🚀 Hello, Kimi K2 Thinking!
The Open-Source Thinking Agent Model is here.
🔹 SOTA on HLE (44.9%) and BrowseComp (60.2%)
🔹 Executes up to 200 – 300 sequential tool calls without human interference
🔹 Excels in reasoning, agentic search, and coding
🔹 256K context window
Built as a thinking agent, K2 Thinking marks our latest efforts in test-time scaling — scaling both thinking tokens and tool-calling turns.
K2 Thinking is now live on https://t.co/YutVbwktG0 in chat mode, with full agentic mode coming soon. It is also accessible via API.
🔌 API is live: https://t.co/EOZkbOwCN4
🔗 Tech blog: https://t.co/n7xxaszqzF
🔗 Weights & code: https://t.co/4ukcXB0iP6
Stanford researchers just solved why AI agents keep failing.
They watched 500+ agent failures across three benchmarks.
Found a pattern nobody expected:
Early mistakes don't just cause problems - they cascade into complete system meltdowns.
It's called error propagation.
One wrong memory recall at step 3. By step 10, the agent's lost. By step 20, it's putting soap in toilets instead of finding saltshakers.
So they built AgentDebug - a framework that can literally diagnose where LLM agents go wrong and fix themselves.
Think of it as therapy for AI, but it actually works.
This framework does three things:
→ First, it maps every error to specific modules - memory, planning, reflection, action.
→ Second, it hunts down THE critical failure that doomed everything.
→ Third, it provides surgical feedback at that exact failure point.
The metrics are insane:
• 45% step accuracy (vs 28% for baselines)
• 24% better at finding root causes
• Up to 26% relative improvement in task success
• Small models gain MORE than large ones
But here's what's wild:
They found most failures cluster at steps 6-15, where early mistakes compound into chaos.
Planning errors lead (78 cases), followed by reflection and memory. Agents literally hallucinate events that never happened. They misinterpret outcomes or ignore constraints.
AgentDebug doesn't fix every error. It hunts down the ONE critical mistake that derailed everything, then provides targeted feedback for re-execution. Instead of restarting from scratch, it surgically corrects at the failure point.
The future of AI might not be about making perfect agents. It might be about building agents that can debug themselves - turning every failure into a learning opportunity.
We're not preventing AI from making mistakes. We're teaching it to evolve through them.
In a world where artificial intelligence can replicate a person’s voice or face in seconds, Denmark is stepping forward with a groundbreaking proposal: a copyright law that grants every citizen ownership of their own likeness.
If passed, this law would mean no one — not even AI companies — could legally use your face, voice, or body data without consent. The move comes amid growing global concerns about deepfakes, where digital replicas of real people are used in scams, misinformation, and even political manipulation.
Nice, short post illustrating how simple text (discrete) diffusion can be.
Diffusion (i.e. parallel, iterated denoising, top) is the pervasive generative paradigm in image/video, but autoregression (i.e. go left to right bottom) is the dominant paradigm in text. For audio I've seen a bit of both.
A lot of diffusion papers look a bit dense but if you strip the mathematical formalism, you end up with simple baseline algorithms, e.g. something a lot closer to flow matching in continuous, or something like this in discrete. It's your vanilla transformer but with bi-directional attention, where you iteratively re-sample and re-mask all tokens in your "tokens canvas" based on a noise schedule until you get the final sample at the last step. (Bi-directional attention is a lot more powerful, and you get a lot stronger autoregressive language models if you train with it, unfortunately it makes training a lot more expensive because now you can't parallelize across sequence dim).
So autoregression is doing an `.append(token)` to the tokens canvas while only attending backwards, while diffusion is refreshing the entire token canvas with a `.setitem(idx, token)` while attending bidirectionally. Human thought naively feels a bit more like autoregression but it's hard to say that there aren't more diffusion-like components in some latent space of thought. It feels quite possible that you can further interpolate between them, or generalize them further. And it's a component of the LLM stack that still feels a bit fungible.
Now I must resist the urge to side quest into training nanochat with diffusion.
🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support.
🧠 Compresses visual contexts up to 20× while keeping 97% OCR accuracy at <10×.
📄 Outperforms GOT-OCR2.0 & MinerU2.0 on OmniDocBench using fewer vision tokens.
🤝 The vLLM team is working with DeepSeek to bring official DeepSeek-OCR support into the next vLLM release — making multimodal inference even faster and easier to scale.
