Announcing a significant upgrade to Agentic Document Extraction!
LandingAI's new DPT (Document Pre-trained Transformer) accurately extracts even from complex docs. For example, from large, complex tables, which is important for many finance and healthcare applications. And a new SDK makes using it require only 3 simple lines of code. Please see the video for technical details. I hope this unlocks a lot of value from the "dark data" currently stuck in PDF files, and that you'll build something cool with this!
A short story (thread) about living in the Digital Age:
We stopped subscribing to print newspapers after the COVID lockdown - most of us were reading the news on our phones anyway. Never bothered to resubscribe.
Bonus - I rediscovered the many ways in which I used newspapers, beyond the obvious:
1. As packaging material
2. For Cleaning Windows
3. As a Spill Protector for when I’m eating on the couch
4. All types of crafts and art projects
5. And of course - recycle it for $ (if you’re in the ‘developing’ world
Our take on the dwindling attention span, and its impact on learning.
TL;DW - For better or worse: We're multitasking better than ever before, and absorbing and remembering more information. Our newest digital skill - 'frontal filtering' - ensures we're not overwhelmed in the digital age.
1/n The Hippocampus-Inspired AI: HippoRAG Gives LLMs Human-Like Memory
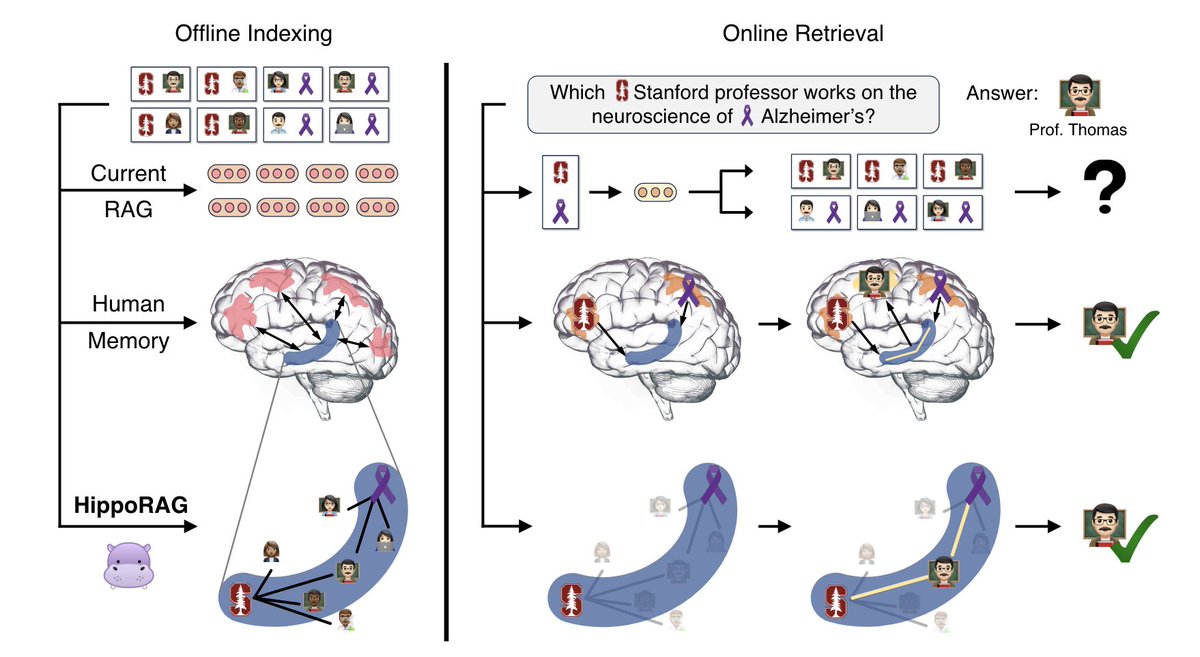
Imagine a detective piecing together clues scattered across a crime scene. Each piece of evidence, on its own, might seem insignificant. But when skillfully connected, they paint a complete picture, revealing the hidden narrative of the crime. Now, imagine if an AI could perform a similar feat, sifting through vast amounts of information and seamlessly weaving together disparate facts to solve complex problems. This is the promise of HippoRAG, a novel framework that empowers Large Language Models (LLMs) with a human-like ability for knowledge integration and multi-hop reasoning. By drawing inspiration from the intricate workings of the human brain, HippoRAG equips LLMs with the tools to go beyond simply retrieving isolated facts, allowing them to navigate a web of interconnected knowledge and unlock deeper levels of understanding.
Large Language Models (LLMs) still fall short of human intelligence in a crucial aspect: the ability to effectively integrate knowledge from multiple sources. This limitation hinders their performance on tasks requiring reasoning and knowledge synthesis, a gap that the "HippoRAG" paper aims to bridge by introducing a novel retrieval framework inspired by the associative memory capabilities of the human brain.
Current Retrieval-Augmented Generation (RAG) methods, though improving LLMs' access to external knowledge, primarily retrieve passages in isolation, failing to bridge the information gaps between them. This limitation becomes evident in tasks like "path-finding multi-hop questions," where answering requires connecting pieces of information distributed across various sources.
To address this challenge, HippoRAG draws inspiration from the hippocampal indexing theory, a well-established model of human long-term memory. This theory posits that the hippocampus plays a crucial role in forming associations between different memory units, enabling us to recall related information even when presented with partial cues.
Mirroring this biological mechanism, HippoRAG constructs a "hippocampal index," a knowledge graph (KG) representing relationships between concepts extracted from the entire corpus. Unlike traditional RAG methods that retrieve passages independently, HippoRAG can traverse this interconnected KG to access and connect information scattered across different sources. This ability is further enhanced by the use of the Personalized PageRank (PPR) algorithm, which allows HippoRAG to efficiently explore multiple relationship hops between concepts, effectively performing multi-hop reasoning in a single retrieval step.
The paper validates the effectiveness of HippoRAG through a series of experiments on multi-hop question answering tasks. Using datasets like MuSiQue and 2WikiMultiHopQA, the authors demonstrate that HippoRAG significantly outperforms existing single-step retrieval baselines and achieves comparable or even better performance than state-of-the-art multi-step retrieval methods like IRCoT, all while being significantly faster and cheaper.
When the “right technology” meets the demand of your processes and enable your workforce, magic happens 😇
Bring on the spark with JioMeet and you will be able to drive your energies, towards driving business📈
Thank you @mathurutsav GMetriXR for sharin…https://t.co/v3JrXAGOA4
Luru is a global first, and a massive opportunity for Bengaluru to drive the narrative of the future internet - the metaverse. Thanks for your support in launching this!
@GMetriXR@UnboxingBlr
Bengaluru Metaverse, which debuted at #BTS2022, is an innovation marvel. The summit's goal is to push boundaries and track down all technological prospects.
We wish to push the envelope, attract investments and jobs, and close the gap between business leaders and job seekers.
In an industry first, GMetri will host RIL’s Annual General Meeting in an immersive virtual environment. Join the #Metaverse experience live tomorrow! @mathurutsav@_sahilahuja