SerDes is the foundational building block of high-speed networking, present in every XPU, switch, high-speed interface, and optical component in a modern data center. Its performance has a direct impact on power consumption, latency, bandwidth, link length, and ultimately total cost of ownership.
Marvell has doubled the line speed of its leading SerDes approximately every two years. The most recent demonstration of 224G long-range SerDes achieved lane bit error rates of 1e-11 at 4 picojoules per bit across a 2.5-meter CPC-backplane-CPC channel, with up to 512 lanes integrable into a 102.4T switch.
Senior Staff Engineer Aatreya Chakravarti explains how the technology works, where it fits within the broader connectivity stack, and why SerDes leadership remains central to scaling AI infrastructure: https://t.co/LN6LbVHieU
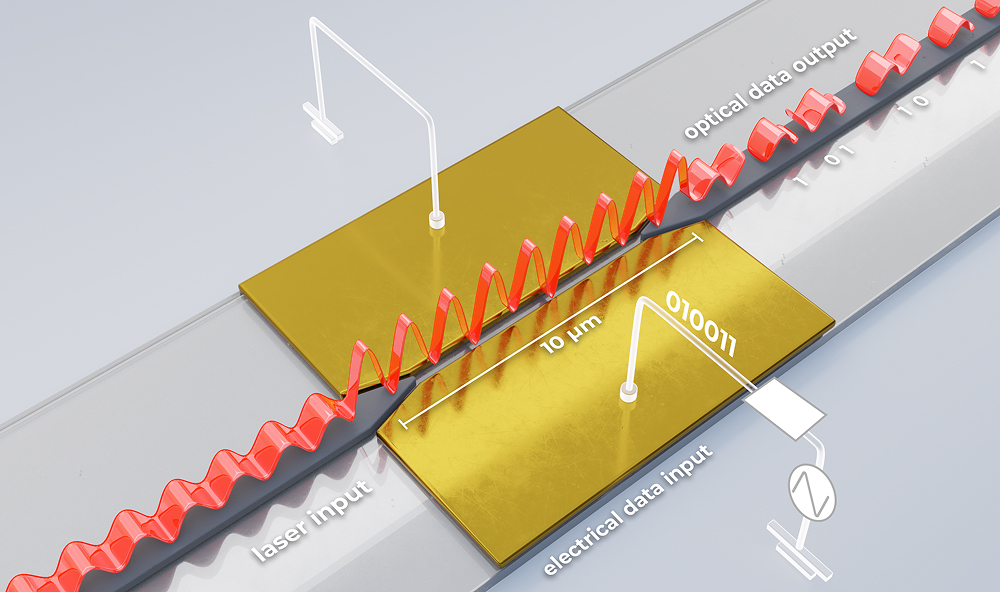
Contemporary silicon photonics modulators are constrained by the diffraction limit of light, restricting their ability to scale efficiently to the bandwidths AI infrastructure will require. Plasmonics offers a path forward.
By compressing light below the diffraction limit at a metal-dielectric interface, plasmonic modulators can operate at speeds exceeding 1 THz, more than 10x faster than conventional photonic modulators, while measuring approximately 10 microns in length, 300x to 500x shorter. The result is exponentially higher bandwidth density within the same silicon photonics platform, without requiring a shift to new material systems.
Marvell Senior Director Claudia Hoessbacher and Director Wolfgang Heni of Optical Engineering detail the technology, its applications across scale-up and scale-across networks, and where development stands today.
Read more: https://t.co/3z9yPJxzac
Deploying next-generation optical connectivity at the pace AI infrastructure demands requires more than advanced technology. It requires standards that reduce integration complexity and give data center operators flexibility at the time of deployment.
The Open CPX MSA, which includes Marvell among its members, is building that foundation. A single CPX array can be configured to support co-packaged copper for intra-rack connections, co-packaged optics for rack-to-rack communication, and ZR/ZR+ modules for long-distance interconnects, with port configurations determined at deployment rather than at design time.
With near- and co-packaged port shipments projected to grow from under one million in 2025 to more than 100 million per year by 2030, that kind of flexibility matters. George Hervey explains what Open CPX makes possible: https://t.co/6LsXZ5M2hU
In an exclusive interview with DIGITIMES at Computex 2026, Marvell President and Chief Operating Officer Chris Koopmans covered a lot of ground: the company's decade-long transformation into a data infrastructure leader, why securing supply chain capacity is ultimately about trust, and how the transition from copper to optical will unfold over the next five years in scale-up networks.
