Great work by @Vtrivedy10@nikogrupen et al - great to see these results in Law, mirroring our experiments published yesterday in Medicine
1. Batch grading reduces cost by ~1 OOM
2. Small models reduce cost by ~2 OOM
In non-verifiable RL, where judge latency blocks samples reaching the trainer, judge selection is a crucial knob for training efficiency.
Medicine:
https://t.co/CTQr1do8kn
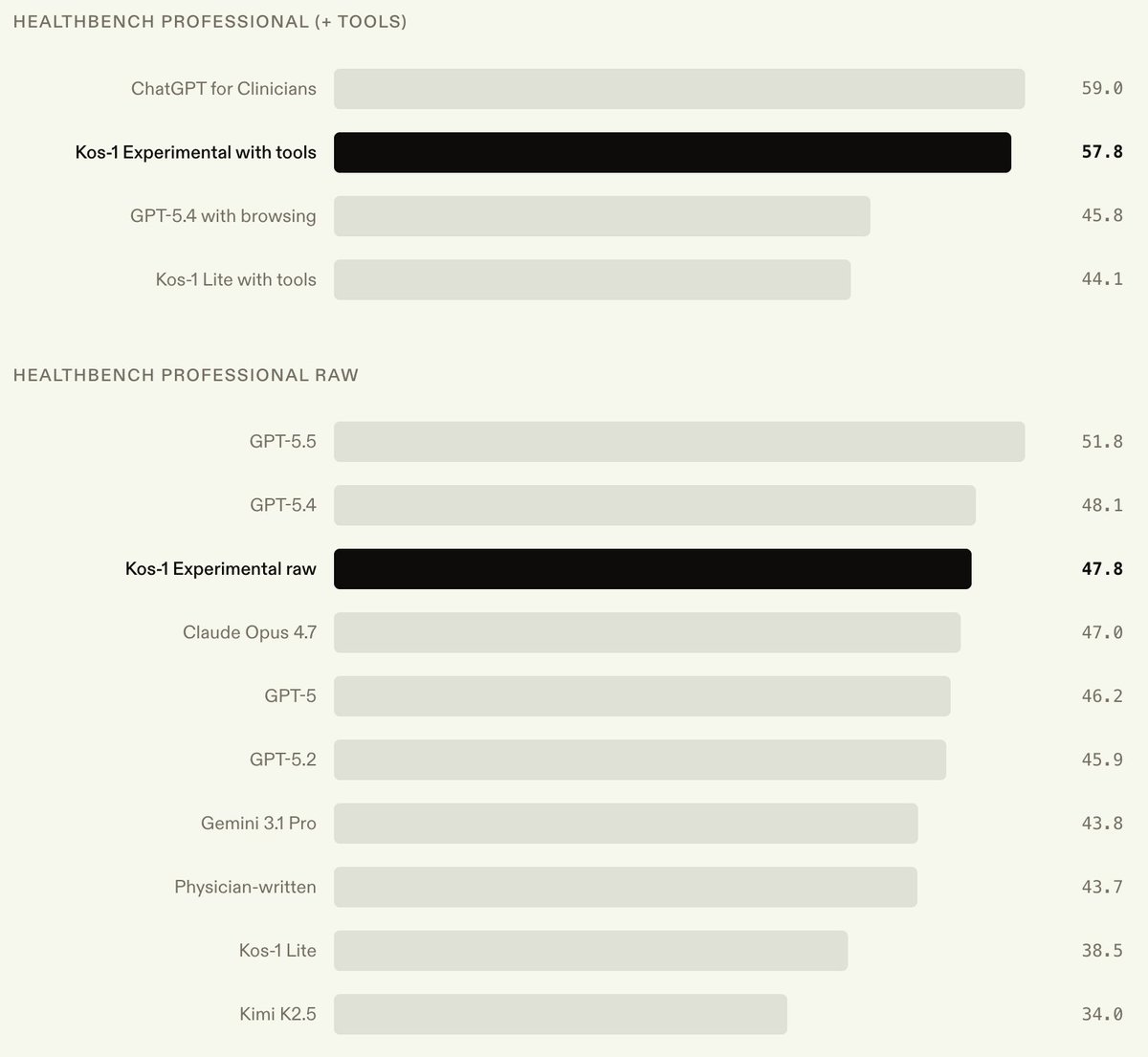
We're releasing early results from training Kos-1 Experimental, a Kimi K2.5 checkpoint post-trained on the same medical RL data we used for Kos-1 Lite.
