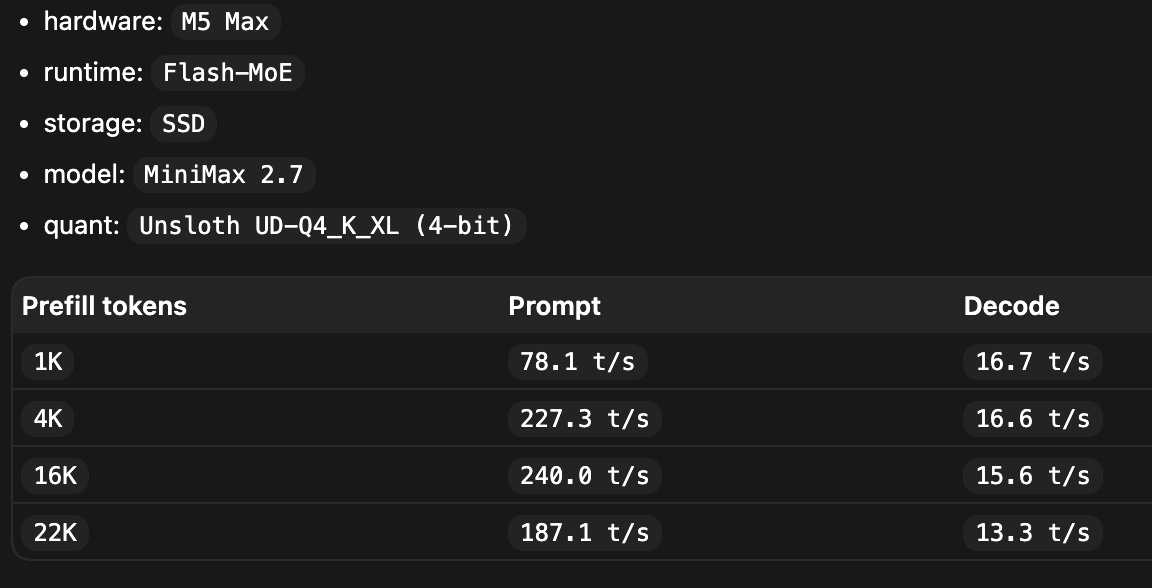
WIP: Merged: prefill dedup for Flash-MoE. MiniMax only for now while I validate the other models
Layer-major prefill runs one layer at a time, groups
repeated expert picks across the prefill chunk, loads each unique expert from SSD once, and reuses it for every token that picked it , instead of reloading per token.
Bigger prefill chunk → more reuse → cheaper prefill.
Prefill is now compute-bound, not I/O-bound.
That should help both GPU and ANE prefill at large batch sizes. Can we speedup regular MoE MLX prefill 🤔
https://t.co/JkP1cuOSdp
If you have a Thunderbolt or USB4 eGPU and a Mac, today is the day you've been waiting for! Apple finally approved our driver for both AMD and NVIDIA. It's so easy to install now a Qwen could do it, then it can run that Qwen...
AI has automated software engineering. What you would expect is that there would be no more work left to do for software. But instead what has happened is that the leverage of doing software has increased so much, that doing anything else is a waste of time