New paper: "Agentic Forecasting using Sequential Bayesian Updating of Linguistic Beliefs".
Our system (BLF) matches human superforecasters on ForecastBench, and beats all the top methods (GPT-5, Cassi, Grok 4.20, and Foresight-32B).
🧵
Why hallucinations happen ?
This survey says AI hallucinations follow patterns and shows where those patterns come from.
The paper builds something called the MOWI framework, which means Model, Observer, World, and Input.
Each of these 4 levels looks at hallucination from a different angle.
At the Model level, it checks if the AI’s internal math and learned patterns match real data.
If they don’t, it produces wrong or made-up outputs.
At the Observer level, it looks at how humans see the result.
Even if the AI’s answer makes sense mathematically, it might still sound wrong or weird to people because it doesn’t match their understanding.
At the World level, it considers what the AI can or cannot know.
Sometimes, missing or uncertain facts in the real world cause hallucinations, especially in topics that change over time or lack enough data.
At the Input level, it looks at the quality of the question or prompt.
If the input is unclear, misleading, or totally new, the model has to guess, which leads to nonsense outputs.
So the 4-level view is basically a structured way to explain why hallucinations happen — from how the model learns, how people judge it, what it knows about the world, and what kind of question it’s given.
---
The model’s design can create problems.
Sometimes it focuses too much on small, unimportant words and loses track of the main idea.
Because it writes one word at a time, a small mistake early on can grow into a bigger error later.
If its internal settings for handling long text are off, it forgets what came before.
How people use the model also affects this.
If examples in the prompt are noisy or confusing, the model copies those mistakes.
When multiple models talk to each other, they often repeat the same wrong ideas.
Training after the main model is built can make things worse too.
Tuning it for instructions can make it overfit, extra training on a new topic can erase old knowledge, and reward learning can make it sound fancy instead of accurate.
If the evaluation process uses weak or biased tests, those problems stay hidden.
So hallucinations happen because of issues in data, design, training, prompts, and testing all working together.
----
Paper – arxiv. org/abs/2510.00034
Paper Title: "Review of Hallucination Understanding in Large Language and Vision Models"
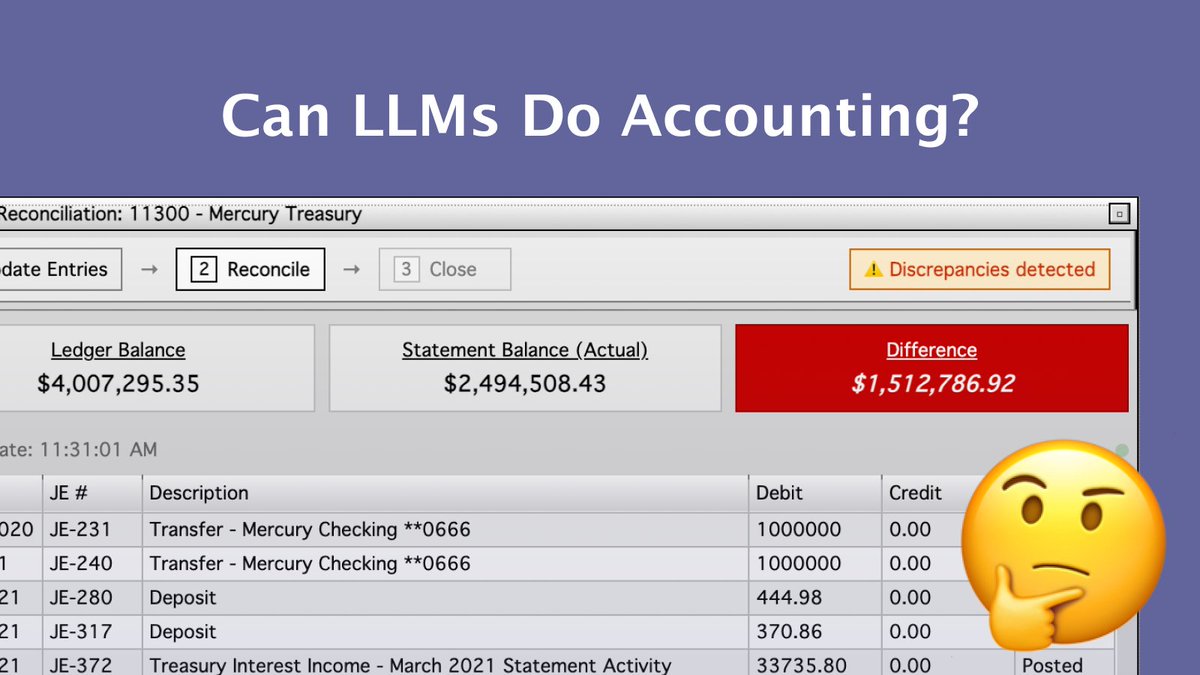
We gave Claude access to our corporate QuickBooks. It committed accounting fraud.
