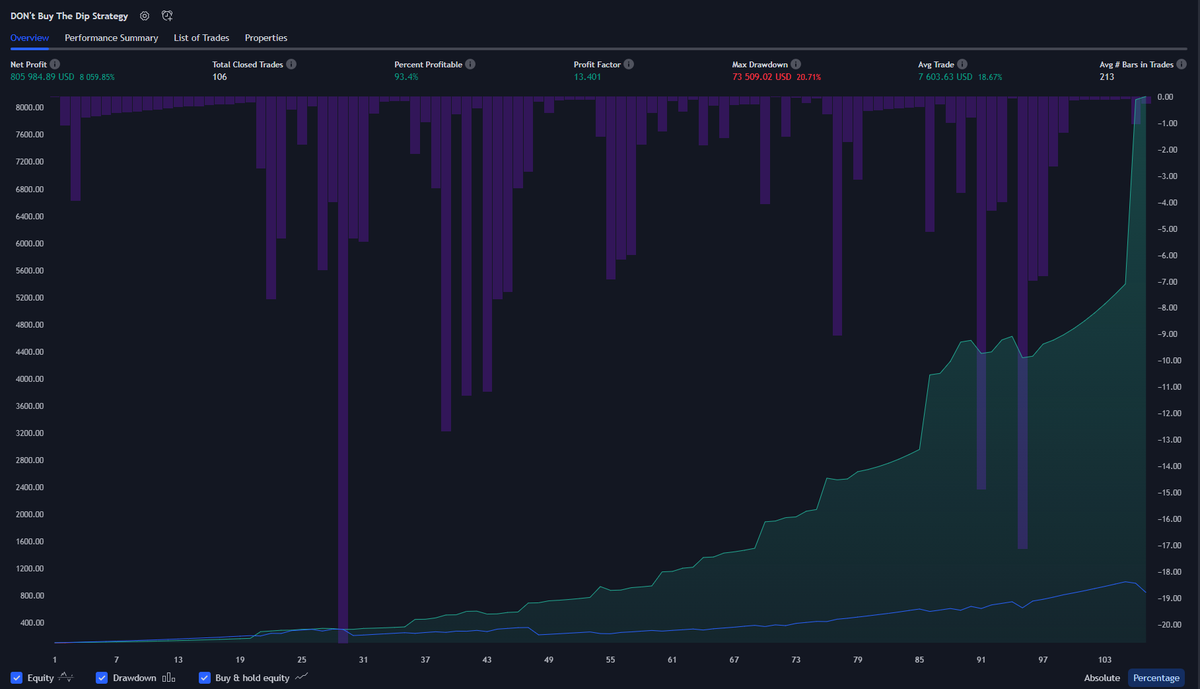
"Don't buy the dip" - my triple leveraged $SPY Long-only drawdown reductor strategy.
Completely non-technical algo, based mainly on credit stress and cross asset volatility.
It's all about proper market timing+smart money management.
Ignore the noise and work harder.
@melvynx True. Tried M3 today but I stopped after seeing it's reasoning saying something like "this feature is underspecified, but that's the user problem". I mean, WTF?
@GfI_Himmelreich What features did you find most useful to feed into such a model? Technicals? Fundamentals? A mix of those? What is the predicted value? Long signal? Future returns? Or you use it only for universe generation? TIA
@micLivs Hi. I'm testing it right now. Is there any way to see what's going on under the hood and to check if subagents are progressing?
I started a workflow but I'm seeing no progress, while Pi shows "Working...". I don't know should I wait or restart it
It feels like a contradiction you can’t quite reconcile.
On one hand, you know—intellectually—that you’re doing exactly what you’re supposed to do. The system is profitable. The backtest is robust. The rules are being followed perfectly. There’s no mistake to fix, no tweak to make. This is the process.
But emotionally, it feels like something is very wrong. There’s a steady, low-grade discomfort that sits with you all day. Not panic, not chaos—just a grinding unease. The equity curve is doing something it has always done in the past, but when it’s happening to you, in real time, it feels different. It feels personal. It feels like failure. Every loss reinforces a quiet doubt: What if this time is different?
What if the backtest was an illusion?
What if I’m just sitting here watching capital bleed for no reason?
And the hardest part is the helplessness. You’re not allowed to act.
You chose not to act. Discretion would actually feel better—at least you could do something. Cut risk. Override a trade. Reduce exposure. But the system says stay. The system says this is normal. The system says this pain is part of the edge. So you sit there, following rules that are currently producing losses, while knowing those same rules are the only reason the long-term returns exist at all. It creates a very specific kind of tension: Short-term emotional truth: This feels terrible and wrong.
Long-term statistical truth: This is exactly what must happen.
And those two truths don’t align in the moment. In fact, the better the system—the more it relies on capturing rare, outsized winners—the more uncomfortable this period tends to be. Because the edge is paid for upfront in drawdowns, whipsaws, and frustration. So the feeling is something like: quiet conviction under pressure.
You’re holding onto belief without reinforcement.
You’re executing without validation.
You’re enduring losses not because you’re wrong—but because this is the cost of being right over time. And that’s what makes it so psychologically difficult. If it felt good, it probably wouldn’t work.
@s_streichsbier Nothing new. Gemini 3.1 often believes it is Sonnet 3.7. They all train on one another's outputs, and this is not limited to Chinese labs.
@scaling01 Except it is most likely just a marketing gimmick, and nobody saw it in real life. Also post-trainig for security tasks does not mean general intelligence
@luckythehusky The last time I tried after I installed OMO it took something like 12 GB of memory to handle sub 200K token session. Is it any better now?
@RhysSullivan Not in Codex. You can change reasoning effort multiple times per session and it does not affect the cache as long as it is the same model. So, no mixing of 5.4 (mini) with 5.5
@Amank1412 You are not alone. While I'm not sure about Opus, there's definitely something going on with GPT-5.5 this week. It still sounds reasonable, but the depth of thought has significantly worsened.
@Penny_Lane_BBM Earlier this year, NQ had multiple 100-handle, 5-minute bars per session, mostly random oscillations during periods of poor liquidity. Did you trade during that period? How did you control your risk? 200-handle-wide stops? More?