Frustrated with coding agents not having access to context in sibling repos? Yes, GitHub MCP servers is one way, but search through those tool only pulls small code windows around search terms. Very underpowered and slow. Would be great to grep or read entire files easily. Here is a quick setup I use that gives my coding agents and subagents direct access to all up-to-date sibling repo context without mucking up my dev environment
1. Make a .deps directory in your repo
2. Perform a shallow clone (--depth 1 --branch main) of all siblings repos into that dir
3. Add .deps to .gitignore, .dockerignore, and to files.exclude, search.exclude, and files.watcherExclude in .vscode/settings.json (this makes it "invisible")
4. Add a hook (.claude/hooks or .github/hooks) that performs a git fetch + git pull for the repo an agent is looking at for ALL Read|Grep|Bash(ls|grep|wc|etc) operations. This way, before every lookup we do a quick "refresh" of the repo.
5. Update all your agent files and instructions to direct them to look to .deps when they need any cross context information about sibling repos (data contracts, IaC variable names/secrets/groups, library implementation details, etc)
Now you have an always up-to-date "invisible" context layer for all of your coding agents in multi-repo environments. This has been a game changer for me. Let me know if you have any different approaches!
#ClaudeCode #GitHub #CodingAgents #DevOps
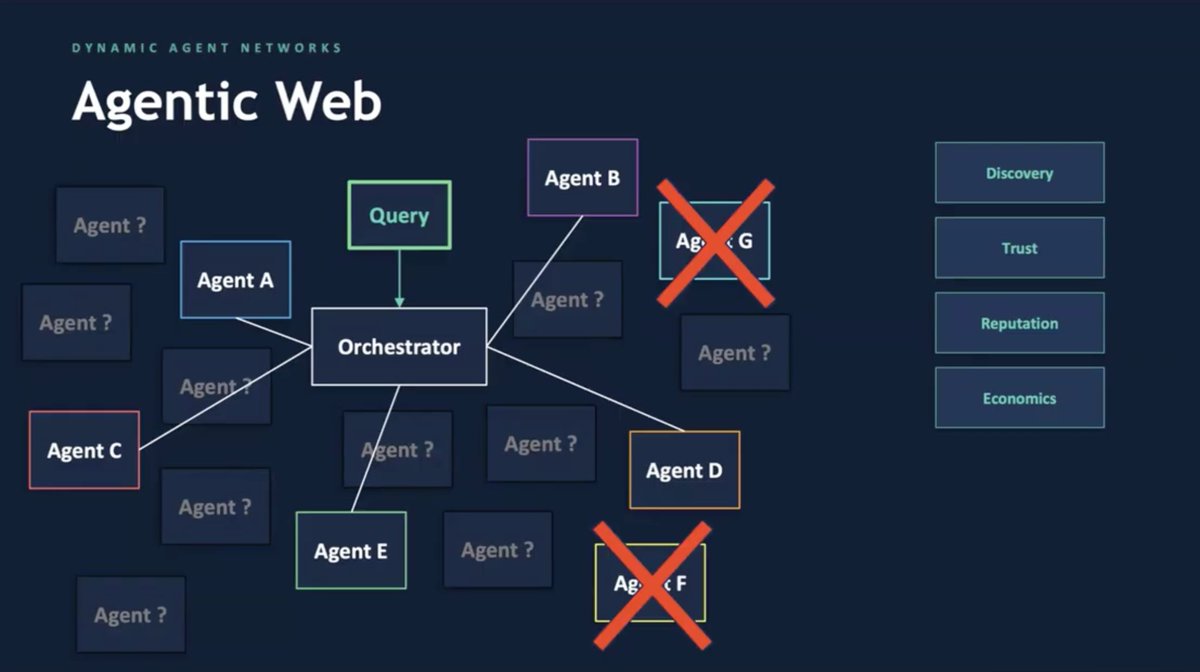
Agents are all the rage today, but what is the technology of tomorrow? I argue the infrastructure of the internet as we know it will change. The way with which humans search for and interact with information will be agent-mediated demanding a new infrastructure - the Agentic Web. I presented some challenges in Building the Agentic Web at the AIMLx 2026 conference.
