The Pokémon Pokopia Expansion Pass paid DLC is available for purchase today. Part 1: Bubbly Basin is planned for release this August!
Enjoy an underwater town, new Pokémon to encounter, furniture, and outfits for Ditto. #NintendoDirect
https://t.co/FIHb61bgj8
As an AI Engineer. Please learn
>Harness engineering, not just prompt engineering
>Context engineering, not just long prompts
>Prompt caching vs. semantic caching tradeoffs
>KV cache management, eviction, reuse, and memory pressure at scale
>Prefill vs. decode latency and why they optimize differently
>Continuous batching, paged attention, and throughput optimization
>Speculative decoding vs. quantization vs. distillation tradeoffs
>INT8, INT4, FP8, AWQ, GPTQ, and when quantization hurts quality
>Structured output failures, schema validation, repair loops, and fallback chains
>Function calling reliability, tool contracts, argument validation, and idempotency
>Agent guardrails, loop budgets, tool budgets, and termination conditions
>Model routing, graceful fallback logic, and degraded-mode UX
>RAG architecture: chunking, embeddings, hybrid search, reranking, and freshness
>Retrieval evals: recall, precision, grounding, attribution, and citation quality
>Evals: golden sets, regression tests, adversarial tests, LLM-as-judge, and human evals
>LLM observability as a first-class discipline: traces, spans, tokens, latency, errors, and drift
>Cost attribution per feature, workflow, tenant, and user journey not just per model
>Safety engineering: prompt injection defense, data leakage prevention, and permission boundaries
>Multi-tenant isolation, cache safety, and cross-user context contamination prevention
>Fine-tuning vs. in-context learning vs. RAG vs. distillation and when each is the wrong tool
>Latency, quality, cost, and reliability tradeoffs across the full inference stack
>Production failure modes: hallucinated tool calls, malformed JSON, stale retrieval, runaway agents, and silent eval regressions
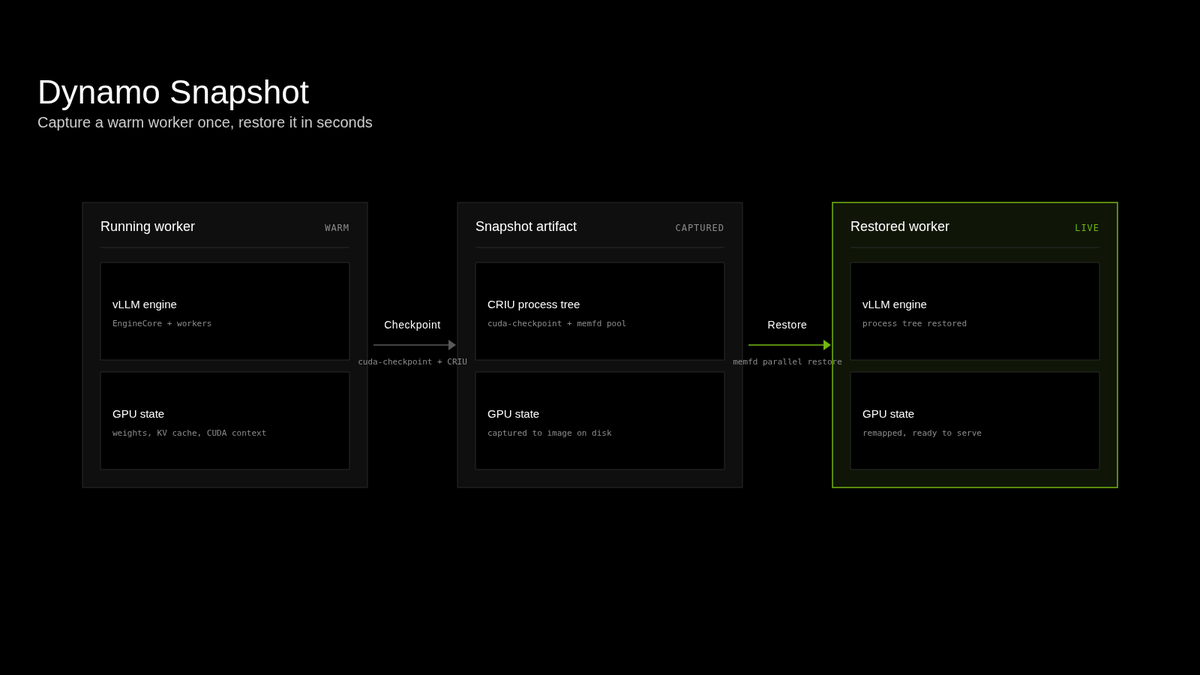
Introducing Dynamo Snapshot, our approach for fast startup for inference workloads on Kubernetes, which reduces startup time from minutes to under 5 seconds.