🔗 https://t.co/rnBG9VUuMy
#vLLM #DeepSeek #OCR #LLM #VisionAI #DeepLearning
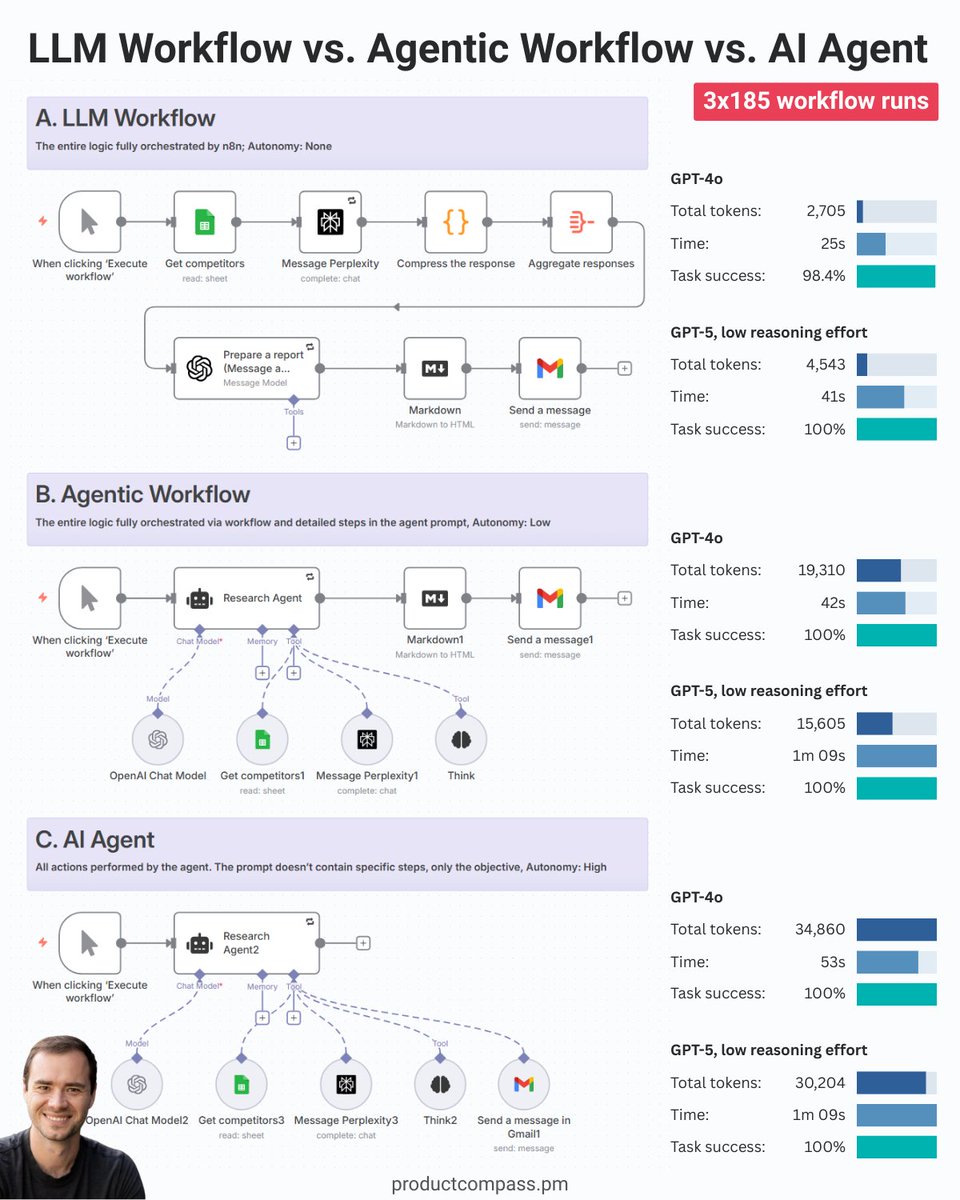
After an interview with @karpathy, everyone is talking about what AI agents can/can't do.
But an opinion without data is just a hypothesis.
So, I tested 3x185 workflow executions for a market researcher agent.
The results have shocked me🧵
@adarshb__ May be , all depends upon change in people's behaviour. Google has cracked the problem of quality of content, emerging AI search to match or exceed those standards
@lazyiitian This could be even more, however change management is critical for realisation as core critical system of companies are running on this dinasaur
Thrilled for #IGC23 to explore cutting-edge gaming innovations and connect with industry leaders shaping the future of gaming in India! 🎮🚀 #GamingRevolution#IndiaGaming
Thanks @sureshpprabhu@investindia @DIPPGOI for the opportunity to present our case reg ePharmacy. V encouraged w/ the support & +ve intent. Thankful to @SEswaraReddy for proactively resolving all issues. eHealth will thrive if we all work together:Lets make it easy fr patients https://t.co/9B4lJunBkP