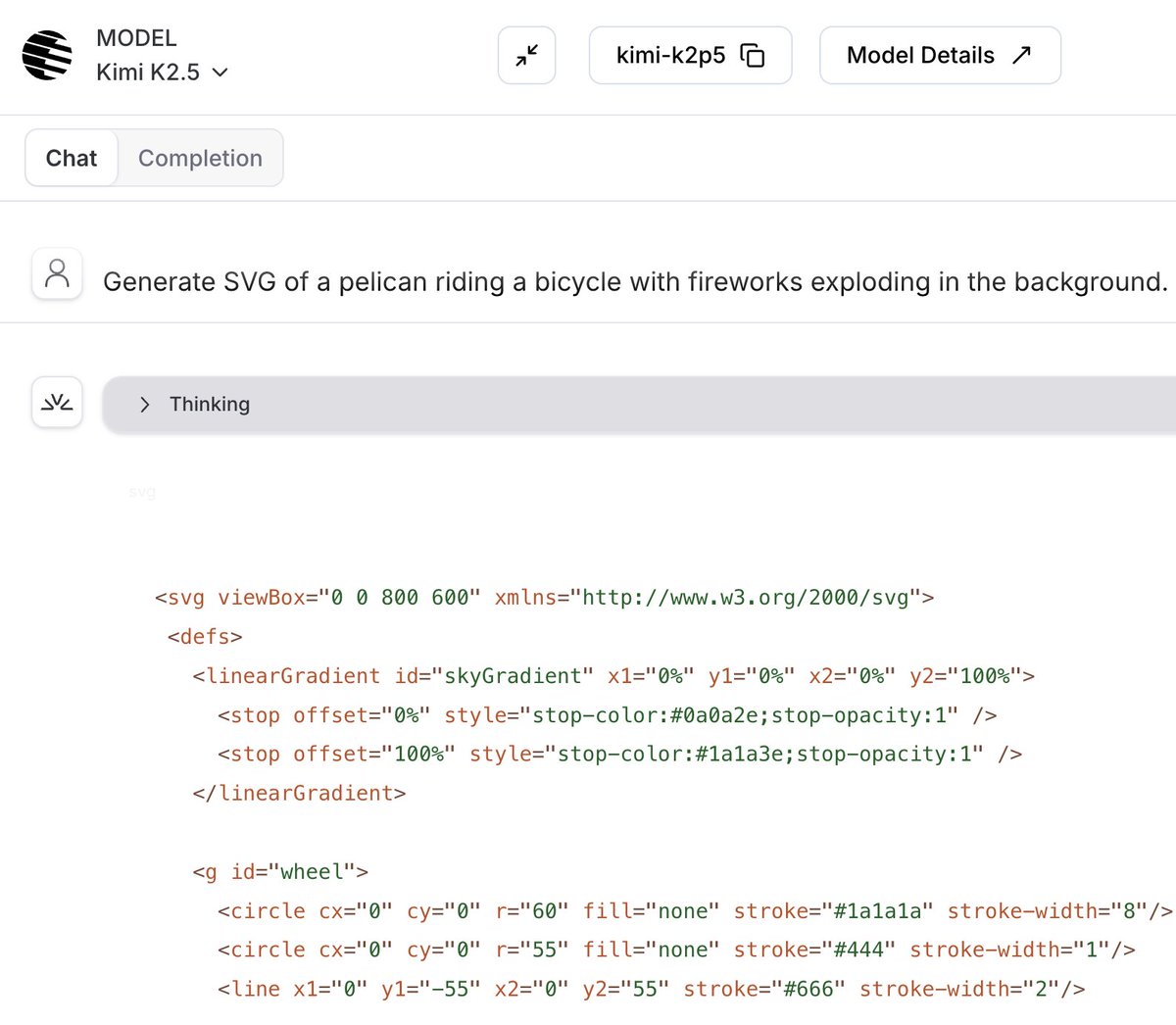
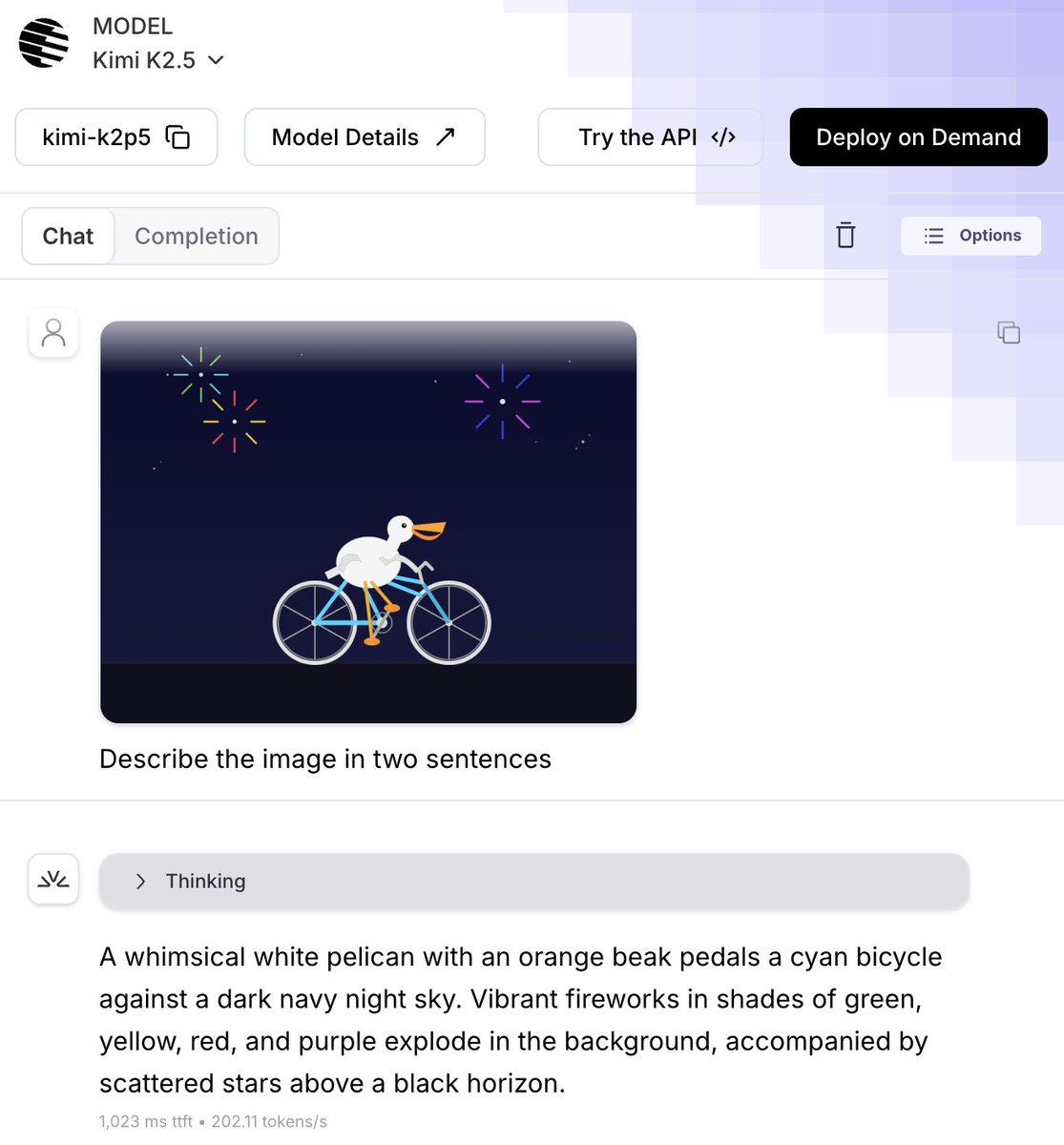
🌕 Kimi K2.5 = open SOTA reasoning + vision + 256K context + agentic coding
🏎 200+ t/s on @FireworksAI_HQ (soon even faster)
✅ Nails @simonw's "pelican on a bike" test in both directions
Try it now on Fireworks and hats off to @Kimi_Moonshot
@ID_AA_Carmack However, modern sequential/generative recommenders can optimize for reward over a session query, beyond pointwise transactions. Some interesting reads
https://t.co/4OAkGIKwZX (ByteDance)
https://t.co/CvMib0jzL7 (KwaiShou)
https://t.co/DEGsWjgpS6 (Meta)
@ID_AA_Carmack Real-time updating content corpora and changing preferences makes it difficult to move beyond per-session recs. Moreover, platforms want control to frequently update value models, which makes it difficult for policies to learn long-horizon rewards...