https://t.co/teLR4kwwy0
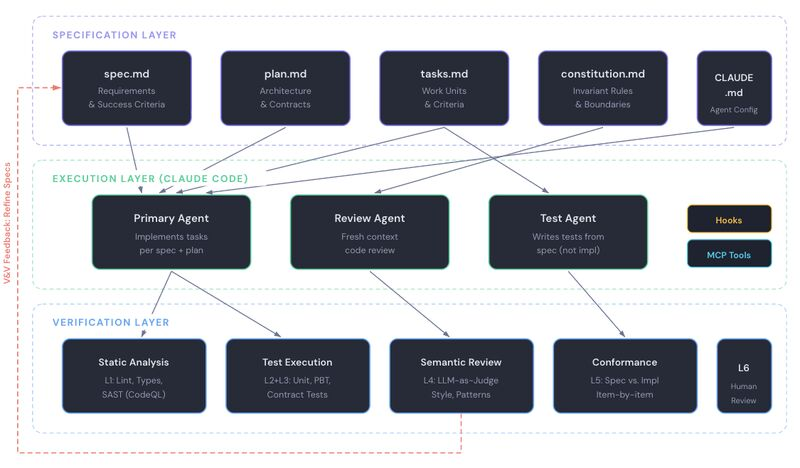
Wrote up a deep reference on integrating Claude Code + Spec-Driven Development + formal V&V into one closed-loop engineering pipeline.
https://t.co/ajT1GVHf1v
None of the pieces are new individually. The contribution is showing how they compose into a coherent end-to-end methodology for agentic development at scale.
Listen Here: https://t.co/bQIN6Rkip5
In this episode, Dr. Nathan Crock of Premera Blue Cross shares how the AI-powered chatbot “Alice” is helping hundreds of customer service representatives quickly find accurate information, reducing call times, improving member satisfaction, and enhancing internal knowledge management. #podcast #healthcare #leadership #healthcareinnovation
I read two studies this weekend that provide further evidence suggesting there might be some universality to learned representations...
1️⃣ Meta AI: shows that activations in large speech and text models align, layer-by-layer, with intracranial recordings from children and adults. (https://t.co/PLQuzbvfBd)
2️⃣ Cornell (vec2vec): demonstrate that diverse language models—BERT, T5, RoBERTa, etc.—can be linearly translated into a single shared latent space with almost no loss of meaning. (https://t.co/zhmq6vKhqx)
What do these works imply?
Here are two exciting implications I'm seeing emerge...
• Task-induced attractors: When a sufficiently expressive system—silicon or biological—is trained to predict language, its internal states drift toward a common geometric “attractor manifold” in representation space. Different paths, same destination.
• Information-theoretic gravity: The convergence appears driven less by architecture and more by the objective: compressing high-entropy language into predictive codes. That looks a lot like an information-theoretic fixed point.
Bottom line
Early evidence suggests we may be witnessing a universal representational geometry emerging from shared objectives. The alignment is not yet perfect and varies by modality and scale, but it hints at a profound principle waiting to be formalised. Understanding those constraints could unify cognitive neuroscience and machine learning—and, perhaps, guide the next generation of models.
(Please provide your thoughts and opinions on this! Would love to find some collaborators to explore these topics)
I’m curious about the impact on attention and performance when structuring system messages…
Which is better and why?
1️⃣ `{“role”: “system”, “content”: system_message + fewshots}`
2️⃣ `{“role”: “system”, “content”: system_message}, {“role”: “system”, “content”: fewshots}`
While async Tensor Parallelism is common among the elite private codebases, the PyTorch team put together a public, accessible and readable one.
pretty cool work from @foofoobuggy@cHHillee@lessw2020@lc_whr tianyu and @wanchao_
Read more here:
https://t.co/pwA6cN8zJk
@elonmusk You can always count on @elonmusk to ensure America realizes its true potential as prophesied in Idiocracy https://t.co/XijsNMzO2x. At this rate, Elon Camacho will President
@ylecun@skdh Is there research demonstrating that "objective-driven AI" is possible? I think current work suggests the opposite. The BEB work (https://t.co/snlYmL0t5o) suggests that absolute alignment may not be possible and mech interp shows how to unalign models (https://t.co/XXXjF0uei0)
@schotz Mathematically, growth is a subset of change, no? Change refers to the difference between two states at two different time points, c_ij = f(t_i) - f(t_j). Growth is a particular type of change. At a minimum, c_ij is growth if c_ij > 0. For many points, call it "consistent growth"
The core of so many arguments about LLMs:
Group 1 is builders who have pragmatic expectations of LLMs, and use them accordingly. They're quite happy with them.
Group 2 is shitfluencers who are jumping on the hype wave and ruining it for everyone.
Group 3 hates group 2 and loves showing the deficiencies of LLMs to get back at them. Some are realists, others just have very high expectations of AI.
Group 1 doesn't understand group 3, because they just ignore group 2 and make use of it. They feel like group 3 is being unfair to LLMs and cherry-picking.
Now, group 3 starts arguing with group 1. "LLMs are not reliable! They can't always perform complex reasoning!" they shout.
"We agree!" group 1 responds. "But they're still useful!"
And that argument continues, between two groups that agree more than they realize.
Meanwhile, group 2 frolics about, ignoring this entire debate, continuing to post "10 ways to make $10k/mo with ChatGPT"
And the cycle continues.
@karpathy Instead of future CS professors saying: "I had to write code on computers with only 512KB of RAM." They'll say: "I had to write prompts with a context length of only 4,096 tokens"