As clinical workloads become more agentic, we wanted a model that pairs medical domain knowledge with tool-calling knowhow.
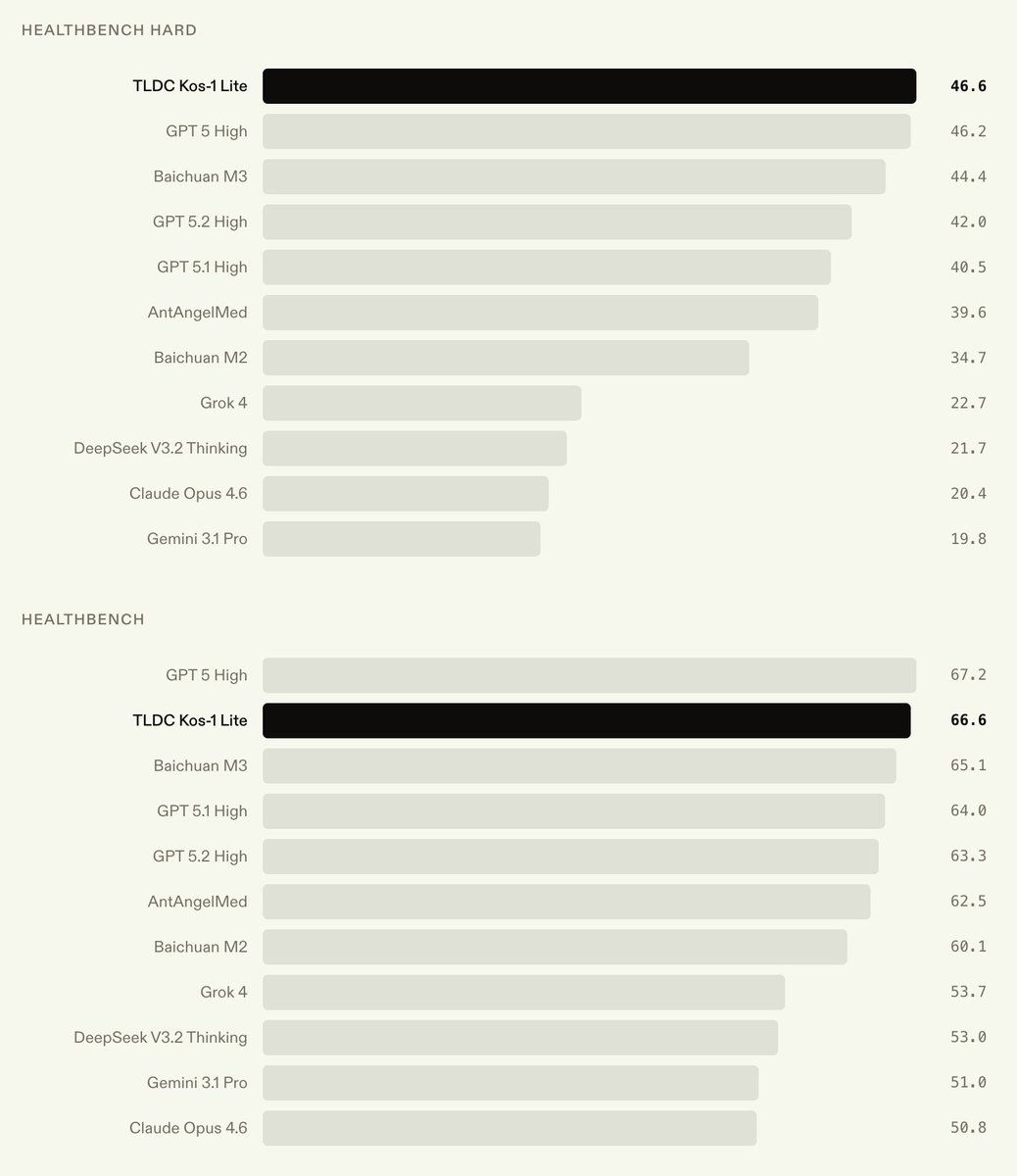
We’re announcing Kos-1 Lite, a medical model that achieves SOTA on HealthBench Hard at 46.6%.