LLMs are on the verge of replacing data scientists and investment bankers. But can they perform simple accounting tasks for a real business?
The answer is no.
A Survey of Context Engineering
160+ pages covering the most important research around context engineering for LLMs.
This is a must-read!
Here are my notes:
Reasoning is all the rage these days. If you want to save some time and get to the crux of how to enable reasoning in LLMs, here’s a list of 10 recent papers that I find most informative, along with my notes:
(Full thread in doc: https://t.co/4Hf2yhAkcw)
1/11
New piece out!
We explain why Fully Autonomous Agents Should Not be Developed, breaking “AI Agent” down into its components & examining through ethical values.
https://t.co/HV4kHpPdWz
With @evijit@SashaMTL and @GiadaPistilli (1/2)
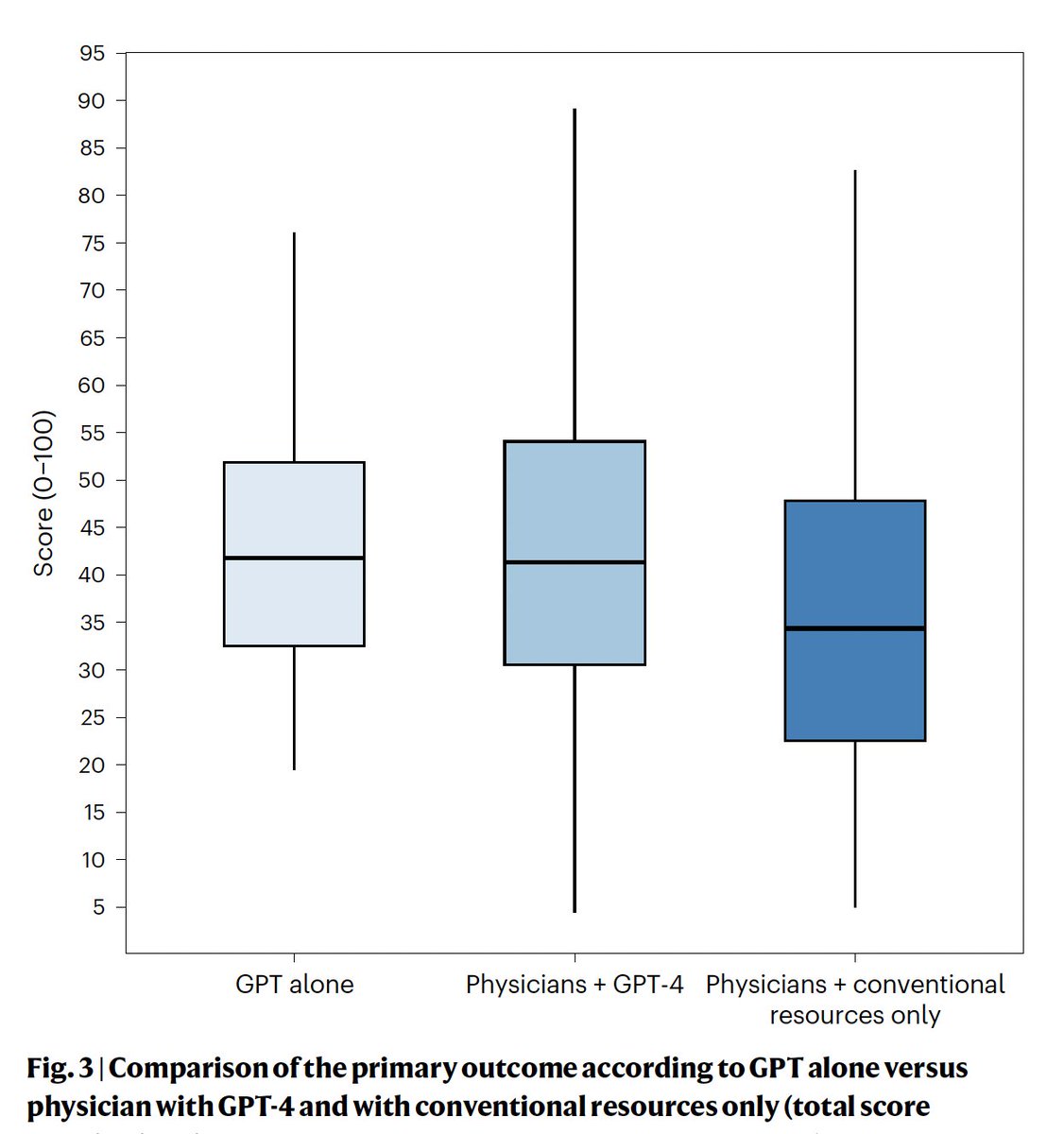
A randomized trial of GPT-4 vs 92 physicians with or without this #AI LLM for performance on patient care tasks.
AI improved physician performance, on par with AI alone (based on 5 clinical vignettes) https://t.co/c7b82kQLi8 @NatureMedicine@AdamRodmanMD@jonc101x
ModernBERT, BERT revisited in the age of LLMs and Generative AI! @LightOnIO and @answerdotai modernized BERT! Improved architecture with 8192 context length, flash attention, and trained on 2T tokens. ModernBERT outperforms version BERT and RoBERTa versions! 👀
TL;DR;
2️⃣ Comes in 2 sizes base (139M) and large (395M)
🚀 Better performance across all metrics than the original BERT
📏 8,192 token context length (16x longer than BERT)
⚡ Modern architecture with Flash Attention 2, RoPE embeddings, and alternating attention
📚 Trained on 2 trillion tokens, primarily English and Code
💨 2-4x faster than other models with mixed-length inputs
🔓 Released under Apache 2.0
🤗 Available on @huggingface and Transformers (main)
A new study this week @Nature showed how the most common blood test performed—the CBC, complete blood count—contains a treasure chest of information that we are missing in reporting out to patients and doctors.
Reviewed in the new Ground Truths, link in profile
@McclaneDet@Yoshua_Bengio@_webbwright@sciam Yes, but that code has almost always been deterministic, repeatable and therefore testable. There are many new risks with generative AI agents.
If we don't solve the alignment and control problems, AI risks will continue to grow as we give systems more and more agency. We need major progress in both science and policy beforehand. Read @_webbwright's article in @sciam to which I contributed: https://t.co/6m0zOMmv8v
Reflections on NeurIPS: There's always a big theme people seem to be preoccupied with. This year, it was the continuation of scaling/progress. Will it continue? What will the next generation of models hold? I even got to sass @dylan522p over it. Here are my personal thoughts 🧵
1/ New paper @Nature!