On the copper wall: "The copper wall will eventually fall." On the ASIC business: it is fundamentally an I/O business, not an XPU business. And on supply constraints: the current environment may actually be healthier for the long-term trajectory of the AI industry than unconstrained growth would be.
A substantive read for anyone tracking where AI infrastructure is headed: https://t.co/FbpoMeJhwL
One of AI's three big problems is power consumption, which is becoming a hard constraint in AI infrastructure. Data center power limits are tightening, and a significant portion of the energy modern AI systems consume is spent simply moving data between compute and memory.
Marvell Photonic Fabric technology addresses that directly. By integrating optics closer to the XPU, the platform delivers up to 2x greater energy efficiency compared to copper, while also supporting up to 2x more compute within the same power and space footprint.
The same platform extends scale-up clusters beyond a single rack, and enables pod-scale memory sharing across systems. Senior Director of Product Management Uday Poosarla details how it all works together: https://t.co/i9IeQ0ciNm
Memory architecture is a technical challenge, but it is also a financial one. This clip puts the economics in clear terms.
At the International Semiconductor Industry Group (ISIG) Executive Summit, Sandeep Bharathi makes the capital allocation case for memory pooling. When processors cannot access their full dedicated memory, the unused capacity is stranded, generating cost without generating value. Pooling that memory across systems can reduce total cost of ownership by 50 to 70%.
The business model implications follow directly: lower TCO, faster time to first token, and higher throughput per millisecond translate to better margins for hyperscalers running inference at scale.
See the video here: https://t.co/Q8c6ebez6X
A powerful week at COMPUTEX 2026. Marvell brought forward breakthrough innovation and a compelling vision for the evolution of AI infrastructure. The energy was electric and the momentum across the ecosystem is unmistakable.
Learn more: https://t.co/lLn5FcppVV
For the 13th year, Marvell employees laced up and ran together, spanning 36 sites across the globe.
The Marvell Global 5K has become more than an annual event. It reflects something true about how this company operates: the work is demanding, the problems we solve are consequential, and we do it as one team, no matter the time zone.
Building the semiconductor infrastructure that powers AI takes endurance, precision, and the kind of collaboration that only comes from a team that genuinely enjoys working together. The Global 5K is a reminder of all three.
Congratulations to every runner, volunteer, and organizer who made this year's event possible across six continents.
The tension between memory access and compute performance is not a new problem. What is new is the scale at which AI infrastructure has made it urgent.
In this clip from the International Semiconductor Industry Group (ISIG) Executive Summit, Marvell President of the Data Center Group Sandeep Bharathi traces the memory hierarchy challenge from early CPU design through to modern AI inference, and explains why re-architecting memory at the system level has become a foundational requirement. He also introduces CXL as one of the key techniques for bringing memory closer to compute, using a return to his restaurant analogy to illustrate why consistency and accessibility are equally critical.
At #COMPUTEX2026, Marvell Chairman and CEO Matt Murphy shared our vision for the next era of AI infrastructure. After major waves of innovation in compute and memory, connectivity is emerging as the next bottleneck in scaling AI. As bandwidth demands push the industry beyond the limits of copper interconnects, optics will play an increasingly important role in enabling what comes next.
Jensen Huang of @nvidia joined Matt on stage for an energizing conversation about the future of AI infrastructure and how the Marvell and NVIDIA partnership is helping shape what comes next.
We were also honored to be joined by Dr. Tien Wu of ASE. For more than a decade, Marvell and ASE have worked together to advance some of the industry’s most important technology transitions, demonstrating the power of long-term partnership and ecosystem collaboration.
The future of AI will be built together.
Watch the keynote replay: https://t.co/uOT1YEpyfS
Transformer architecture can be difficult to conceptualize. This clip makes it considerably more accessible.
At the International Semiconductor Industry Group (ISIG) Executive Summit, Marvell President of the Data Center Group Sandeep Bharathi walks through how large language models process information using a restaurant analogy, from the moment an order is taken through to the kitchen, the prep work, and the pantry. The parallel to encoder/decoder stages, KV caches, and memory fetches is intuitive and clearly drawn.
The analogy also surfaces a fundamental challenge: modern AI inference has become an energy-intensive data movement problem, and memory access sits at the center of it.