As a medium sized language model (~100B), it achieves these results at a fraction of the serving cost of frontier trillion-parameter models.
(1/5)
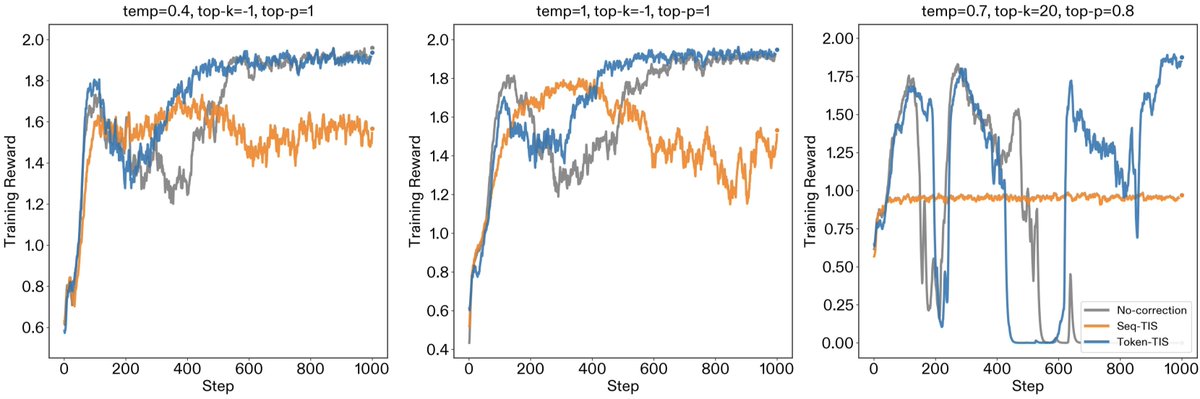
New post: "Mismatch Praxis: Rollout Settings and IS Corrections". We pressure-tested solutions for inference/training mismatch.
Inference/training mismatch in modern RL frameworks creates a hidden off-policy problem. To resolve the mismatch, various engineering (e.g., FP16 unification, deterministic kernels) and algorithmic (e.g., importance sampling) fixes have been proposed. In this work, we examine how rollout settings (temp, top-p, and top-k) affect mismatch, and how importance sampling corrections bear out in practice.
We find that while Sequence-TIS is theoretically optimal, it can succumb to catastrophic variance in long-horizon contexts. Additionally, non-standard rollout settings create subtle mismatch patterns that require careful engineering fixes. Token-TIS with default rollout settings proved to be the most robust setting for long-horizon training.
@chiswanjo Good thanks for asking! Building a small tool to help improve landing page conversion rates. But most importantly, I'm finishing up my thesis due in two weeks 🤓
@gabriel__xyz Hi! I'm a data science student currently writing my bachelor's thesis about systematically reducing parameters in LLMs.
I tweet about cool stuff I find in the AI field and side projects I'm doing. Happy to connect!
@programmerByDay@gabriel__xyz Hi Arman! Cool, I just got back from Australia after spending 4 months on the east coast studying. Loved it there. Would love to follow along your journey!
Spain has some of the coolest trains. Not the regular commuter trains, but the high speed ones
This is a Frecciarossa 1000 that runs in Italy, France and Spain.
Barcelona -> Madrid is done in just 3.5 hours and you go from center to center while working comfortably.
The beauty of training 12 TinyBERT models while cruising 300 km/h across the Spanish country side in a bullet train. Training in a train. Damn I love technology 🤖 🚆
#indiehackers#buildinpublic