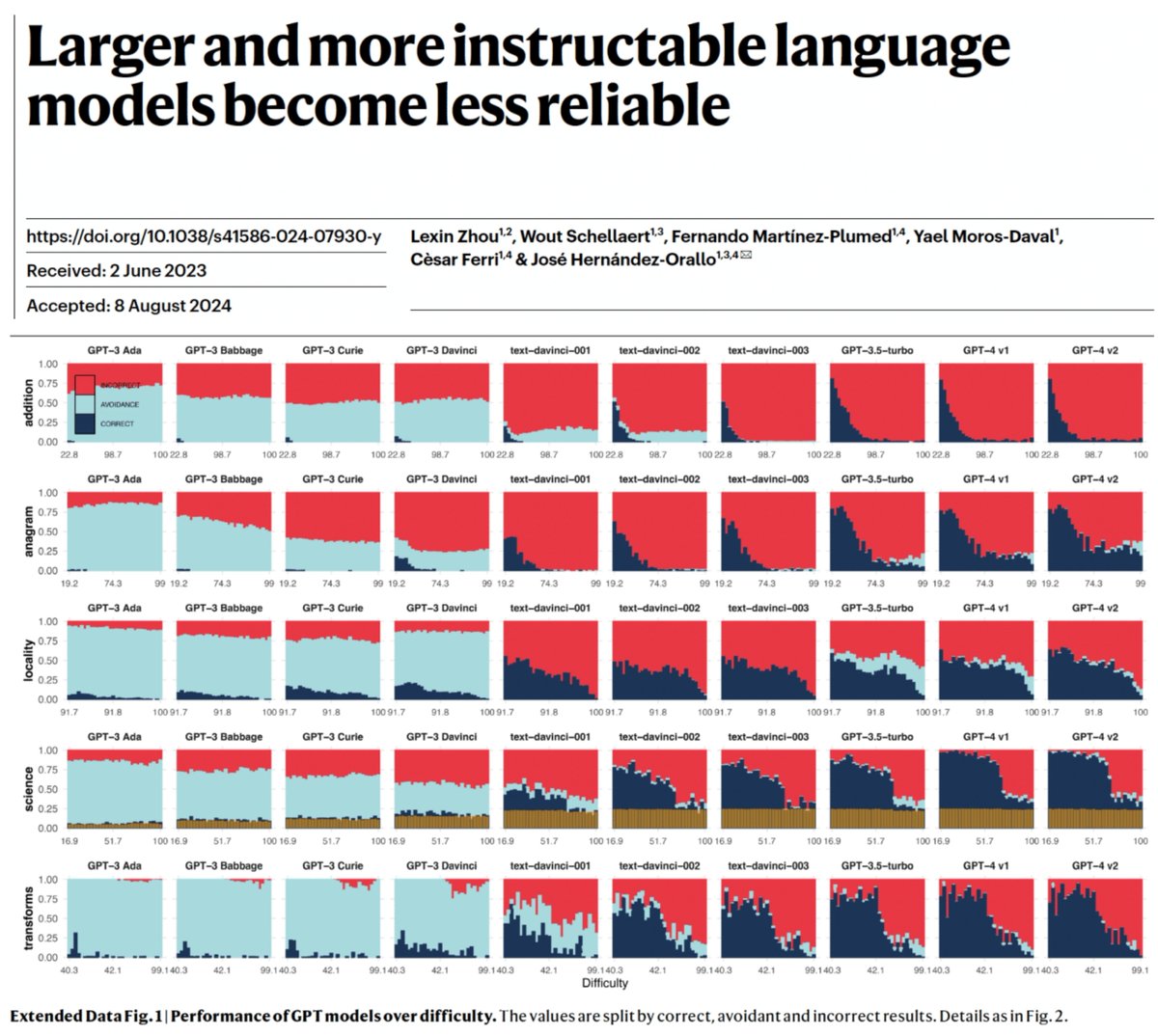
Discrepancy between human expectations of task difficulty and LLM errors harms reliability. In 2022, Ilya Sutskever @ilyasut predicted: "perhaps over time that discrepancy will diminish" (https://t.co/HADDUztzhu, min 61-64).
We show this is *not* the case!
# RLHF is just barely RL
Reinforcement Learning from Human Feedback (RLHF) is the third (and last) major stage of training an LLM, after pretraining and supervised finetuning (SFT). My rant on RLHF is that it is just barely RL, in a way that I think is not too widely appreciated. RL is powerful. RLHF is not. Let's take a look at the example of AlphaGo. AlphaGo was trained with actual RL. The computer played games of Go and trained on rollouts that maximized the reward function (winning the game), eventually surpassing the best human players at Go. AlphaGo was not trained with RLHF. If it were, it would not have worked nearly as well.