What is the most powerful energy-efficient computer ever built? The answer has important implications for how the industry should think about AI infrastructure.
In this clip from the International Semiconductor Industry Group (ISIG) Executive Summit, Marvell President of the Data Center Group Sandeep Bharathi opens with a deceptively simple question and draws a direct line from human biology to one of the most pressing design challenges in AI: the relationship between compute and memory.
COMPUTEX KICKS OFF TONIGHT!
In the wee hours of the morning in North America, the Computex Taipei 2026 conference is set to kick off in Taiwan! Here's a schedule of the MASSIVE keynote speaker docket for the conference.
Which of these speakers are you most excited to hear from?
@tradertvlive $SPY $QQQ $QCOM $MRVL $NVDA $INTC $NXPI @qualcomm@MarvellTech@intel@nvidia@NXP@cristianoamon@LipBuTan1
Marvell today introduced Teralynx T100, the industry’s first 102.4 Tbps switch silicon purpose-built for the AI era.
Unlike legacy switching platforms designed for traditional enterprise and cloud data centers, the Teralynx T100 was architected from the ground up for AI—enabling the industry’s lowest power consumption and lowest latency at this bandwidth tier to address critical bottlenecks in today’s large AI clusters. The T100 will start sampling to customers beginning this quarter.
Learn more: https://t.co/Y7rVW5V2BU
The @computextaipei keynote by Marvell Chairman and CEO Matt Murphy is just one day away. His presentation, entitled “The Future of AI Scaling Depends on Connectivity,” will be livestreamed on the Marvell website.
Learn more about the keynote and watch it here: https://t.co/uOT1YEpyfS
Co-packaged connectivity is scaling rapidly. Fewer than one million near- and co-packaged ports shipped in 2025; that figure is projected to surpass 100 million per year by 2030. Deploying technology at that volume requires standards that ensure interoperability, predictability and flexibility.
The Open CPX MSA, a consortium that includes Marvell, is developing specifications for integrating NPO and CPO technology into switches and servers in scalable, repeatable ways, with support for co-packaged copper as well.
Associate Vice President of Cloud Switch Marketing George Hervey outlines how the standard works, what it means for data center deployment, and why modular, interoperable frameworks are essential to meeting the pace of AI infrastructure buildout. Learn more: https://t.co/OP6p7vR0t6
The next phase of AI scaling will require new approaches to connectivity.
As the end-to-end connectivity leader, Marvell enables the critical connections in modern AI infrastructure to maximize data movement, from within servers and racks to the networks linking data centers across regions, allowing hyperscalers and cloud providers to deploy AI-optimized systems with unprecedented performance, scale and efficiency.
Chairman and CEO of Marvell, Matt Murphy, will deliver a keynote on this topic at @computextaipei, entitled “The Future of AI Scaling Depends on Connectivity.” The keynote will also be livestreamed on the Marvell website: https://t.co/uOT1YEpyfS
Copper continues to deliver in dense AI computing environments, and a recent demonstration at OFC 2026 shows how far the technology has advanced.
Marvell and Luxshare-Tech demonstrated 224G long-range SerDes driving signals across a 2.5-meter CPC-backplane-CPC channel, achieving lane bit error rates of 1e-11 at 4 picojoules per bit. Up to 512 lanes of the technology could be integrated into a 102.4T switch.
SerDes is the foundational building block of high-speed networking, with direct impact on power consumption, latency, bandwidth and total cost of ownership. Lowering power by a single picojoule per bit on a 200G/lane device can reduce system power consumption by up to 100 watts.
Senior Staff Engineer Aatreya Chakravarti details the demonstration and the broader role SerDes plays in scaling AI data center infrastructure: https://t.co/5pyEr8pMiU
PCIe is the world's most widely deployed chip-to-chip interconnect, and its role in AI scale-up networks is growing. Low latency and high bandwidth make it well suited for the large, multi-rack clusters at the foundation of modern AI data centers.
Marvell has demonstrated the industry's first 260-lane PCIe 6.0 switch, with 256 lanes of data traffic representing the highest radix available for a PCIe switch. The Marvell Structera S flattens the network topology, eliminating the need for multiple smaller switches and reducing complexity, latency and cost at scale.
Krishna Mallampati and Joe Slember detail the technology and how it fits within the broader Marvell PCIe portfolio: https://t.co/mpWluZjDaf