On-Policy Distillation is the most active new research direction being explored in RL for LLMs. Had the chance to discuss how it works with Dwarkesh and why it fits so nicely into large-scale pipelines.
Very proud of my team for achieving this important milestone. They are very talented. Within a year, they transformed the AI capabilities of a large corporation.
New devlog post from yours truly: When does fragmentation occur in the CUDA caching allocator? https://t.co/ocAdv4mjy2 -- this post is LLM authored but I heavily prompted/edited, and Natalia also helped fact check.
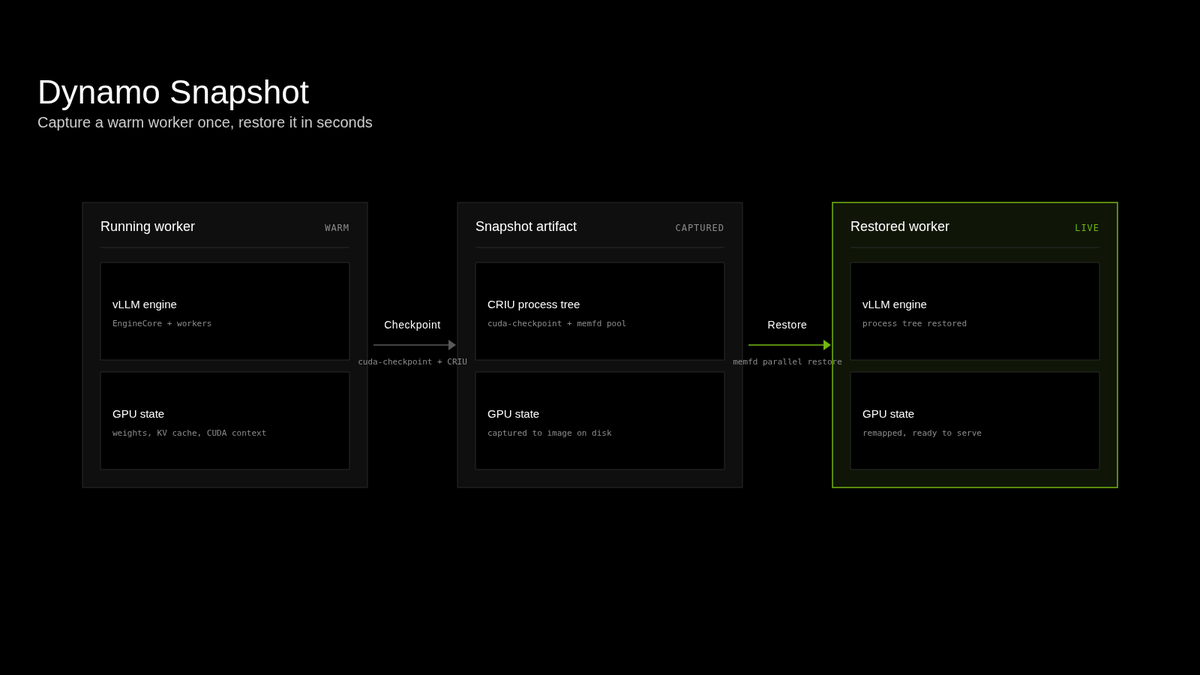
Introducing Dynamo Snapshot, our approach for fast startup for inference workloads on Kubernetes, which reduces startup time from minutes to under 5 seconds.
In production inference deployments demand fluctuates over time. Cold-starting inference workloads can take minutes, leaving idle GPUs that generate no tokens and serve no requests.
Snapshot leverages GMS to enable concurrent weight restoration over a high-speed interconnect, while using Linux native AIO and parallel memfd restoration to accelerate CRIU restore performance.
Model Optimization and Post-Training Quantization
Model quantization is an effective method to reduce VRAM usage and improve inference performance on consumer devices. By lowering computational and memory requirements while preserving model quality, quantization helps AI models run more efficiently in resource-constrained environments.
This post walks through how to use NVIDIA Model Optimizer to quantize a CLIP model in FP8 format with the post-training quantization (PTQ) method, including an example workflow exporting a PyTorch checkpoint.
Read the complete blog post:
https://t.co/yXK4uIusyZ
https://t.co/WPxi1kgW3A
Meta's experience on multi-datacenter training. They have used a PP schedule called Doraemon PP which allows integration with ZeRO-2/3.
he tested 5760 architectures at Google for a full year. the winner was the original Transformer from 2017.
Hyung Won Chung told that story at MIT with a small smile. then went to OpenAI and trained o1.
1 hour. free. by one of the few people on earth who actually moves the frontier.
meanwhile your feed is full of guys writing architecture threads who have never trained a model anyone uses. he just told MIT that 99% of AI research is theater.
your AI worldview was built by men who read his papers. badly. now you can read him directly.
you will rewatch this. save it now.
https://t.co/RYOB9y2BLp
Could it be useful to distill from a smaller model? I think, beyond distillation, we could get some signal from the loss difference across the scales.
Correctness is critical for LLM inference engines. Recently, I found TRT-LLM’s work on Hypothesis Testing Methodology to be extremely professional.
https://t.co/Qr1CLCIQ06
check out RAEv2 led by Jas. through extensive exps, we found some really intriguing behaviors showing why strong representation encoders are key for pixel decoders.
spoiler: it’s not about hillclimbing fid; new metrics like ep@fid-k/fdr^k show there’s a lot more left to explore!