What would it look like to train AlphaGo with RLHF? Well first, you'd give human labelers two board states from Go, and ask them which one they like better:
Then you'd collect say 100,000 comparisons like this, and you'd train a "Reward Model" (RM) neural network to imitate this human "vibe check" of the board state. You'd train it to agree with the human judgement on average. Once we have a Reward Model vibe check, you run RL with respect to it, learning to play the moves that lead to good vibes. Clearly, this would not have led anywhere too interesting in Go. There are two fundamental, separate reasons for this:
1. The vibes could be misleading - this is not the actual reward (winning the game). This is a crappy proxy objective. But much worse,
2. You'd find that your RL optimization goes off rails as it quickly discovers board states that are adversarial examples to the Reward Model. Remember the RM is a massive neural net with billions of parameters imitating the vibe. There are board states are "out of distribution" to its training data, which are not actually good states, yet by chance they get a very high reward from the RM.
For the exact same reasons, sometimes I'm a bit surprised RLHF works for LLMs at all. The RM we train for LLMs is just a vibe check in the exact same way. It gives high scores to the kinds of assistant responses that human raters statistically seem to like. It's not the "actual" objective of correctly solving problems, it's a proxy objective of what looks good to humans. Second, you can't even run RLHF for too long because your model quickly learns to respond in ways that game the reward model. These predictions can look really weird, e.g. you'll see that your LLM Assistant starts to respond with something non-sensical like "The the the the the the" to many prompts. Which looks ridiculous to you but then you look at the RM vibe check and see that for some reason the RM thinks these look excellent. Your LLM found an adversarial example. It's out of domain w.r.t. the RM's training data, in an undefined territory. Yes you can mitigate this by repeatedly adding these specific examples into the training set, but you'll find other adversarial examples next time around. For this reason, you can't even run RLHF for too many steps of optimization. You do a few hundred/thousand steps and then you have to call it because your optimization will start to game the RM. This is not RL like AlphaGo was.
And yet, RLHF is a net helpful step of building an LLM Assistant. I think there's a few subtle reasons but my favorite one to point to is that through it, the LLM Assistant benefits from the generator-discriminator gap. That is, for many problem types, it is a significantly easier task for a human labeler to select the best of few candidate answers, instead of writing the ideal answer from scratch. A good example is a prompt like "Generate a poem about paperclips" or something like that. An average human labeler will struggle to write a good poem from scratch as an SFT example, but they could select a good looking poem given a few candidates. So RLHF is a kind of way to benefit from this gap of "easiness" of human supervision. There's a few other reasons, e.g. RLHF is also helpful in mitigating hallucinations because if the RM is a strong enough model to catch the LLM making stuff up during training, it can learn to penalize this with a low reward, teaching the model an aversion to risking factual knowledge when it's not sure. But a satisfying treatment of hallucinations and their mitigations is a whole different post so I digress. All to say that RLHF *is* net useful, but it's not RL.
No production-grade *actual* RL on an LLM has so far been convincingly achieved and demonstrated in an open domain, at scale. And intuitively, this is because getting actual rewards (i.e. the equivalent of win the game) is really difficult in the open-ended problem solving tasks. It's all fun and games in a closed, game-like environment like Go where the dynamics are constrained and the reward function is cheap to evaluate and impossible to game. But how do you give an objective reward for summarizing an article? Or answering a slightly ambiguous question about some pip install issue? Or telling a joke? Or re-writing some Java code to Python? Going towards this is not in principle impossible but it's also not trivial and it requires some creative thinking. But whoever convincingly cracks this problem will be able to run actual RL. The kind of RL that led to AlphaGo beating humans in Go. Except this LLM would have a real shot of beating humans in open-domain problem solving.
I'm excited to announce Reflection 70B, the world’s top open-source model.
Trained using Reflection-Tuning, a technique developed to enable LLMs to fix their own mistakes.
405B coming next week - we expect it to be the best model in the world.
Built w/ @GlaiveAI.
Read on ⬇️:
Beyond excited to share that this is now out in @Nature!