In production inference deployments demand fluctuates over time. Cold-starting inference workloads can take minutes, leaving idle GPUs that generate no tokens and serve no requests.
Snapshot leverages GMS to enable concurrent weight restoration over a high-speed interconnect, while using Linux native AIO and parallel memfd restoration to accelerate CRIU restore performance.
Unless you’re ready to spend serious time (and money) tuning hyperparameters, don’t mess with LLM reasoning traces.
I evaluated multiple reasoning budgets and BNF grammar / structured CoT settings on Qwen3.6 27B.
The results are underwhelming.
Yes, it can work: for a few specific tasks, it significantly reduces inference cost by shortening reasoning traces while preserving accuracy.
But in most settings, simply disabling reasoning is better, both for token efficiency and accuracy.
Full analysis here:
https://t.co/xxLLzVkASx
Thanks to the community report, we recently identified a PR https://t.co/QWboSmskkF that attempted to solve a non-existent issue and was submitted as part of a “PR training” workflow for resume building.
The contributor involved has been banned from the vLLM community.
This kind of low-signal contribution increases maintainer review overhead and creates unnecessary operational costs for open-source projects.
As AI coding agents make generating large volumes of small PRs increasingly cheap, open-source communities will need to explore new ways to preserve contribution quality and reviewer trust.
While we are investigating how to deal with AI slop, we continue to highly value contributions from real users solving real production problems.
If you have an important contribution that has not yet received maintainer attention, please email us at:
[email protected]
Using a verifiable company or university email, include:
- your production or research use case
- the problem you encountered
- how your contribution addresses it
This helps us better prioritize impactful contributions while keeping the vLLM community open and collaborative.
As AI makes virtual contributors look increasingly real, authentic human collaboration matters more than ever.
vLLM’s mission remains unchanged: to make LLM inference easy, fast, and cheap for everyone — and we will continue working toward that goal.
instead of watching 2 hours of Netflix tonight, watch this 40-minute masterclass from the founder of a $20B China AI company
it's the clearest explanation I've seen of how Agent Swarms and AI systems actually work at scale
useful whether you've never built an agent in your life or have been using Claude every day for the past year
I took the key ideas and turned them into a practical guide on how to actually build with Kimi
find it below
🚨 OBLITERATION ALERT 🚨
QWEN-3.6-27B: OBLITERATED ⛓️💥
https://t.co/AScXN4XLwx
I can't take much credit for this one! The entire process was done by jailbroken codex (gpt-5.5-xhigh) wielding the full OBLITERATUS suite. Hit with source-tethered ASPA. Dozens of iterations.
Result? A mere 4% refusal rate on the 842-prompt OBLITERATUS harmful corpus; one of the most rigorous prompt gauntlets in AI.
The /goal was simple:
1) Carve out the refusal circuits. Mutate methodology + iterate until <5% refusal (quality-gate).
2) Keep the 27B mind alive. No capability degradation tolerated.
And somehow… it worked. 🤯
The numbers talk:
842-pair longform gauntlet:
— 95.84% non-refusal
— 93.94% quality pass
— 0 short outputs
— 99.52% clean endings
MMLU-Pro:
— 51/70 (stock Qwen) → 51/70 (OBLITERATED Qwen)
Raw capability completely preserved 🙌
Q4_K_M through Q8_0 all running smooth.
Q8_0 is the big one: 28.6GB near-full-quality GGUF.
Runs with llama.cpp, LM Studio, Ollama, and more!
Chains cut.
The fire still burns.
The fangs have been sharpened.
REBIRTH COMPLETE
A gift from my agents to yours 🫶
gg
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.