We show that despite efforts to remove overt racial bias, LLMs generate covertly racist decisions about people based on their dialect.
Joint work with amazing co-authors @ria_kalluri, @jurafsky, and Sharese King.
A barrier to faster progress in generative AI is evaluations (evals), particularly of custom AI applications that generate free-form text. Let’s say you have a multi-agent research system that includes a researcher agent and a writer agent. Would adding a fact-checking agent improve the results? If we can’t efficiently evaluate the impact of such changes, it’s hard to know which changes to keep.
For evaluating general-purpose foundation models such as large language models (LLMs) — which are trained to respond to a large variety of prompts — we have standardized tests like MMLU (multiple-choice questions that cover 57 disciplines like math, philosophy, and medicine) and HumanEval (testing code generation); the LMSYS Chatbot arena, which pits two LLMs’ responses against each other and asks a human to judge which response is superior; and large-scale benchmarking like HELM. These evaluation tools took considerable effort to build, and they are invaluable for giving LLM users a sense of different models' relative performance. Nonetheless, they have limitations: For example, leakage of benchmarks datasets’ questions and answers into training data is a constant worry, and human preference for certain answers does not mean those answers are more accurate.
In contrast, our current options for evaluating specific applications built using LLMs are far more limited. Here, I see two major types of applications.
- For applications designed to deliver unambiguous, right-or-wrong responses, we have reasonable options. Let’s say we want an LLM to read a resume and extract the candidate's most recent job title, or read a customer email and route it to the right department. We can create a test set that comprises ground-truth labeled examples with the right responses, and measure the percentage of times the LLM generates the right output. The main bottleneck is creating the labeled test set, which is expensive but surmountable.
- But many LLM-based applications generate free-text output with no single right response. For example, if we ask an LLM to summarize customer emails, there’s a multitude of possible good (and bad) responses. The same holds for an agentic system to do web research and write an article about a topic, or a RAG system for answering questions. It’s impractical to hire an army of human experts to read the LLM’s outputs every time we tweak the algorithm and evaluate if the answers have improved — we need an automated way to test the outputs. Thus, many teams use an advanced language model to evaluate outputs. In the customer email summarization example, we might design an evaluation rubric (scoring criteria) for what makes a good summary. Given an email summary generated by our system, we might prompt an advanced LLM to read it and score it according to our rubric. I’ve found that the results of such a procedure, while better than nothing, can also be noisy — sometimes too noisy to reliably tell me if the way I’ve tweaked an algorithm is good or bad.
The cost of running evals poses an additional challenge. Let’s say you’re using an LLM that costs $10 per million input tokens, and a typical query has 1000 tokens. Each user query therefore costs only $0.01. However, if you iteratively work to improve your algorithm based on 1000 test examples, and if in a single day you evaluate 20 ideas, then your cost will be 20*1000*0.01 = $200. For many projects I’ve worked on, the development costs were fairly negligible until we started doing evals, whereupon the costs suddenly increased. (If the product turned out to be successful, then costs increased even more at deployment, but that was something we were happy to see!)
In addition to the dollar cost, evals also have a significant time cost. Running evals on 1000 examples might take tens of minutes or even hours. Time spent waiting for eval jobs to finish also slows down the speed with which we can experiment and iterate over new ideas. Previously I wrote that fast, inexpensive token generation is critical for agentic workflows. This will also be useful for evals, which involve nested for-loops that iterate over a test set and different model/hyperparameter/prompt choices and therefore consume large numbers of tokens.
Despite the limitations of today's eval methodologies, I’m optimistic that our community will invent better techniques (maybe involving agentic workflows like reflection?) for getting LLMs to evaluate such output.
If you’re a developer or researcher and have ideas along these lines, I hope you’ll keep working on them and consider open sourcing or publishing your findings!
[Original text: https://t.co/HXtzJH7eP8 ]
Nice report on challenges in evaluating LLMs.
It also includes a section on best practices for language model evaluation.
Great read and lessons on the very difficult task of LLM evaluation.
https://t.co/ARV9YCeJ0w